参考资料
- 快速入门Hadoop3.0大数据处理-【慕课网】
- 3小时开启大数据之门-【慕课网】
- 大数据开发工程师-【慕课网】
- 尚硅谷-大数据
- 尚学堂-大数据
- 官网:https://hadoop.apache.org
- Hadoop文档: http://hadoop.apache.org/docs/r1.0.4/cn/index.html
- 《HADOOP权威指南》
阶段一:走进大数据Hadoop
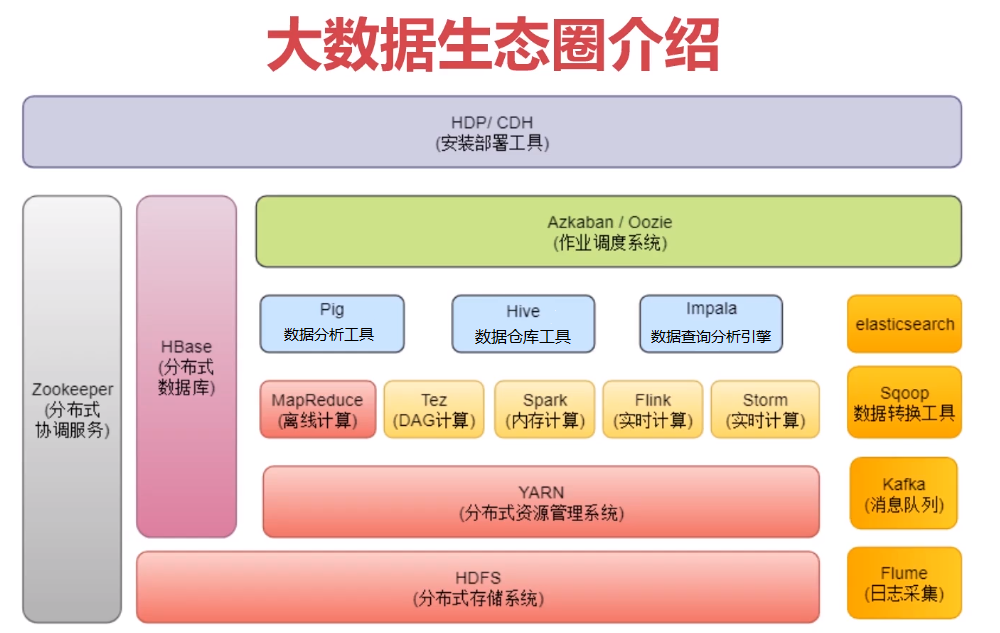
第1周 学好大数据先攻克Linux
1、掌握Linux虚拟机的安装和配置
2、使用ScecureCRT连接Linux虚拟机
3、掌握Linux中常见高级命令(vi、wc、sort、date、jps、kill等命令)的使用
4、掌握Linux中三剑客(grep、sed、awk)的常见用法
5、掌握Linux的高级配置(ip、hostname、防火墙)
6、掌握Shell脚本的开发
7、掌握Shell中变量、循环和判断的使用
8、掌握Shell中的扩展内容
9、掌握Linux中crontab定时器的使用
10、了解认识什么是大数据
- 百度实时路况
- 推荐(购物、新闻、关注)
11、大数据产生的背景
- 海量数据的产生
- 云计算的兴起
12、大数据的4V特征
- Volume(大量):
- Velocity(高速):
- Variety(多样): 结构型的数据,也可能是非结构行的文本,图片,视频,语音,日志,邮件等
- Value(低价值密度):
13、大数据的行业应用
第2周 大数据起源之初识Hadoop
1、什么是Hadoop
PB级别海量数据存储和计算的平台;
Hadoop是由java语言编写的,在分布式服务器集群上存储海量数据并运行分布式分析应用的开源框架,其核心部件是HDFS与MapReduce。
1-2、Hadoop能干什么
Hadoop到底是干什么用的?
https://blog.csdn.net/qq_32649581/article/details/82892861
Hadoop是专为离线和大规模数据分析而设计的,并不适合那种对几个记录随机读写的在线事务处理模式。
- 大数据存储:分布式存储
- 日志处理:擅长日志分析 (实际应用:Flume+Logstash+Kafka+Spark Streaming进行实时日志处理分析)
- ETL:数据抽取到oracle、mysql、DB2、mongdb及主流数据库
- 机器学习: 比如Apache Mahout项目
- 搜索引擎:Hadoop + lucene实现
- 数据挖掘:目前比较流行的广告推荐,个性化广告推荐
2、Hadoop发行版介绍:
- 官方版本:Apache hadoop,开源,集群、安装维护较麻烦
- CDH版本:Cloudera hadoop,商用版本,部分功能开源,使用cloudera Manager 安装维护方便
- HDP版本:HortonWorks hadoop,开源,使用Ambari安装维护方便
3、Hadoop版本演变历史
1.X -> 2.X -> 3.X
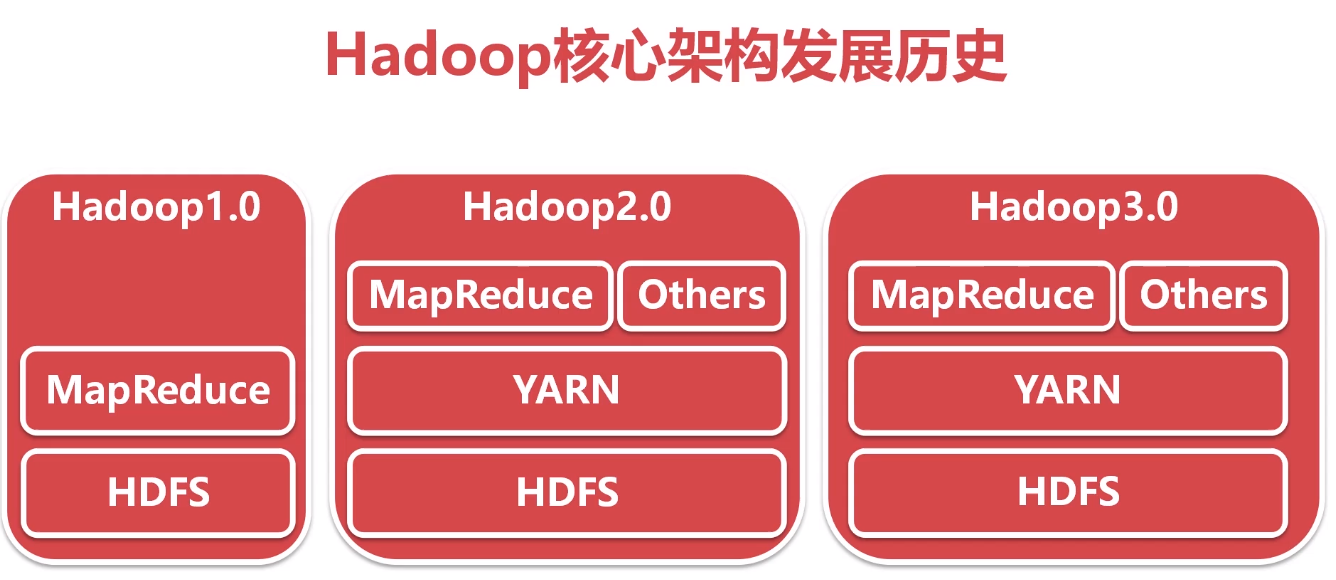
4、Hadoop3.x的细节优化
- Java改为支持8及以上
- 多重服务默认端口变更
- MR任务级本地优化
- HDFS支持纠删码
- HDFS支持多NameNode
5、Hadoop三大核心组件介绍
- HDFS: (海量数据)分布式数据存储, HDFS理解为一个分布式的,有冗余备份的,可以动态扩展的用来存储大规模数据的大硬盘。
- MapReduce: (海量数据)分布式计算, MapReduce理解成为一个计算引擎,按照MapReduce的规则编写Map计算/Reduce计算的程序,可以完成计算任务。
- Yarn: 集群资源管理, 能监控服务器的资源使用,分配跟踪程序运行;
6、分布(3台虚拟机)集群安装部署
1).基础环境准备
ip设置
//配置静态(固定)ip
1.虚拟机网卡设置:NAT
2.打开这个文件,修改里面的一些参数就行了。
/etc/sysconfig/network-scripts/ifcfg-ens33
BOOTPROTO="static"
//取值:vmware编辑-虚拟网络编辑器-NAT-配置
IPADDR=192.168.145.128
GATEWAY=192.168.145.2
DNS1=192.168.145.2
3.重启网卡服务:service network restart
主机名hostname设置(临时+永久)
[root@bigdata128 hadoop]# hostname bigdata128
[root@bigdata128 hadoop]# vi /etc/hostname,填写 bigdata128
hosts文件修改(ip和主机名的映射关系,3台主机都要添加)
[root@bigdata128 hadoop]# vi /etc/hosts
ip1 hostname1
ip2 hostname2
ip3 hostname3
#生效
service network restart
或者
/etc/init.d/network restart
关闭防火墙(临时+永久)
关闭防火墙 systemctl stop firewalld
关闭开机启动项:systemctl disable firewalld
ssh免密登录
[root@bigdata128 hadoop]# ssh-keygen -t rsa //一路回车
[root@bigdata128 hadoop]# cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
//验证
$ ssh bigdata128
//配置免密登录从节点
$ ssh-copy-id -i bigdata129
$ ssh-copy-id -i bigdata130
jdk安装:
解压、配置环境变量、生效
克隆出129、130
1.vm128-右键-管理-克隆-当前状态-创建完整克隆
2.克隆完成后修改配置
ipa ddr 查看ip、mac地址
...
# link/ether 00:0c:29:b0:26:ab brd ff:ff:ff:ff:ff:ff
# inet 192.168.145.130/24 brd 192.168.145.255 scope global dynamic eno16777736
vi /etc/sysconfig/network-scripts/idcfg-eno16777736
HWADDR=00:0c:29:b0:26:ab
IPADDR=192.168.145.130
3.service network restart
集群节点之间时间同步
yum install -y ntpdate
ntpdate -u ntp.sjtu.edu.cn
// 建议把这个同步时间的操作添加到linux的crontab定时器中,每分钟执行一次
vi /etc/crontab
* * * * * root /usr/sbin/ntpdate -u ntp.sjtu.edu.cn
2).下载hadoop: https://hadoop.apache.org/releases.html
3).上传、解压
4).配置修改
// hadoop-env.sh :在文件末尾增加环境变量信息
cd hadoop-3.2.0/etc/hadoop/
vi hadoop-env.sh
export JAVA_HOME=/opt/jdk1.8.0_171
export HADOOP_LOG_DIR=/data/hadoop_repo/logs/hadoop
// core-site.xml :注意fs.defaultFS属性中的主机名需要和主节点的主机名保持一致
vi /data/soft/hadoop-3.2.0/etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://bigdata128:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/data/hadoop_repo</value>
</property>
</configuration>
// hdfs-site.xml :把hdfs中文件副本的数量设置为2,最多为2,因为现在集群中有两个从节点,还有secondaryNamenode进程所在的节点信息
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>bigdata128:50090</value>
</property>
</configuration>
// mapred-site.xml :设置mapreduce使用的资源调度框架
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
// yarn-site.xml :设置yarn上支持运行的服务和环境变量白名单
针对分布式集群在这个配置文件中还需要设置resourcemanager的hostname,否则nodemanager找不到resourcemanager节点。
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>bigdata128</value>
</property>
</configuration>
// workers:
vi workers
bigdata129
bigdata130
5).shell脚本修改
修改 start-dfs.sh , stop-dfs.sh 这两个脚本文件,,在文件前面增加如下内容
cd /data/soft/hadoop-3.2.0/sbin
[root@bigdata128 sbin]# vi start-dfs.sh
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
[root@bigdata128 sbin]# vi stop-dfs.sh
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
修改 start-yarn.sh , stop-yarn.sh 这两个脚本文件,在文件前面增加如下内容
vi start-yarn.sh
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
[root@bigdata128 sbin]# vi stop-yarn.sh
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
6).把bigdata128节点上将修改好配置的安装包拷贝到其他两个从节点
[root@bigdata128 sbin]# cd /data/soft/
[root@bigdata128 soft]# scp -rq hadoop-3.2.0 bigdata129:/data/soft/
[root@bigdata128 soft]# scp -rq hadoop-3.2.0 bigdata130:/data/soft/
7).在bigdata128节点上格式化HDFS
[root@bigdata128 soft]# cd /data/soft/hadoop-3.2.0
[root@bigdata128 hadoop-3.2.0]# bin/hdfs namenode -format
如果在后面的日志信息中能看到这一行,则说明namenode格式化成功。
common.Storage: Storage directory /data/hadoop_repo/dfs/name has been successf
失败的话:修改配置,同步修改从节点配置,再执行一次
成功后,想重复格式化:清空/data/hadoop_repo目录,再格式化
8).启动集群,在bigdata128节点上执行下面命令
[root@bigdata128 hadoop-3.2.0]# sbin/start-all.sh
9).验证集群: 查看进程、浏览器访问
在bigdata128、bigdata129、bigdata130节点执行
[root@bigdata128 hadoop-3.2.0]# jps
192.168.145.128:9870
192.168.145.128:8088
10).停止集群
在bigdata128节点上执行停止命令
[root@bigdata128 hadoop-3.2.0]# sbin/stop-all.sh
问题记录
hadoop从节点jsp没有datanode进程?
查看从节点日志,是不是报错了,然后根据报错信息修改配置
附:Hadoop的官网文档:
https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/SingleCluster.html
8、Hadoop的客户端节点(相同配置即可)
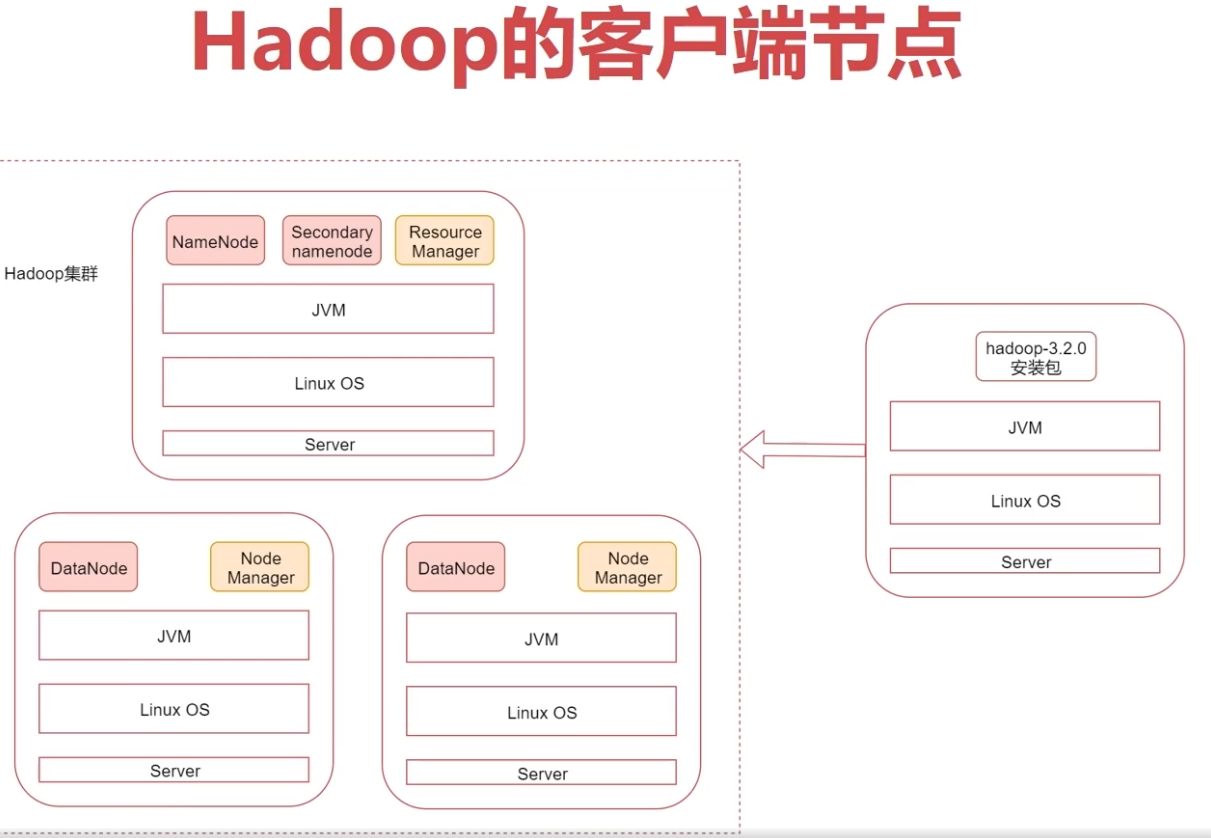
直接操作集群节点是不安全的,所以一般在业务机上安装hadoop客户端,再业务机上操作hadoop集群
建议在业务机器上安装Hadoop,只需要保证业务机器上的Hadoop的配置和集群中的配置保持一致即 可,这样就可以在业务机器上操作Hadoop集群了,此机器就称为是Hadoop的客户端节点
Hadoop的客户端节点可能会有多个,理论上是我们想要在哪台机器上操作hadoop集群就可以把这台机 器配置为hadoop集群的客户端节点。
第3周 分布式存储HDFS(hadoop distributed file system)
1、Hadoop中的分布式存储架构 – 生活场景引入:”小明租房”案例一步一步引入
HDFS是一种允许文件通过网络在多台主机上分享的文件系统,可以让多机器上多用户分享文件和存储空间;
- 通透性
- 容错性
- 不适合存储小文件
2、HDFS的Shell介绍
使用格式: bin/hdfs dfs -xxx schema://authority/ path
- HDFS的schema是hdfs,
- authority是NameNode的节点ip:port,
- path是我们要操作的路径信息
3、HDFS的常见Shell操作
hdfs命令配置环境变量:
vi /etc/profile
export HADOOP_HOME=/data/soft/hadoop-3.2.0
export PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$PATH
source /etc/profile
- -ls: 查询指定路径信息: hdfs dfs -ls hdfs://bigdata128:9000/
- -mkdir [-p]:创建文件夹: hdfs dfs -mkdir hdfs://bigdata128:9000/test
- -put: 从本地.上传文件: hdfs dfs -put readme.txt hdfs://bigdata128:9000/test
- -get: 下载文件到本地: hdfs dfs -get /test/readme.txt readme.txt.bak
- -cat: 查看HDFS文件内容: hdfs dfs -cat /test/readme.txt
- -rm [-r]: 删除文件/文件夹
- -p 递归创建多级目录,需要指定-p参数: hdfs dfs -mkdir -p /abc/xyz
- -R 递归显示所有目录的信息: hdfs dfs -ls -R /
5、Java代码操作HDFS
1.添加依赖
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.2.0</version>
</dependency>
2.上传:执行代码,发现报错,提示权限拒绝,说明windows中的这个用户没有权限向HDFS中写入数据
解决办法有两个
第一种:去掉hdfs的用户权限检验机制,通过在hdfs-site.xml中配置dfs.permissions.enabled为false即可
第二种:把代码打包到linux中执行
/**
* Java代码操作HDFS
* 文件操作:上传文件、下载文件、删除文件
* Created by
*/
public class HdfsOp {
public static void main(String[] args) throws Exception{
//创建一个配置对象
Configuration conf = new Configuration();
//指定HDFS的地址
conf.set("fs.defaultFS","hdfs://bigdata128:9000");
//获取操作HDFS的对象
FileSystem fileSystem = FileSystem.get(conf);
put(fileSystem);
}
/**
* 文件上传
* @param fileSystem
* @throws IOException
*/
private static void put(FileSystem fileSystem) throws IOException {
//获取HDFS文件系统的输出流
FSDataOutputStream fos = fileSystem.create(new Path("/user.txt"));
//获取本地文件的输入流
FileInputStream fis = new FileInputStream("D:\\user.txt");
//上传文件:通过工具类把输入流拷贝到输出流里面,实现本地文件上传到HDFS
IOUtils.copyBytes(fis,fos,1024,true);
}
}
/**
* 下载文件
* @param fileSystem
* @throws IOException
*/
private static void get(FileSystem fileSystem) throws IOException{
//获取HDFS文件系统的输入流
FSDataInputStream fis = fileSystem.open(new Path("/README.txt"));
//获取本地文件的输出流
FileOutputStream fos = new FileOutputStream("D:\\README.txt");
//下载文件
IOUtils.copyBytes(fis,fos,1024,true);
}
/**
* 删除文件
* @param fileSystem
* @throws IOException
*/
private static void delete(FileSystem fileSystem) throws IOException{
//删除文件,目录也可以删除
//如果要递归删除目录,则第二个参数需要设置为true
//如果是删除文件或者空目录,第二个参数会被忽略
boolean flag = fileSystem.delete(new Path("/LICENSE.txt"),true);
if(flag){
System.out.println("删除成功!");
}else{
System.out.println("删除失败!");
}
}
6、HDFS的高级Shell命令
7、HDFS读数据过程分析
8、HDFS写数据过程分析
9、HDFS写数据源码分析
第4周 HDFS核心进程剖析
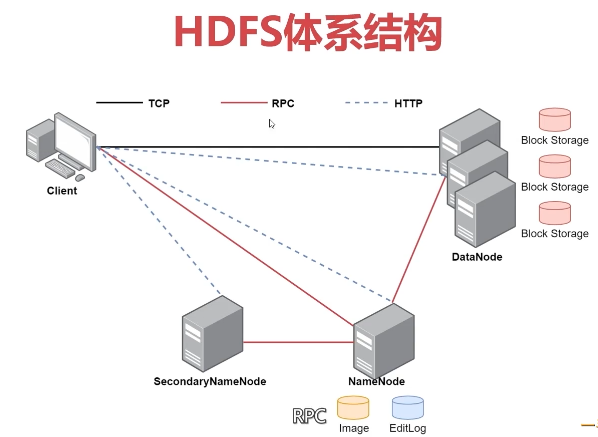
HDFS支持主从结构:
- 主节点支持多个NameNode;从节点支持多个DataNode
- NameNode负责接受读写请求、维护文件系统目录树结构;DataNode负责存储数据
1、NameNode介绍
主要包含以下文件:
- fsimage(内存数据快照,元数据文件)、
- edits(修改操作记录)、
- seed_txid(事务id即edits的id)、
- version(版本信息)
维护两份关系
- 第一份关系file与block list关系,存储在fsimage、edits中
- 第二份关系dataNode和block关系,dataNode启动时,会把当前节点信息+节点上block信息 上报给NameNode
3、SecondaryNameNode(主节点上)介绍
- 主要负责把edits文件的内容合并到fsimage中
- 这个合并操作成为checkpoint,合并时会对edits内容进行转换,生成新的内容保存到fsimage中
注意:在nameNode的HA架构中是没有SecondaryNameNode进程的,这时文件合并操作时由standby NameNode负责实现的
4、DataNode(从节点上)介绍
- 提供真实文件数据存储服务
- hdfs会按照固定大小顺序对文件进行编号,划分的每一块block,默认大小128M
-
如果一个数据块大小小于128M,不会占用整个数据block
- Replication:多副本机制,HDFS默认副本数量为3
- 通过dfs.replication属性控制
5、HDFS的回收站
- HDFS为每个用户创建一个回收站目录:/user/用户名/.Trash/
- 回收站中的数据都会有一个默认保存周期,过期未恢复则会被HDFS自动彻底删除
注意:HDFS的回收站默认是没有开启的,需要修改core-site.xml中的 fs.trash.interval 属性
6、HDFS的安全模式详解
集群刚启动时HDFS会进入安全模式,此时无法执行写操作
- 查看安全模式:hdfs dfsadmin -safemode get
- 离开安全模式:hdfs dfsadmin -safemode leave
7、实战:定时上传数据至HDFS
需求分析:
在实际工作中会有定时上传数据到HDFS的需求,我们有一个web项目每天都会产生日志文件,日
志文件的格式为access_2020_01_01.log这种格式的,每天产生一个,我们需要每天凌晨将昨天生
成的日志文件上传至HDFS上,按天分目录存储,HDFS上的目录格式为20200101
开发一个shell脚本,方便定时调度执行
日志目录:/data/log
脚本目录:/data/shell
// uploadLogData.sh
# 第四步:要考虑到脚本重跑,补数据的情况 获取昨天日期字符串
yesterday=$1
if [ "$yesterday" = "" ]
then
yesterday=`date +%Y_%m_%d --date="1 days ago"`
fi
# 第一步:拼接日志文件路径信息
logPath=/data/log/access_${yesterday}.log
# 将日期字符串中的_去掉
hdfsPath=/log/${yesterday//_/}
# 第二步:在hdfs上创建目录
hdfs dfs -mkdir -p ${hdfsPath}
# 第三步:将数据上传到hdfs的指定目录中
hdfs dfs -put ${logPath} ${hdfsPath}
第五步:配置crontab任务
vi /etc/crontab
0 1 * * * root sh /data/shell/uploadLogData.sh >> /data/shell/uploadLogData.log
第六步:手动执行任务:
sh -x uploadLogData.sh
sh -x uploadLogData.sh 2020_01_01 //补传数据
8、HDFS的高可用机制分析
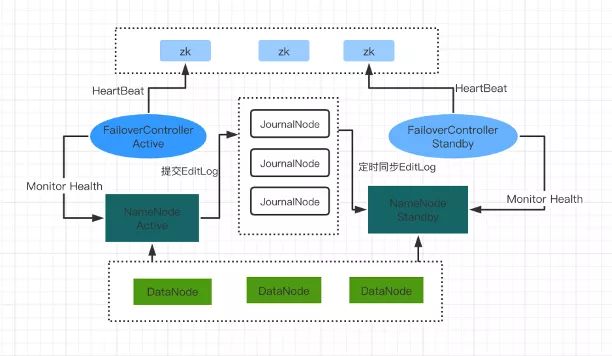
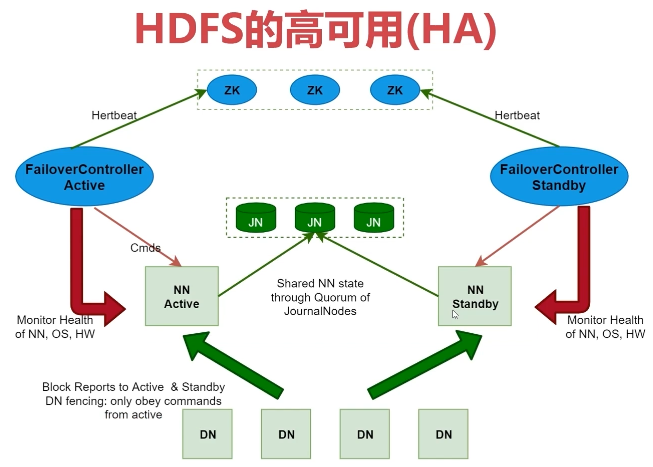
- HDFS的HA,表示一个集群中存在多个NameNode,只有一个NameNode是 Active 状态,其它的是 Standby 状态
- ActiveNameNode(ANN)负责所有客户端的操作,StandbyNameNode(SNN)用来同步ANN的状态信息,以提供快速故障恢复能力
- 使用HA的时候,不能启动SecondaryNameNode,会出错
9.HDFS的高扩展
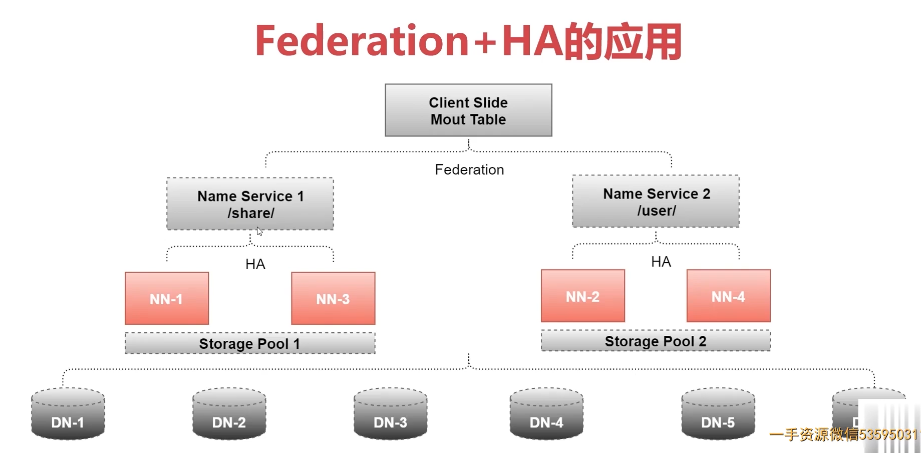
Federation可解决单一命名空间的一些问题,提供以下特性,使用多个NameNode,每个NameNode负责一个命令空间
- HDFS集群扩展性 :多个NameNode分管一部分目录,使得一个集群可以扩展到更多节点,不再因内存的限制制约文件存储数目。
- 性能更高效 :多个NameNode管理不同的数据,且同时对外提供服务,将为用户提供更高的读写吞吐率。
- 良好的隔离性: 用户可根据需要将不同业务数据交由不同NameNode管理,这样不同业务之间影响很小
第5周 分布式(离线)计算MapReduce
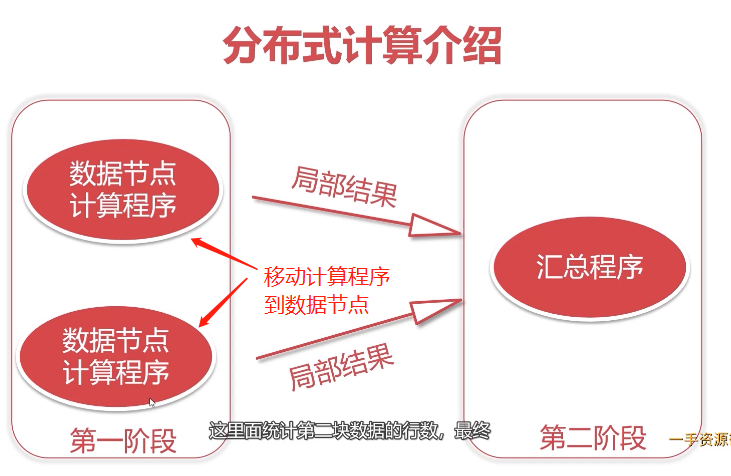
1、MapReduce介绍
MapReduce是一个分布式计算模型,主要负责海量数据计算,主要有两个阶段组成:map和reduce
- Map阶段是一个独立程序,会在很多节点同时执行,每个节点处理一部分数据
- Reduce阶段也是独立程序,可以理解为一个单独的聚合程序
- 框架有默认实现,用户只需要覆盖map()和reduce()两个函数,即可实现分布式计算
2、MapReduce执行原理
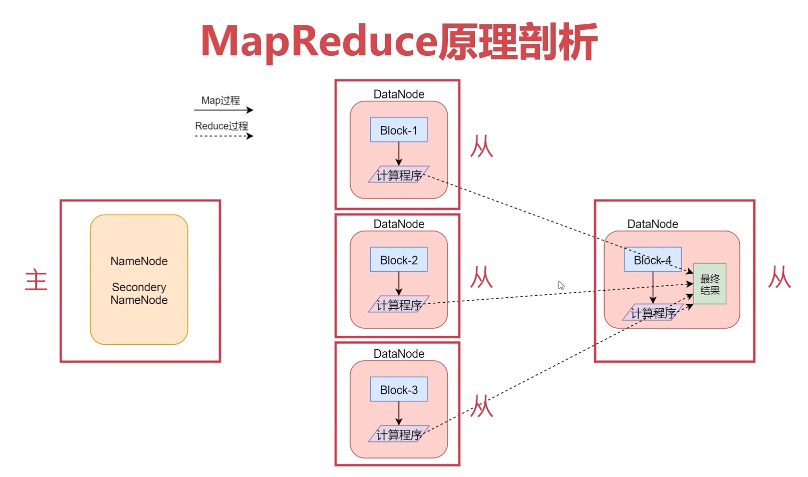
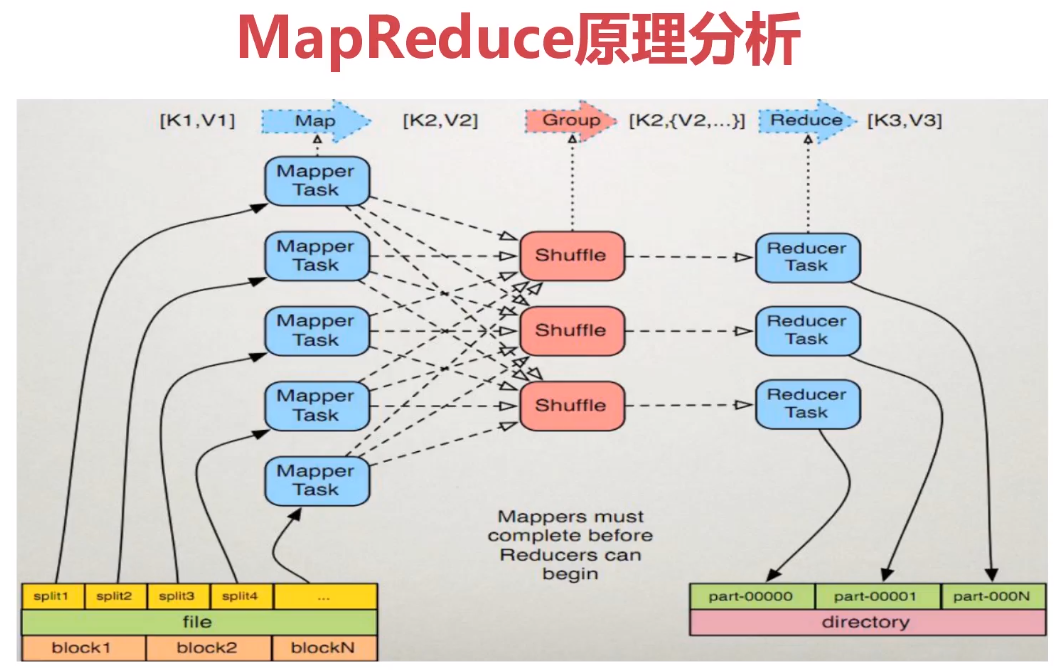
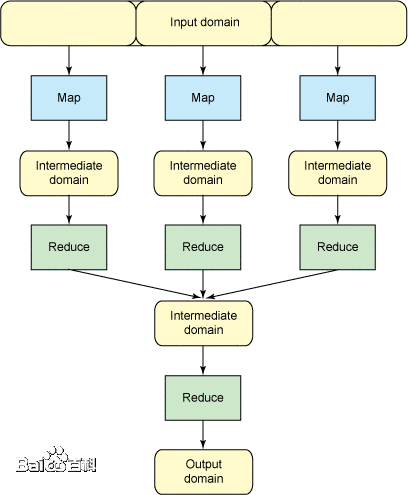
2-2、shuffle过程分析
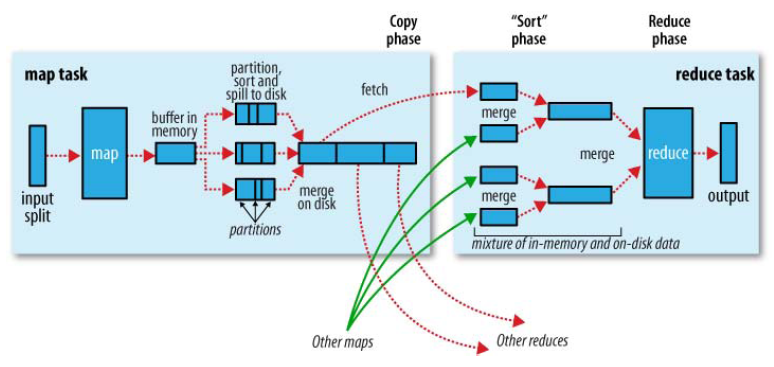
框架对多个map任务的输出,按照不同的分区,通过网络copy到不同的reduce节点,这个过程称作shuffle
3、实战:WordCount案例图解
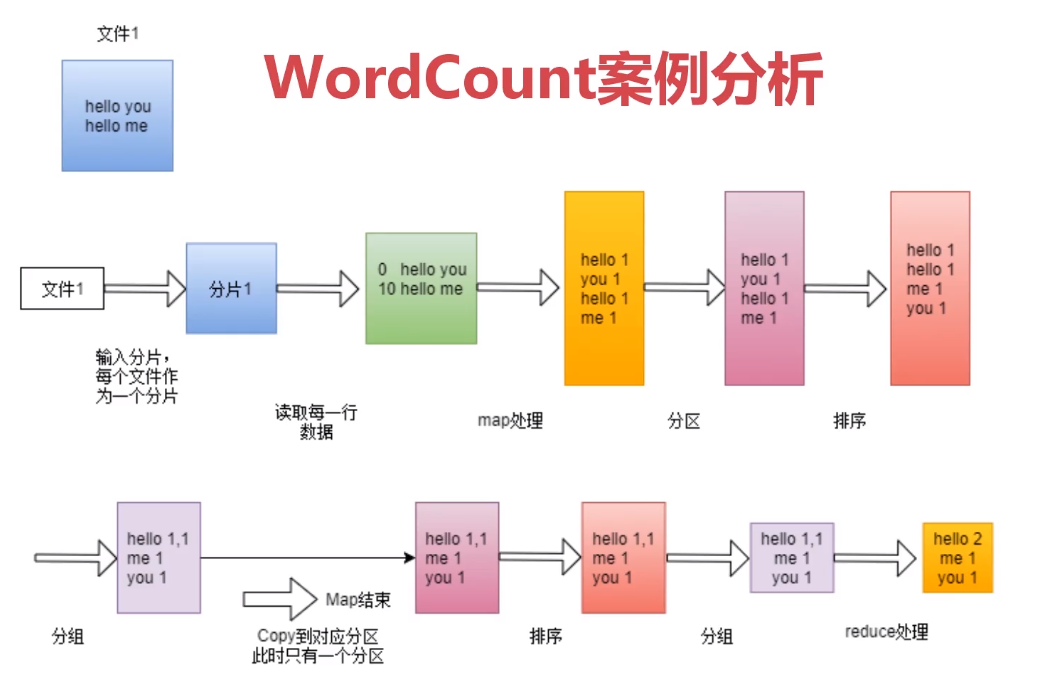
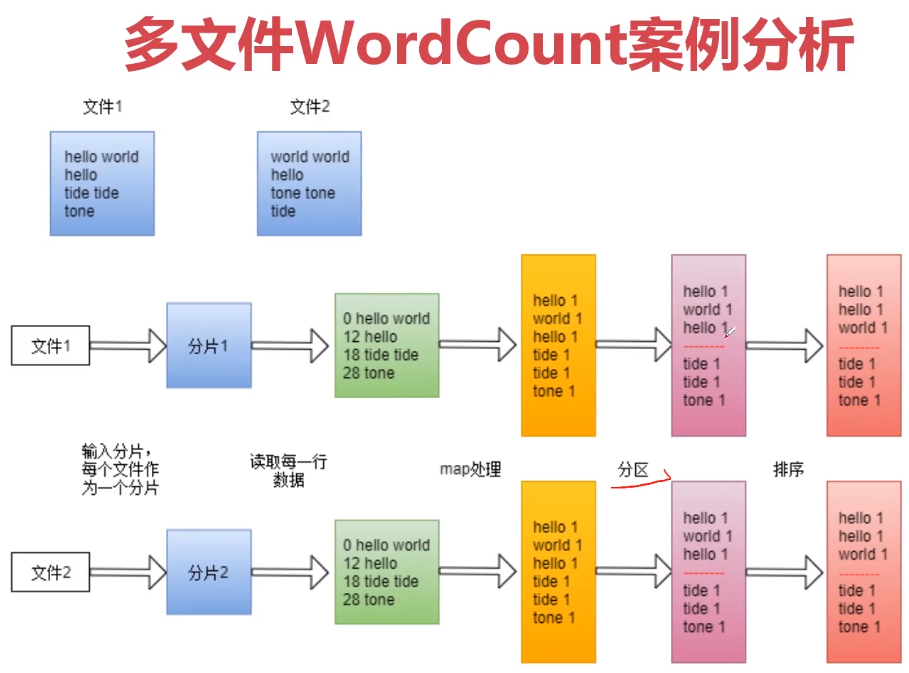
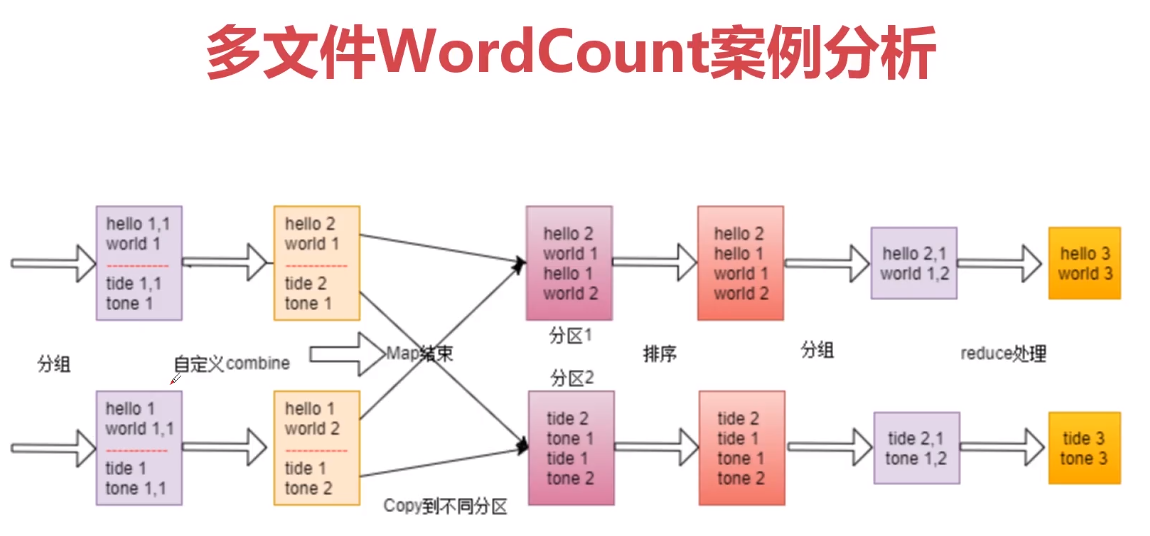
4、实战:WordCount案例开发
1).开发Map阶段代码
/**
* 创建自定义mapper类
*/
public static class MyMapper extends Mapper<LongWritable,Text,Text,LongWritable>{
/**
* 需要实现map函数
* 这个map函数就是可以接收k1,v1, 产生k2,v2
* @param k1
* @param v1
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void map(LongWritable k1, Text v1, Context context)
throws IOException, InterruptedException {
// k1代表的是每一行的行首偏移量,v1代表的是每一行内容
// 对获取到的每一行数据进行切割,把单词切割出来
String[] words = v1.toString().split(" ");
// 迭代切割出来的单词数据
for (String word:words) {
// 把迭代出来的单词封装成<k2,v2>的形式
Text k2 = new Text(word);
LongWritable v2 = new LongWritable(1L);
System.out.println("k2:"+word+"...v2:1");
// 把<k2,v2>写出去
context.write(k2,v2);
}
}
}
2).开发Reduce阶段代码
/**
* 创建自定义的reducer类
*/
public static class MyReducer extends Reducer<Text,LongWritable,Text,LongWritable>{
/**
* 针对v2s的数据进行累加求和 并且最终把数据转化为k3,v3写出去
* @param k2
* @param v2s
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void reduce(Text k2, Iterable<LongWritable> v2s, Context context)
throws IOException, InterruptedException {
// 创建一个sum变量,保存v2s的和
long sum = 0L;
for (LongWritable v2 : v2s) {
sum += v2.get();
}
// 组装k3,v3
Text k3 = k2;
LongWritable v3 = new LongWritable(sum);
System.out.println("k3:"+k3.toString()+".....v3:"+sum);
// 把结果写出去
context.write(k3,v3);
}
}
3).组装Job
/**
* 组装job=map+reduce
* @param args
*/
public static void main(String[] args) {
try {
if(args.length!=2){
// 如果传递的参数不够,程序直接退出
System.exit(100);
}
// job需要的配置参数
Configuration conf = new Configuration();
// 创建一个job
Job job = Job.getInstance(conf);
// 注意:这一行必须设置,否则在集群中执行的是找不到WordCountJob这个类
job.setJarByClass(WordCountJob.class);
// 指定输入路径(可以是文件,也可以是目录)
FileInputFormat.setInputPaths(job,new Path(args[0]));
// 指定输出路径(只能指定一个不存在的目录)
FileOutputFormat.setOutputPath(job,new Path(args[1]));
// 指定map相关的代码
job.setMapperClass(MyMapper.class);
// 指定k2的类型
job.setMapOutputKeyClass(Text.class);
// 指定v2的类型
job.setMapOutputValueClass(LongWritable.class);
// 指定reduce相关的代码
job.setReducerClass(MyReducer.class);
// 指定k3的类型
job.setOutputKeyClass(Text.class);
// 指定v3的类型
job.setOutputValueClass(LongWritable.class);
// 提交job
job.waitForCompletion(true);
}catch (Exception e){
e.printStackTrace();
}
}
4).打包:mvn clean package
hadoopDemo-1.0-SNAPSHOT-jar-with-dependencies.jar
5).上传程序 + 提交hello.txt文件到hdfs
bin/hdfs dfs -put /data/soft/hadoop-3.2.0/hello.txt /test
6).执行job
bin/hadoop jar hadoopDemo-1.0-SNAPSHOT-jar-with-dependencies.jar WordCountJob /test/hello.txt /out
7).查看结果: hdfs dfs -cat /out/part-r-00000
5、MapReduce任务日志查看, 开启yarn的日志聚合功能,把散落在nodemanager节点上的日志收集管理:
修改yarn-site.xml中
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://bigdata128:19888/jobhistory/logs/</value>
</property>
重启集群:
sbin/stop-all.sh sbin/start-all.sh
启动history进程(每个节点都要):
sbin/mr-jobhistory-daemon.sh start historyserver
或者 sbin/mapred --daemon start historyserver
浏览器查看任务history
PS: win浏览器访问bigdata129地址时,需要现在win的hosts加映射
6、停止Hadoop集群中的任务
查看任务:yarn application -list
停任务:yarn application -kill {application_id}
7、MapReduce程序扩展 当数据只需要进行普通的过滤、解析等操作,不需要进行聚合,这个时候就不需要使用reduce阶段了
//在组装Job的时候设置reduce的task数目为0就可以了。并且Reduce代码也不需要写了。
public static void main(String[] args) {
......
//禁用reduce阶段
job.setNumReduceTasks(0);
......
}
8、hsdoop序列化机制介绍
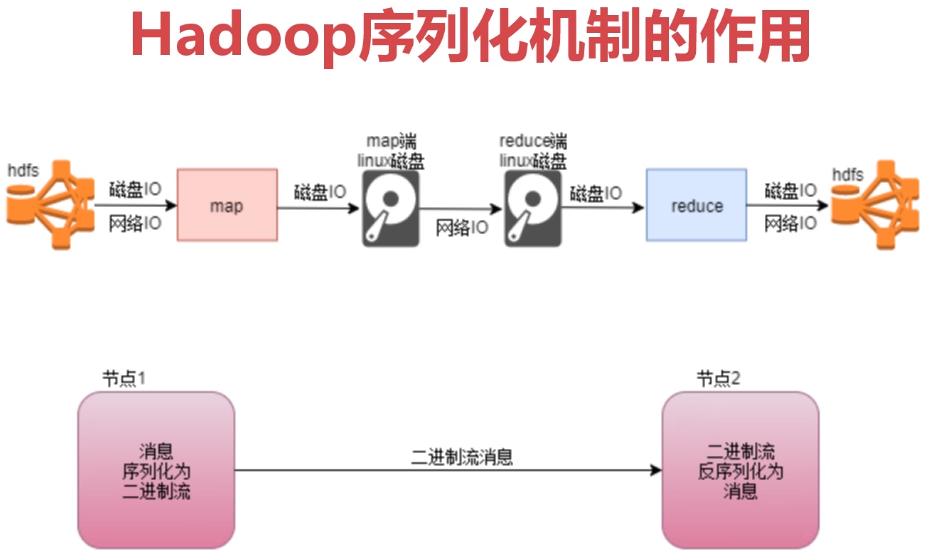 hadoop序列化机制的特点
hadoop序列化机制的特点
- 紧凑:高效使用空间
- 快速: 读写数据额外开销小
- 可扩展:可透明读取老格式数据
- 互操作:支持多语言的交互
第6周 YARN资源调度(拿来就用的企业级解决方案)
- Hadoop的HDFS和MapReduce都是针对大数据文件来设计的,在小文件的处理上不但效率低下,而且十分消耗内存资源
- 针对HDFS而言,每一个小文件在namenode中都会占用150字节的内存空间,最终会导致集群中虽然存储了很多个文件,但是文件的体积并不大,这样就没有意义了。
- 针对MapReduce而言,每一个小文件都是一个Block,都会产生一个InputSplit,最终每一个小文件都会 产生一个map任务,这样会导致同时启动太多的Map任务,Map任务的启动是非常消耗性能的,但是启动了以后执行了很短时间就停止了,因为小文件的数据量太小了,这样就会造成任务执行消耗的时间还没有启动任务消耗的时间多,这样也会影响MapReduce执行的效率。
针对这个问题,解决办法通常是选择一个容器,将这些小文件组织起来统一存储
1、小文件问题之SequenceFile
- SequeceFile是Hadoop 提供的一种二进制文件,这种二进制文件直接将小文件的文件名作为key,文件内容作为value序列化到大文件中
- 但是这个文件有一个缺点,就是它需要一个合并文件的过程,最终合并的文件会比较大,并且合并后的文件查看起来不方便,必须通过遍历才能查看里面的每一个小文件
- 所以这个SequenceFile 其实可以理解为把很多小文件压缩成一个大的压缩包了。
/**
* 小文件解决方案之SequenceFile
* Created by
*/
public class SmallFileSeq {
public static void main(String[] args) throws Exception {
//生成SequenceFile文件
write("D:\\smallFile", "/seqFile");
//读取SequenceFile文件
read("/seqFile");
}
/**
* 生成SequenceFile文件
*
* @param inputDir 输入目录-windows目录
* @param outputFile 输出文件-hdfs文件
* @throws Exception
*/
private static void write(String inputDir, String outputFile)
throws Exception {
//创建一个配置对象
Configuration conf = new Configuration();
//指定HDFS的地址
conf.set("fs.defaultFS", "hdfs://bigdata01:9000");
//获取操作HDFS的对象
FileSystem fileSystem = FileSystem.get(conf);
//删除输出文件
fileSystem.delete(new Path(outputFile), true);
//构造opts数组,有三个元素
/*
第一个是输出路径
第二个是key类型
第三个是value类型
*/
SequenceFile.Writer.Option[] opts = new SequenceFile.Writer.Option[]{
SequenceFile.Writer.file(new Path(outputFile)),
SequenceFile.Writer.keyClass(Text.class),
SequenceFile.Writer.valueClass(Text.class)};
//创建一个writer实例
SequenceFile.Writer writer = SequenceFile.createWriter(conf, opts);
//指定要压缩的文件的目录
File inputDirPath = new File(inputDir);
if (inputDirPath.isDirectory()) {
File[] files = inputDirPath.listFiles();
for (File file : files) {
//获取文件全部内容
String content = FileUtils.readFileToString(file, "UTF-8");
//文件名作为key
Text key = new Text(file.getName());
//文件内容作为value
Text value = new Text(content);
writer.append(key, value);
}
}
writer.close();
}
/**
* 读取SequenceFile文件
*
* @param inputFile SequenceFile文件路径
* @throws Exception
*/
private static void read(String inputFile)
throws Exception {
//创建一个配置对象
Configuration conf = new Configuration();
//指定HDFS的地址
conf.set("fs.defaultFS", "hdfs://bigdata01:9000");
//创建阅读器
SequenceFile.Reader reader = new SequenceFile.Reader(conf, SequenceFi
Text key = new Text();
Text value = new Text();
//循环读取数据
while (reader.next(key, value)) {
//输出文件名称
System.out.print("文件名:" + key.toString() + ",");
//输出文件的内容
System.out.println("文件内容:" + value.toString());
}
reader.close();
}
}
2、小文件问题之MapFile
-
MapFile是排序后的SequenceFile,MapFile由两部分组成,分别是index和data
index作为文件的数据索引,记录每个Record的key值,及该Record在文件中的偏移位置。MapFile被访问时,索引文件会被加载到内存,通过索引映射关系可迅速定位到指定Record所在文件位置,因此,相对SequenceFile而言,MapFile的检索效率是高效的,缺点是会消耗一部分内存来存储index数据。
/**
* 小文件解决方案之MapFile
* Created by
*/
public class SmallFileMap {
public static void main(String[] args) throws Exception{
//生成MapFile文件
write("D:\\smallFile","/mapFile");
//读取MapFile文件
read("/mapFile");
}
/**
* 生成MapFile文件
* @param inputDir 输入目录-windows目录
* @param outputDir 输出目录-hdfs目录
* @throws Exception
*/
private static void write(String inputDir,String outputDir)
throws Exception{
//创建一个配置对象
Configuration conf = new Configuration();
//指定HDFS的地址
conf.set("fs.defaultFS","hdfs://bigdata01:9000");
//获取操作HDFS的对象
FileSystem fileSystem = FileSystem.get(conf);
//删除输出目录
fileSystem.delete(new Path(outputDir),true);
//构造opts数组,有两个元素
/*
第一个是key类型
第二个是value类型
*/
SequenceFile.Writer.Option[] opts = new SequenceFile.Writer.Option[]{
MapFile.Writer.keyClass(Text.class),
MapFile.Writer.valueClass(Text.class)};
//创建一个writer实例
MapFile.Writer writer = new MapFile.Writer(conf,new Path(outputDir),o
//指定要压缩的文件的目录
File inputDirPath = new File(inputDir);
if(inputDirPath.isDirectory()){
File[] files = inputDirPath.listFiles();
for (File file : files) {
//获取文件全部内容
String content = FileUtils.readFileToString(file, "UTF-8");
//文件名作为key
Text key = new Text(file.getName());
//文件内容作为value
Text value = new Text(content);
writer.append(key,value);
}
}
writer.close();
}
/**
* 读取MapFile文件
* @param inputDir MapFile文件路径
* @throws Exception
*/
private static void read(String inputDir)
throws Exception{
//创建一个配置对象
Configuration conf = new Configuration();
//指定HDFS的地址
conf.set("fs.defaultFS","hdfs://bigdata01:9000");
//创建阅读器
MapFile.Reader reader = new MapFile.Reader(new Path(inputDir),conf);
Text key = new Text();
//循环读取数据
while(reader.next(key,value)){
//输出文件名称
System.out.print("文件名:"+key.toString()+",");
//输出文件的内容
System.out.println("文件内容:"+value.toString());
}
reader.close();
}
}
3、案例:小文件存储和计算
/**
* 需求:读取SequenceFile文件
* Created by
*/
public class WordCountJobSeq {
public static class MyMapper extends Mapper<Text, Text, Text, LongWritable> {
Logger logger = LoggerFactory.getLogger(MyMapper.class);
/**
* 需要实现map函数
* 这个map函数就是可以接收<k1,v1>,产生<k2,v2>
*
* @param k1
* @param v1
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void map(Text k1, Text v1, Context context)
throws IOException, InterruptedException {
//输出k1,v1的值
System.out.println("<k1,v1>=<" + k1.toString() + "," + v1.toString() + ">
//logger.info("<k1,v1>=<"+k1.get()+","+v1.toString()+">");
//k1 代表的是每一行数据的行首偏移量,v1代表的是每一行内容
//对获取到的每一行数据进行切割,把单词切割出来
String[]words = v1.toString().split(" ");
//迭代切割出来的单词数据
for (String word : words) {
//把迭代出来的单词封装成<k2,v2>的形式
Text k2 = new Text(word);
LongWritable v2 = new LongWritable(1L);
//把<k2,v2>写出去
context.write(k2, v2);
}
}
}
/**
* Reduce阶段
*/
public static class MyReducer extends Reducer<Text, LongWritable, Text, LongWritable> {
Logger logger = LoggerFactory.getLogger(MyReducer.class);
/**
* 针对<k2,{v2...}>的数据进行累加求和,并且最终把数据转化为k3,v3写出去
*
* @param k2
* @param v2s
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void reduce(Text k2, Iterable<LongWritable> v2s, Context cocontext>) throws IOException, InterruptedException {
//创建一个sum变量,保存v2s的和
long sum = 0L;
//对v2s中的数据进行累加求和
for (LongWritable v2 : v2s) {
//输出k2,v2的值
//System.out.println("<k2,v2>=<"+k2.toString()+","+v2.get()+"
//logger.info("<k2,v2>=<"+k2.toString()+","+v2.get()+">");
sum += v2.get();
}
//组装k3,v3
Text k3 = k2;
LongWritable v3 = new LongWritable(sum);
//输出k3,v3的值
//System.out.println("<k3,v3>=<"+k3.toString()+","+v3.get()+">");
//logger.info("<k3,v3>=<"+k3.toString()+","+v3.get()+">");
context.write(k3, v3);
}
}
/**
* 组装Job=Map+Reduce
*/
public static void main(String[] args) {
try {
if (args.length != 2) {
//如果传递的参数不够,程序直接退出
System.exit(100);
}
//指定Job需要的配置参数
Configuration conf = new Configuration();
//创建一个Job
Job job = Job.getInstance(conf);
//注意了:这一行必须设置,否则在集群中执行的时候是找不到WordCountJob这个
job.setJarByClass(WordCountJobSeq.class);
//指定输入路径(可以是文件,也可以是目录)
FileInputFormat.setInputPaths(job, new Path(args[0]));
//指定输出路径(只能指定一个不存在的目录)
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//指定map相关的代码
job.setMapperClass(MyMapper.class);
//指定k2的类型
job.setMapOutputKeyClass(Text.class);
//指定v2的类型
job.setMapOutputValueClass(LongWritable.class);
//设置输入数据处理类
job.setInputFormatClass(SequenceFileInputFormat.class);
//指定reduce相关的代码
job.setReducerClass(MyReducer.class);
//指定k3的类型
job.setOutputKeyClass(Text.class);
//指定v3的类型
job.setOutputValueClass(LongWritable.class);
//提交job
job.waitForCompletion(true);
} catch (Exception e) {
e.printStackTrace();
}
}
}
4、 数据倾斜问题分析
提高MapReduce的执行效率
- 默认情况下Map任务个数和InputSplit相关,InputSplit个数和Block块有关,所以可认为Map任务个数和数据的block块个数有关
- 默认情况下reduce的个数是1个,可以考虑增加reduce任务个数,这样就可以实现数据分流了,提高计算效率
5、数据倾斜案例实战 思路:把倾斜的数据打散
//1.map阶段,打散倾斜数据
map{
String key = words[0];
if("5".equals(key)){
//把倾斜的key打散,分成10份
key = "5"+"_"+random.nextInt(10);
}
}
//2.job设置多个reduce任务
main(){
//设置reduce任务个数
job.setNumReduceTasks(Integer.parseInt(args[2]));
}
//3.结果不符合要求:1 10;... 5_1 1000; 5_2 2000;...
再开发一个map-reduce任务,把5_*的求和下
6、YARN资源调度器 YARN不仅仅支持MapReduce,还支持Spark、Flink等计算引擎
主要负责集群资源的管理和调度,支持主从结构
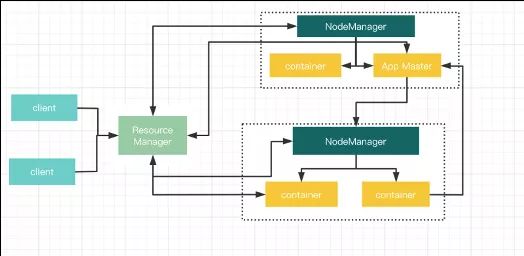
- 主节点(ResourceManager)进程主要负责集群资源的管理和分配,并处理客户端请求,启动和监控AppMaster, NodeManager
- 从节点(NodeManager)主要负责单节点资源管理,处理ResourceManager, AppMaster 的命令
- AppMaster:负责某个具体应用程序的调度和协调,为应用程序申请资源,并对任务进行监控
- Container:YARN中的一个动态资源分配的概念,其拥有一定的内存,核数
YARN资源管理模型
- YARN主要管理内存和CPU这两种资源类型
- NodeManager启动时会向ResourceManager注册,注册信息中包含该节点可分配的CPU和内存总量
- yarn.nodemanager.resource.memory-mb:单节点可分配的物理内存总量,默认是8MB*1024,即8G
- yarn.nodemanager.resource.cpu-vcores:单节点可分配的虚拟CPU个数,默认是8
7、YARN中的调度器分析
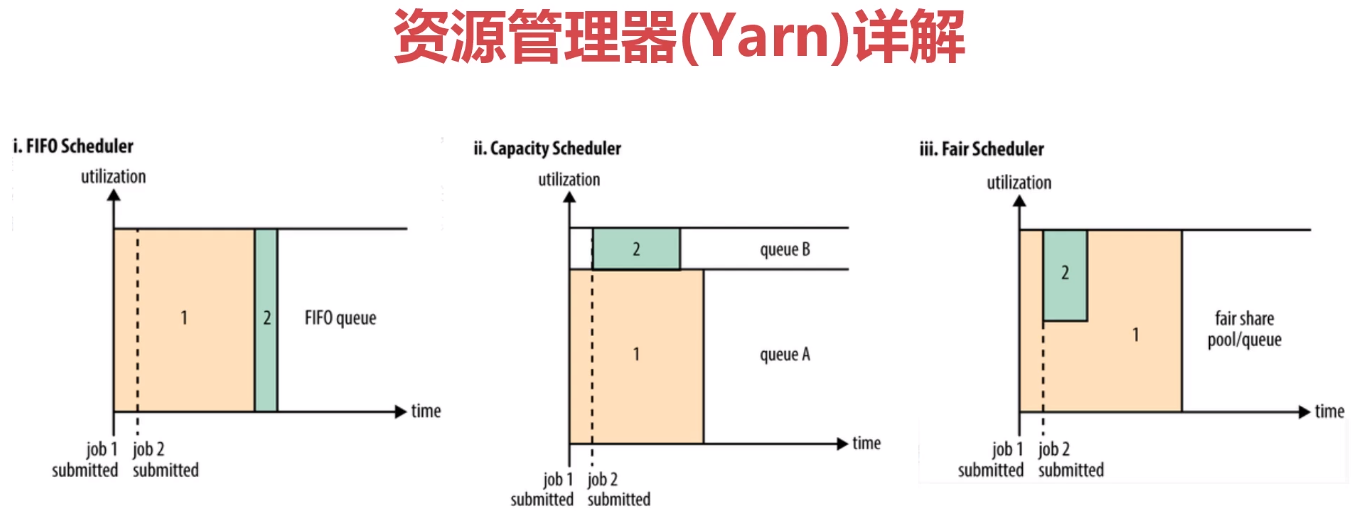
- FIFO Scheduler:先进先出(first in, first out)调度策略
- CapacityScheduler:可以看作是FifoScheduler的多队列版本。
- FairScheduler:多队列,多用户共享资源。
8、案例:YARN多资源队列配置和使用
1:capacity-scheduler.xml 增加online队列和offline队列 ,并根据预估实际使用调整比例
<property>
<name>yarn.scheduler.capacity.root.queues</name>
<value>default,online,offline</value>
<description>
The queues at the this level (root is the root queue).
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.capacity</name>
<value>70</value>
<description>Default queue target capacity.</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.maximum-capacity</name>
<value>70</value>
<description>
The maximum capacity of the default queue.
</description>
</property>
<!--新增-->
<property>
<name>yarn.scheduler.capacity.root.online.capacity</name>
<value>10</value>
<description>online queue target capacity.</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.offline.capacity</name>
<value>20</value>
<description>offline queue target capacity.</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.online.maximum-capacity</name>
<value>10</value>
<description>
The maximum capacity of the online queue.
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.offline.maximum-capacity</name>
<value>20</value>
<description>
The maximum capacity of the offline queue.
</description>
</property>
2:向offline队列提交任务
//组装job
main(String[] args){
//解析命令行中通过-D传递过来的参数,添加到conf中
String[] remainingArgs = new GenericOptionParser(conf, args).getRemainingArgs();
}
执行命令:hadoop jar db_hadoop-1.0-SNAPSHOT-jar-with-dependencies.jar com.wds.wordcountQueue -Dmapreduce.job.queuename=offline /hello.dat /out 10
9、Hadoop官方文档使用指北
10、Hadoop在CDH中的使用
11、Hadoop在HDP中的使用