本地开发模式: 开发、调试mapreduce代码
参考资料
idea中调试hadoop mapreduce程序(windows)
IDEA 调试 Hadoop程序
本地hadoop环境支持
2.解压
3.配置环境变量
HADOOP_HOME:D:\hadoop-3.2.0
HADOOP_BIN_PATH:%HADOOP_HOME%\bin
HADOOP_PREFIX:%HADOOP_HOME%
在Path后面加上%HADOOP_HOME%\bin;%HADOOP_HOME%\sbin;
4.下载安装额外的win支持,复制到D:
\hadoop-3.2.0\bin下
winutils.exe:
解决报错 java.io.IOException: Could not locate executable D:\hadoop-3.2.0\bin\winutils.exe in the Hadoop binaries.
hadoop.dll:
解决报错 Exception in thread "main" java.lang.UnsatisfiedLinkError: org.apache.hadoop.io.nativeio.NativeIO$Windows.access0(Ljava/lang/String;I)Z
5.重启idea
测试Demo
1.新建maven工程hadoop-demo
2.添加pom依赖
<!-- hadoop-client依赖 -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.2.0</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.10</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.30</version>
</dependency>
3.resource/ 添加日志配置log4j.properties
log4j.rootLogger=INFO, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spring.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
4.WordCountJob.java
public class WordCountJob {
/**
* 创建自定义mapper类
*/
public static class MyMapper extends Mapper<LongWritable,Text,Text,LongWritable>{
/**
* 需要实现map函数
* 这个map函数就是可以接收k1,v1, 产生k2,v2
* @param k1
* @param v1
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void map(LongWritable k1, Text v1, Context context)
throws IOException, InterruptedException {
// k1代表的是每一行的行首偏移量,v1代表的是每一行内容
// 对获取到的每一行数据进行切割,把单词切割出来
String[] words = v1.toString().split(" ");
// 迭代切割出来的单词数据
for (String word:words) {
// 把迭代出来的单词封装成<k2,v2>的形式
Text k2 = new Text(word);
LongWritable v2 = new LongWritable(1L);
System.out.println("k2:"+word+"...v2:1");
// 把<k2,v2>写出去
context.write(k2,v2);
}
}
}
/**
* 创建自定义的reducer类
*/
public static class MyReducer extends Reducer<Text,LongWritable,Text,LongWritable>{
/**
* 针对v2s的数据进行累加求和 并且最终把数据转化为k3,v3写出去
* @param k2
* @param v2s
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void reduce(Text k2, Iterable<LongWritable> v2s, Context context)
throws IOException, InterruptedException {
// 创建一个sum变量,保存v2s的和
long sum = 0L;
for (LongWritable v2 : v2s) {
sum += v2.get();
}
// 组装k3,v3
Text k3 = k2;
LongWritable v3 = new LongWritable(sum);
System.out.println("k3:"+k3.toString()+".....v3:"+sum);
// 把结果写出去
context.write(k3,v3);
}
}
/**
* 组装job=map+reduce
* @param args
*/
public static void main(String[] args) {
try {
if(args.length!=2){
// 如果传递的参数不够,程序直接退出
System.exit(100);
}
// job需要的配置参数
Configuration conf = new Configuration();
//设置hdfs的通讯地址, 本地联调时指明hdfs和yarn
conf.set("fs.defaultFS", "hdfs://192.168.1.196");
//设置RN的主机, 本地联调时指明hdfs和yarn
conf.set("yarn.resourcemanager.hostname", "192.168.1.197");
// 创建一个job
Job job = Job.getInstance(conf);
// 注意:这一行必须设置,否则在集群中执行的是找不到WordCountJob这个类
job.setJarByClass(WordCountJob.class);
// 指定输入路径(可以是文件,也可以是目录)
FileInputFormat.setInputPaths(job,new Path(args[0]));
// 指定输出路径(只能指定一个不存在的目录)
FileOutputFormat.setOutputPath(job,new Path(args[1]));
// 指定map相关的代码
job.setMapperClass(MyMapper.class);
// 指定k2的类型
job.setMapOutputKeyClass(Text.class);
// 指定v2的类型
job.setMapOutputValueClass(LongWritable.class);
// 指定reduce相关的代码
job.setReducerClass(MyReducer.class);
// 指定k3的类型
job.setOutputKeyClass(Text.class);
// 指定v3的类型
job.setOutputValueClass(LongWritable.class);
// 提交job
job.waitForCompletion(true);
}catch (Exception e){
e.printStackTrace();
}
}
}
5.启动参数program argumets指定远端hdfs输入、输出路径,run运行
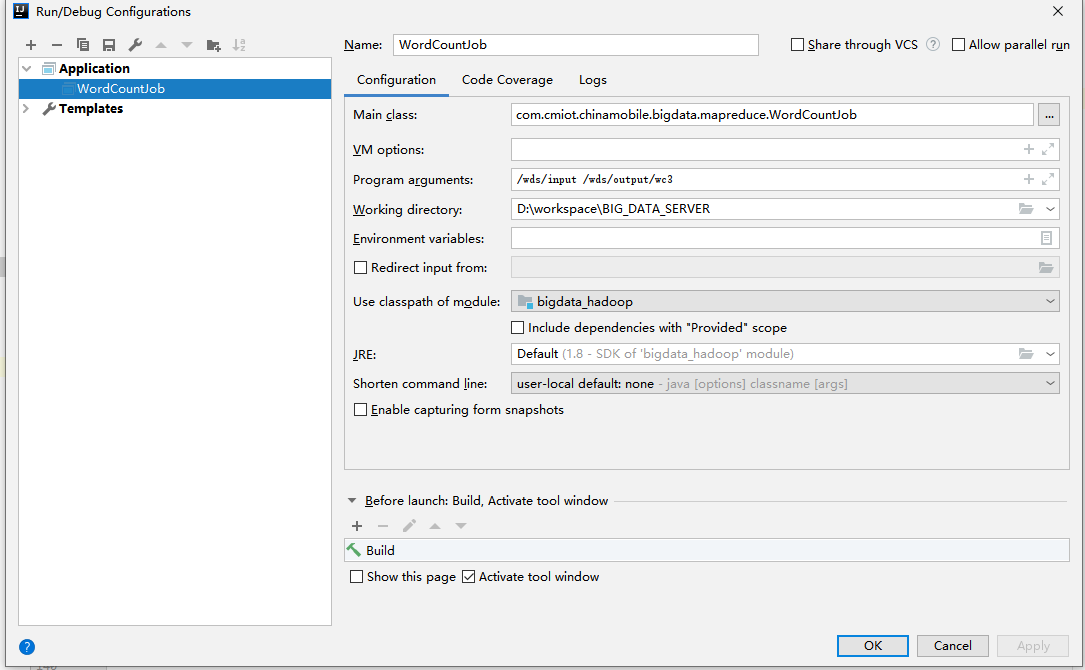
6.使用本地文件夹作为输入输出路径,不连接集群环境hdfs
a.组装job代码里注释掉配置的远端hdfs配置
//conf.set("fs.defaultFS", "hdfs://192.168.1.196");
//conf.set("yarn.resourcemanager.hostname", "192.168.1.197");
b.program argumets添加本地路径参数,run运行
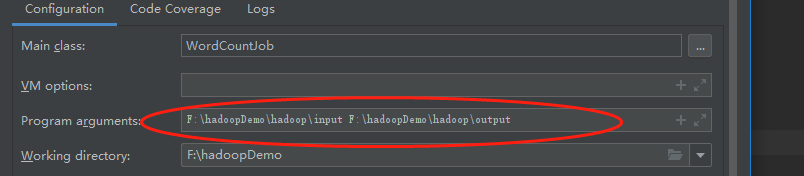
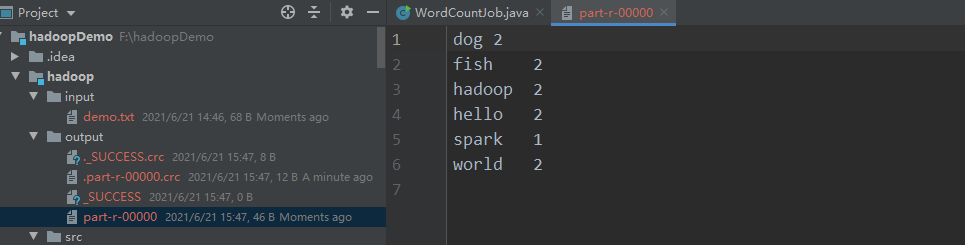
问题记录
- 教程:http://kaimingwan.com/post/da-shu-ju/ideazhong-diao-shi-hadoop-mapreducecheng-xu-windows
- 问题集合:https://blog.csdn.net/congcong68/article/details/42043093
Post Directory
扫码关注公众号:暂无公众号
发送 290992
![]()
即可立即永久解锁本站全部文章