Flume + Hive + PB级离线数据计算分析方案
阶段二:Flume + Hive + PB级离线数据计算分析方案
第7周 数据采集工具-Flume
1、快速了解Flume及应用场景
Flume是一个高可用,高可靠,分布式的海量日志采集、聚合和传输的系统,能够有效的收集、聚合、移动大量的日志数据。
通俗一点来说就是Flume是一个很靠谱,很方便、很强的日志采集工具。
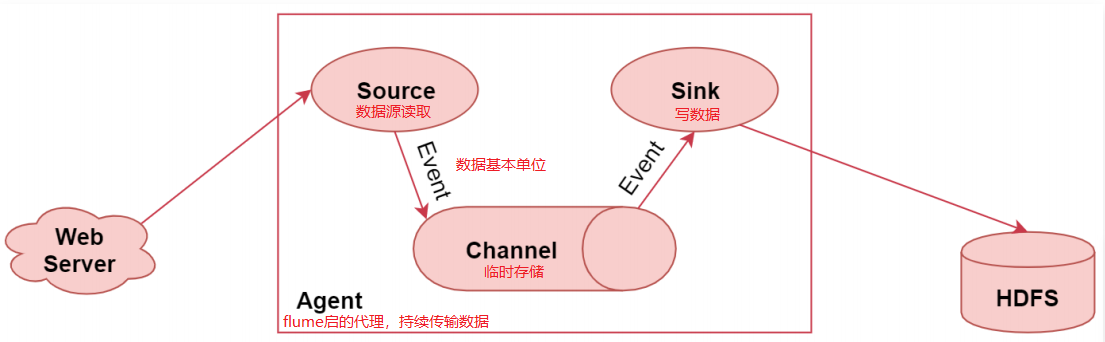
Flume特性:
- 它有一个简单、灵活的基于流的数据流结构,这个其实就是刚才说的Agent内部有三大组件,数据通 过这三大组件流动的
- 具有负载均衡机制和故障转移机制,这个后面我们会详细分析
- 一个简单可扩展的数据模型(Source、Channel、Sink),这几个组件是可灵活组合的
Flume高级应用场景:
-
Flume的多路输出: 就是将采集到的一份数据输出到多个目的地中,不同目的地的数据对应不同的业务场景。
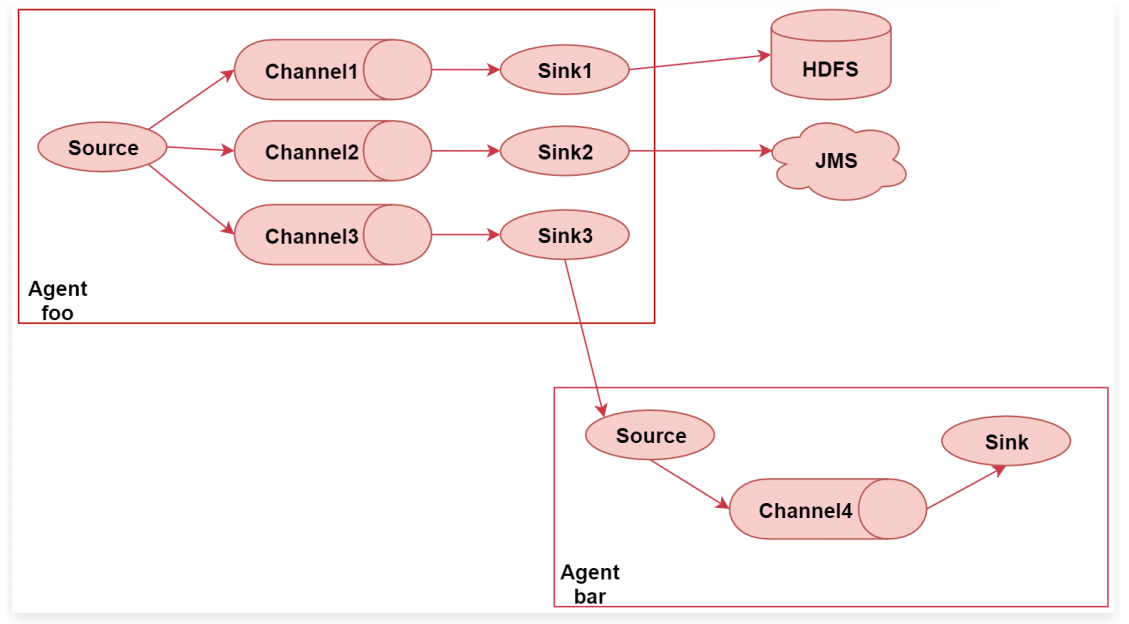
注意了,Flume中多个Agent之间是可以连通的,只需要让前面Agent的sink组件把数据写到下一 个Agent的source组件中即可 -
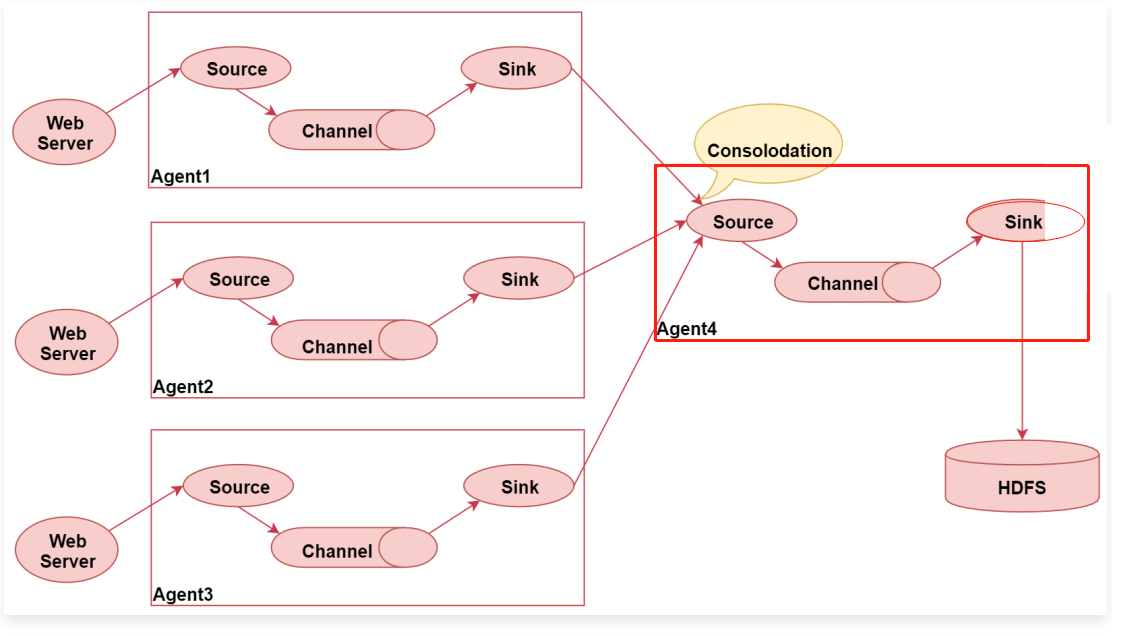
flume的汇聚功能:就是多个Agent采集到的数据统一汇聚到一 个Agent
2、Flume的三大核心组件
Source:数据源,通过source组件可以指定让Flume读取哪里的数据,然后将数据传递给后面的channel
Flume内置支持读取很多种数据源,基于文件、目录、TCP\UDP端口、HTTP、Kafka的等;也是支持自定义的。
- Exec Source:实现文件监控,可以实时监控文件中的新增内容,类似于linux中的tail -f 效果
- NetCat TCP/UDP Source: 采集指定端口(tcp、udp)的数据,可以读取流经端口的每一行数据
- Spooling Directory Source:采集文件夹里新增的文件
- Kafka Source:从Kafka消息队列中采集数据
Channel:临时存储数据的管道,接受Source发出的数据
Channel的类型有很多:内存、文件,内存+文件、JDBC等
- Memory Channel:使用内存作为数据的存储(效率高,的agent挂了数据就丢了、内存有限)
- File Channel:使用文件来作为数据的存储(数据不会丢,效率相对慢一些,常用)
- Spillable Memory Channel:使用内存和文件作为数据存储,先把数据存内存,内存中数据达到阈值再flush到文件中
Sink:从Channel中读取数据并存储到指定目的地
Sink的表现形式有很多:打印到控制台、HDFS、Kafka等
- Logger Sink:将数据作为日志处理,可打印到控制台或写到文件中,这个主要在测试的时候使用
- HDFS Sink:将数据传输到HDFS中,比较常见的,主要针对离线计算的场景
- Kafka Sink:将数据发送到kafka消息队列中,也是比较常见的,主要针对实时计算场景,数据不落盘,实时传输,最后使用实时计算框架直接处理。
注意:Channel中的数据直到进入目的地才会被删除,当Sink写入目的地失败后,可以自动重写,不会造成数据丢失,这块是有一个事务保证的。
3、Flume安装部署
1.环境准备:虚拟机、ip-192.168.145.131、防火墙、jdk
2.下载、上传、解压:http://flume.apache.org/download.html
3.修改盘flume的env环境变量配置文件:在flume的conf目录,修改flume-env.sh.template名字,去掉后缀template
cd apache-flume/conf
mv flume-env.sh.template flume-env.sh
4.这个时候我们不需要启动任何进程,只有在配置好采集任务之后才需要启动Flume
4、Flume的Hello World案例 – 采集TCP链接输入信息
// 1.在conf目录下新建采集任务配置example.conf, 编辑内容如下
# example.conf: A single-node Flume configuration
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = netcat
# 配置localhost ip时,只能严格通过 localhost ip链接,配置0.0.0.0,即可通过 localhost 或 ip链接
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 44444
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
//2.Agent配置好了以后就可以启动
bin/flume-ng agent --name a1 --conf conf --conf-file example.conf -Dflume.root.logger=INFO,console
这里面使用flume-ng命令, 后面指定agent,表示启动一个Flume的agent代理
--name:指定agent的名字
--conf:指定flume配置文件的根目录
--conf-file:指定Agent对应的配置文件(包含source、channel、sink配置的文件)
-D:动态添加一些参数,在这里是指定了flume的日志输出级别和输出位置,INFO表示日志
//3. 客户端连接测试
安装:telnet:yum install -y telnet
链接: telnet 192.168.145.131 44444
链接成功后即可输入信息hello world,再flume控制台对应可以看到输出hello world
//4.后台启动
nohup bin/flume-ng agent --name a1 --conf conf --conf-file example.conf &
5、Flume文件数据采集案例:采集文件内容上传至HDFS
需求:采集目录中已有的文件内容,存储到HDFS
分析:source是要基于目录的,channel建议使用file,可以保证不丢数据,sink使用hdfs
// 1.新建Agent任务:file-to-hdfs.conf
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
a1.sources.r1.type = spooldir
a1.sources.r1.spoolDir = /data/log/studentDir
a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /data/soft/apache-flume-1.9.0-bin/data/studentDir/checkpoint
a1.channels.c1.dataDirs = /data/soft/apache-flume-1.9.0-bin/data/studentDir/data
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://192.168.145.128:9000/flume/studentDir
a1.sinks.k1.hdfs.filePrefix = stu-
a1.sinks.k1.hdfs.fileSuffix = dat
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.writeFormat = Text
a1.sinks.k1.hdfs.rollInterval = 3600
a1.sinks.k1.hdfs.rollSize = 134217728
a1.sinks.k1.hdfs.rollCount = 0
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
//2.初始化source目录、测试数据
[root@bigdata131 studentDir]#mkdir -p /data/log/studentDir
[root@bigdata131 studentDir]#cd /data/log/studentDir
[root@bigdata131 studentDir]# more class1.dat
jack 18 male
jessic 20 female
tom 17 male
//3.启动Hadoop集群
[root@bigdata128 ~]# cd /data/soft/hadoop-3.2.0
[root@bigdata128 hadoop-3.2.0]# sbin/start-all.sh
//4.启动Agent,
bin/flume-ng agent --name a1 --conf conf --conf-file file-to-hdfs.conf -Dflume.root.logger=INFO,console
问题:会报错提示找不到SequenceFile、No FileSystem for scheme: hdfs等
解决:把flume节点设置为hadoop集群的一个客户端节点: 把hadoop目录拷贝到flume主机131上,并配置hadoop环境变量
//5.查看结果
hdfs dfs -ls hdfs://192.168.145.128:9000/flume/studentDir
- Flume会不会重复读取同一个文件的数据? 不会,读过的文件被加了一个后缀 .COMPLETED
6、Flume文件数据采集案例:采集网站日志上传至HDFS
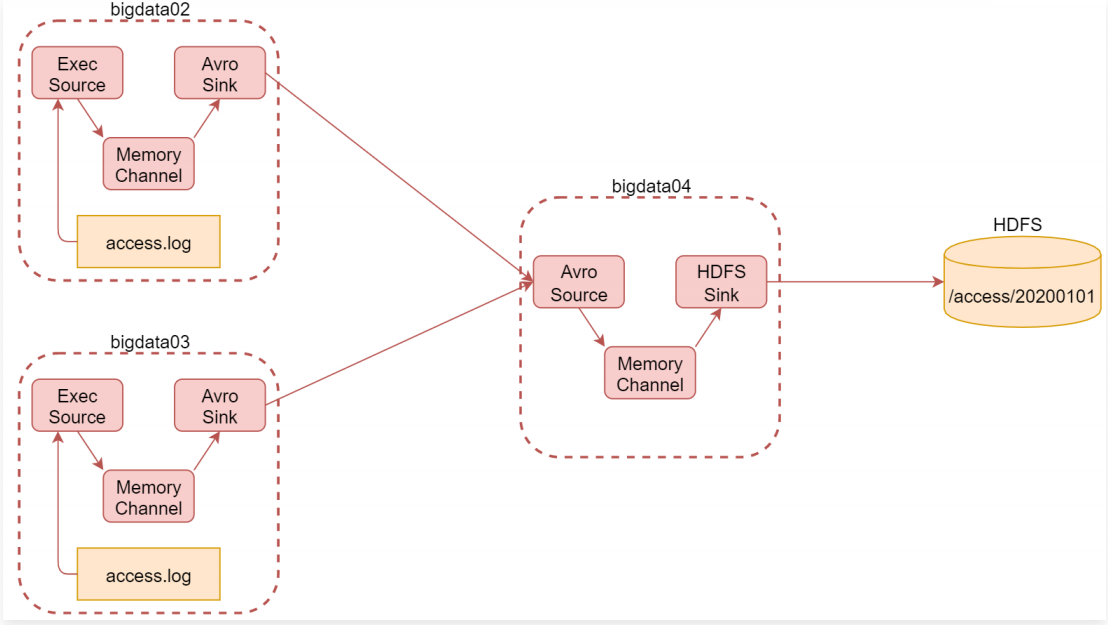
需求:
- 1.将A和B两台机器实时产生的日志数据汇总到机器C中
- 2.通过机器C将数据统一上传至HDFS的指定目录中
- 3.HDFS中的目录是按天生成的,每天一个目录
分析:
- 使用bigdata02和bigdata03采集当前机器上产生的实时日志数据,统一汇总到bigdata04机器上
- bigdata02和bigdata03中的source使用基于file的source,ExecSource,实时读取文件中的新增数据
- channel使用基于内存的channel,因为是采集网站的访问日志,就算丢一两条数据对整体结果影响也不大,采集到的数据可以快读进入hdfs中
- bigdata02和bigdata03的数据需要快速发送到bigdata04中,通过网络直接传输,sink建议使用avrosink
- bigdata04的source使用avrosource,avrosink的数据可以直接发送给avrosource,所以他们可以无缝衔接。
- channel还是基于内存的channel,sink就使用hdfssink,因为是要向hdfs中写数据
实现:
- 3台主机上安装flume,配置相应的Agent
- bigdata02和bigdata03中配置的a1.sinks.k1.port 的值45454需要和bigdata04中配置的a1.sources.r1.port的值45454一样
- 启动的时候需要注意先后顺序,先启动bigdata04上面的,再启 动bigdata02和bigdata03上面的agent
- 依次停止bigdata02、bigdata03中的服务,最后停止bigdata04中的服务
// agent-bigdata02
# agent的名称是a1
# 指定source组件、channel组件和Sink组件的名称
a1.sources = r1
a1.channels = c1
a1.sinks = k1
# 配置source组件
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /data/log/access.log
# 配置channel组件
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# 配置sink组件
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = 192.168.145.131
a1.sinks.k1.port = 45454
# 把组件连接起来
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
// agent-bigdata03
# agent的名称是a1
# 指定source组件、channel组件和Sink组件的名称
a1.sources = r1
a1.channels = c1
a1.sinks = k1
# 配置source组件
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /data/log/access.log
# 配置channel组件
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# 配置sink组件
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = 192.168.145.131
a1.sinks.k1.port = 45454
# 把组件连接起来
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
// agent-bigdata04
# agent的名称是a1
# 指定source组件、channel组件和Sink组件的名称
a1.sources = r1
a1.channels = c1
a1.sinks = k1
# 配置source组件
a1.sources.r1.type = avro
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 45454
# 配置channel组件
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# 配置sink组件
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://192.168.145.131:9000/access/%Y%m%d
a1.sinks.k1.hdfs.filePrefix = access
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.writeFormat = Text
a1.sinks.k1.hdfs.rollInterval = 3600
a1.sinks.k1.hdfs.rollSize = 134217728
a1.sinks.k1.hdfs.rollCount = 0
# path目录拼接时间,时间值来源
a1.sinks.k1.hdfs.useLocalTimeStamp = true
# 把组件连接起来
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
7、Flume高级组件之Source Interceptors
Source可以指定一个或者多个拦截器按先后顺序依次对采集到的数据进行处理
系统中已经内置提供了很多Source Interceptors:
- Timestamp Interceptor:向event中的header里面添加timestamp 时间戳信息
- Host Interceptor:向event中的header里面添加host属性,host的值为当前机器的主机名或者ip
- Search and Replace Interceptor:根据指定的规则查询Event中body里面的数据,然后进行替换,这个拦截器会修改event中body的值,也就是会修改原始采集到的数据内容
- Static Interceptor:向event中的header里面添加固定的key和value
- Regex Extractor Interceptor:根据指定的规则从Event中的body里面抽取数据,生成key和value,再把key和value添加到header中
使用:
# agent的名称是a1
# 指定source组件、channel组件和Sink组件的名称
a1.sources = r1
a1.channels = c1
a1.sinks = k1
# 配置source组件
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /data/log/moreType.log
# 配置拦截器 [多个拦截器按照顺序依次执行]
a1.sources.r1.interceptors = i1 i2 i3 i4
a1.sources.r1.interceptors.i1.type = search_replace
a1.sources.r1.interceptors.i1.searchPattern = "type":"video_info"
a1.sources.r1.interceptors.i1.replaceString = "type":"videoInfo"
a1.sources.r1.interceptors.i2.type = search_replace
a1.sources.r1.interceptors.i2.searchPattern = "type":"user_info"
a1.sources.r1.interceptors.i2.replaceString = "type":"userInfo"
a1.sources.r1.interceptors.i3.type = search_replace
a1.sources.r1.interceptors.i3.searchPattern = "type":"gift_record"
a1.sources.r1.interceptors.i3.replaceString = "type":"giftRecord"
a1.sources.r1.interceptors.i4.type = regex_extractor
a1.sources.r1.interceptors.i4.regex = "type":"(\\w+)"
a1.sources.r1.interceptors.i4.serializers = s1
# 通过source的拦截器可以向event的header中添加key-value
a1.sources.r1.interceptors.i4.serializers.s1.name = logType
# 配置channel组件
a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /data/soft/apache-flume-1.9.0-bin/data/moreType
a1.channels.c1.dataDirs = /data/soft/apache-flume-1.9.0-bin/data/moreType/dat
# 配置sink组件
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://192.168.145.128:9000/moreType/%Y%m%d/%{logType}
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.writeFormat = Text
a1.sinks.k1.hdfs.rollInterval = 3600
a1.sinks.k1.hdfs.rollSize = 134217728
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k1.hdfs.useLocalTimeStamp = true
#增加文件前缀和后缀
a1.sinks.k1.hdfs.filePrefix = data
a1.sinks.k1.hdfs.fileSuffix = .log
# 把组件连接起来
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
8、Flume高级组件之Channel Selectors
Source发往多个Channel的策略设置,如果source后面接了多个channel,到底是给所有的channel都发,还是根据规则发送到不同channel,这些是由Channel
Selectors来控制的
Channel Selectors类型包括:
- Replicating Channel Selector 是默认的channel 选择器,它会将Source采集过来的Event发往所有Channel
- Multiplexing Channel Selector,它表示会根据Event中header里面的值将Event发往不同的Channel
示例:
a1.sources = r1
a1.channels = c1 c2 c3 c4
a1.sources.r1.selector.type = multiplexing
a1.sources.r1.selector.header = state
a1.sources.r1.selector.mapping.CZ = c1
a1.sources.r1.selector.mapping.US = c2 c3
a1.sources.r1.selector.default = c4
在这个例子的配置中,指定了4个channel,c1、c2、c3、c4
source采集到的数据具体会发送到哪个channel中,会根据event中header里面的state属性的值,这个是通过selector.header控制的
如果state属性的值是CZ,则发送给c1
如果state属性的值是US,则发送给c2 c3
如果state属性的值是其它值,则发送给c4
案例一:多Channel之Replicating Channel Selector
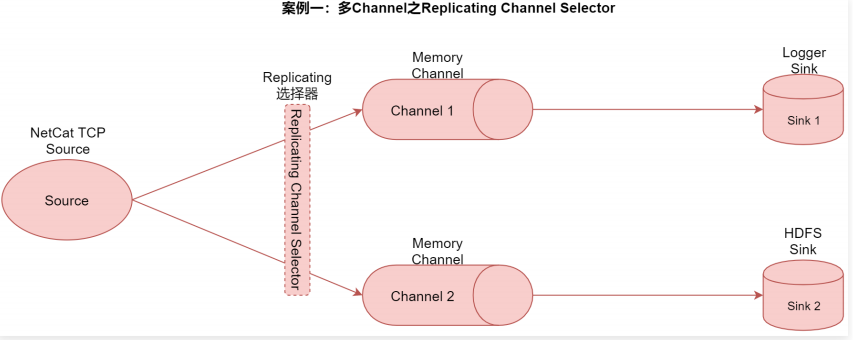
需求:把一份数据采集过来以后,分别存储到不同的存储介质中,不同存储介质的特点和应用场景是不一样的,典型的就是hdfssink
和kafkasink,
- 通过hdfssink实现离线数据落盘存储,方便后面进行离线数据计算
- 通过kafkasink实现实时数据存储,方便后面进行实时计算,在这里先使用loggersink代替
实现:
# agent的名称是a1
# 指定source组件、channel组件和Sink组件的名称
a1.sources = r1
a1.channels = c1 c2
a1.sinks = k1 k2
# 配置source组件
a1.sources.r1.type = netcat
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 44444
# 配置channle选择器[默认就是replicating,所以可以省略]
a1.sources.r1.selector.type = replicating
# 配置channel组件
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
a1.channels.c2.type = memory
a1.channels.c2.capacity = 1000
a1.channels.c2.transactionCapacity = 100
# 配置sink组件
a1.sinks.k1.type = logger
a1.sinks.k2.type = hdfs
a1.sinks.k2.hdfs.path = hdfs://192.168.145.128:9000/replicating
a1.sinks.k2.hdfs.fileType = DataStream
a1.sinks.k2.hdfs.writeFormat = Text
a1.sinks.k2.hdfs.rollInterval = 3600
a1.sinks.k2.hdfs.rollSize = 134217728
a1.sinks.k2.hdfs.rollCount = 0
a1.sinks.k2.hdfs.useLocalTimeStamp = true
a1.sinks.k2.hdfs.filePrefix = data
a1.sinks.k2.hdfs.fileSuffix = .log
# 把组件连接起来
a1.sources.r1.channels = c1 c2
a1.sinks.k1.channel = c1
a1.sinks.k2.channel = c2
案例二:多Channel之Multiplexing Channel Selector
需求 : 分别输出到两个sink
{“name”:”jack”,”age”:19,”city”:”bj”}
{“name”:”tom”,”age”:26,”city”:”sh”}
实现:
# agent的名称是a1
# 指定source组件、channel组件和Sink组件的名称
a1.sources = r1
a1.channels = c1 c2
a1.sinks = k1 k2
# 配置source组件
a1.sources.r1.type = netcat
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 44444
# 配置source拦截器
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = regex_extractor
a1.sources.r1.interceptors.i1.regex = "city":"(\\w+)"
a1.sources.r1.interceptors.i1.serializers = s1
a1.sources.r1.interceptors.i1.serializers.s1.name = city
# 配置channle选择器
a1.sources.r1.selector.type = multiplexing
a1.sources.r1.selector.header = city
a1.sources.r1.selector.mapping.bj = c1
a1.sources.r1.selector.default = c2
# 配置channel组件
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
a1.channels.c2.type = memory
a1.channels.c2.capacity = 1000
a1.channels.c2.transactionCapacity = 100
# 配置sink组件
a1.sinks.k1.type = logger
a1.sinks.k2.type = hdfs
a1.sinks.k2.hdfs.path = hdfs://192.168.145.128:9000/multiplexing
a1.sinks.k2.hdfs.fileType = DataStream
a1.sinks.k2.hdfs.writeFormat = Text
a1.sinks.k2.hdfs.rollInterval = 3600
a1.sinks.k2.hdfs.rollSize = 134217728
a1.sinks.k2.hdfs.rollCount = 0
a1.sinks.k2.hdfs.useLocalTimeStamp = true
a1.sinks.k2.hdfs.filePrefix = data
a1.sinks.k2.hdfs.fileSuffix = .log
# 把组件连接起来
a1.sources.r1.channels = c1 c2
a1.sinks.k1.channel = c1
a1.sinks.k2.channel = c2
9、Flume高级组件之Sink Processors
Sink 发送数据的策略设置,一个channel后面可以接多个sink,channel中的数据是被哪个sink获取,这个是由Sink Processors控制的
Sink Processors类型包括这三种:
- Default Sink Processor:是默认的,一个channel后面接一个sink的形式
- Load balancing Sink Processor:负载均衡处理器,一个channle后可接多个sink,多个sink属于一个sink group,根据指定的算法进行轮询或者随机发送,减轻单个sink的压力
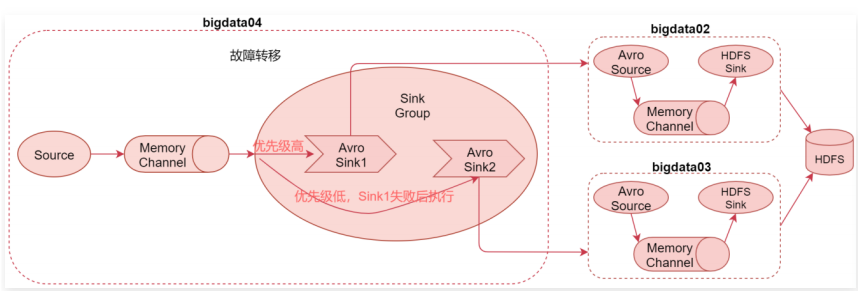
- Failover Sink Processor:故障转移处理器,一个channle后可接多个sink,多个sink属于一个sink group,按照sink的优先级,默认先让优先级高的sink来处理数据,如果这个sink出现了故障,则用优先级低一点的sink处理数据
案例一:负载均衡Sink Processor
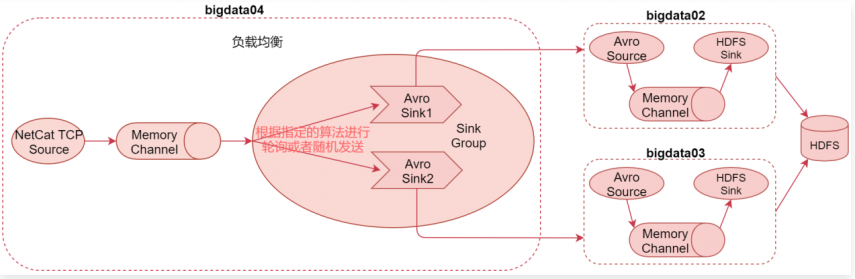
案例一:负载均衡Sink Processor
9-2、扩展:Event Event是Flume传输数据的基本单位,也是事务的基本单位,在文本文件中,通常一行记录就是一个Event
Event中包含header和body;
- body是采集到的那一行记录的原始内容
- header类型为Map<String, String>,里面可以存储一些属性信息,方便后面使用
我们可以在Source中给每一条数据的header中增加key-value,在Channel和Sink中使用header中的值了。
10、各种自定义组件
http://flume.apache.org/releases/content/1.9.0/FlumeDeveloperGuide.html
11、Flume优化
- 调整Flume进程的内存大小,建议设置1G~2G,太小的话会导致频繁GC
//1.用jps查看目前启动flume进程
//2.查看进程GC监控 jstat -gcutil PID 1000
在这里主要看YGC YGCT FGC FGCT GCT
YGC:表示新生代堆内存GC的次数,如果每隔几十秒产生一次,也还可以接受,如果每秒都会发生一次YGC,那说明需要增加内存了
YGCT:表示新生代堆内存GC消耗的总时间
FGC:FULL GC发生的次数,注意,如果发生FUCC GC,则Flume进程会进入暂停状态,FUCC GC执行完以后Flume才会继续工作,所以FUCC GC是非常影响效率的,这个指标的值越低越好,没有更好。
GCT:所有类型的GC消耗的总
//3.调整Flume进程内存:修改flume-env.s h脚本中的 JAVA_OPTS
建议这里的 Xms 和 Xmx 设置为一样大,避免进行内存交换,内存交换也比较消耗性能。
export JAVA_OPTS="-Xms1024m -Xmx1024m -Dcom.sun.management.jmxremote"
- 启动多个Flume进程时,建议修改配置区分日志文件
//1.拷贝多个conf目录,
//2.修改对应conf目录中log4j.properties中日志的文件名称(可以保证多个agent的日志分别存储),
//3.日志级别调整为warn(减少垃圾日志的产生),默认info级别会记录很多日志信息。
//4.启动Agent的时候分别通过–conf参数指定不同的conf目录,后期分析日志就方便了,每一个Agent都有一个单独的日志文件
12、Flume进程监控
- Flume是一个单进程程序,会存在单点故障,所以需要一个监控机制,发现Flume进程Down掉之后,需要重启
- 通过Shell脚本实现Flume进程监控及自动重启
分析:
- 首先需要有一个配置文件,指定需要监控哪些Agent
- 有一个脚本负责读取配置文件中的内容,定时检查Agent对应进程还在不在,发现对应进程不在,则记录错误信息,然后告警( 发短信或者发邮件) 并尝试重启
实现:
//1.创建文件配置需要监控的agent进程: monlist.conf
example=startExample.sh
//2.创建agent重启脚本: startExample.sh
#!/bin/bash
flume_path=/data/soft/apache-flume-1.9.0-bin
nohup ${flume_path}/bin/flume-ng agent --name a1 --conf ${flume_path}/conf/ --conf-file ${flume_path}/conf/example.conf &
//3.创建个脚本来检查进程在不在: monlist.sh
#!/bin/bash
monlist=`cat monlist.conf`
echo "start check"
for item in ${monlist}
do
# 设置字段分隔符
OLD_IFS=$IFS
IFS="="
# 把一行内容转成多列[数组]
arr=($item)
# 获取等号左边的内容
name=${arr[0]}
# 获取等号右边的内容
script=${arr[1]}
echo "time is:"`date +"%Y-%m-%d %H:%M:%S"`" check "$name
if [ `jps -m|grep $name | wc -l` -eq 0 ]
then
# 发短信或者邮件告警
echo `date +"%Y-%m-%d %H:%M:%S"`$name "is none"
sh -x ./${script}
fi
done
//4.要定时执行,所以可以使用crontab定时调度
vi /etc/crontab
* * * * * root /bin/bash /data/soft/monlist.sh
第8周 数据仓库工具-(Hive + Hue)
1、快速了解Hive
Hive 是基于 Hadoop 个数据仓库工具,可以将类 SQL 语句转换为 MapReduce 务进行运行。其优点是学习成本低,可以通过类 SQL
语句快速实现简单的 MapReduce 统计,不必开发专门的MapReduce 应用。
Hive是建立在Hadoop上的数据仓库基础构架。
它提供了一系列的工具,可以用来进行数据提取、转化、加载(简称为ETL)。
- Hive 定义了简单的类SQL查询语言,称为HQL,它允许熟悉SQL的用户直接查询Hadoop中的数据;
- Hive中包含的有SQL解析引擎,它会将SQL语句转译成M/R Job,然后在Hadoop中执行。
- 所以hivee的数据存储是基于hadoop的。
HQL也允许熟悉MapReduce的开发者开发自定义的mapreduce任务来处理内建的SQL函数无法完成的复杂的分析任务。
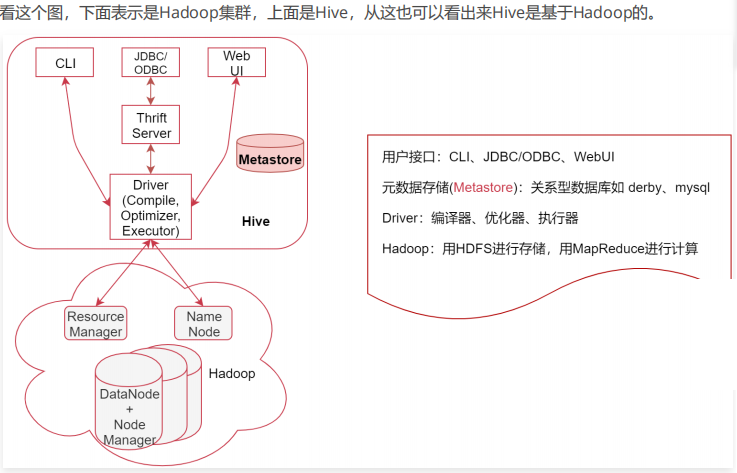
Hive 的数据存储在 HDFS 中,大部分的查询由 MapReduce 完成(特例 select * from table 不会生成 MapRedcue 任务,如果在SQL语句后面再增加where过滤条件就会生成MapReduce任务了。)
Metastore 是Hive元数据的集中存放地。
- 默认使用内嵌的derby数据库,缺点:在同一个目录下一次只能打开一个会话;
- 推荐使用MySQL作为外置存储引擎,可以支持多用户同时访问以及元数据共享。
2、数据库和数据仓库的区别
数据库与数据仓库的本质区别就是 OLTP与OLAP 的区别
- oLTP(On-Line Transaction Processing):操作型处理,称为联机事务处理,也可以称为面向交易的处理系统,支持增删改查这些常见的事务操作
- OLAP(On-Line Analytical Processing):分析型处理,称为联机分析处理,一般针对某些主题历史数据进行分析,支持管理决策。只支持查询操作,不支持修改和删除;
| 对比项 | HIVE | MySQL |
|---|---|---|
| 数据存储位置 | HDFS | 本地磁盘 |
| 数据格式 | 用户定义 | 系统决定 |
| 数据更新 | 不支持(不支持修改和删除) | 支持(支持增删改查) |
| 索引 | 有,但较弱,一般很少用 | 有,经常使用的 |
| 执行 | MapReduce | Executor |
| 执行延迟 | 高 | 低 |
| 可扩展性 | 高 | 低 |
| 数据规模 | 大 | 小 |
3、Hive安装部署
//1.下载大版本和hadoop保持一致:https://downloads.apache.org/hive/
apache归档的软件包含各种历史版本: https://archive.apache.org/dist/
//2.Hive相当于Hadoop的客户端工具,安装在hadoop客户端节点也可:上传、解压
//3.修改配置
# 先对这两个模板文件重命名
[root@bigdata04 soft]# cd apache-hive-3.1.2-bin/conf/
[root@bigdata04 conf]# mv hive-env.sh.template hive-env.sh
[root@bigdata04 conf]# mv hive-default.xml.template hive-site.xml
# 然后再修改这两个文件的内容
# 3.1 hive-env.sh 文件的末尾直接增加
export JAVA_HOME=/data/soft/jdk1.8
export HIVE_HOME=/data/soft/apache-hive-3.1.2-bin
export HADOOP_HOME=/data/soft/hadoop-3.2.0
# 3.2 修改hive-site.xml里面需要指定Metastore的地址,Metastore使用Mysql,所以需要提前安装好mysql
[root@bigdata04 conf]# vi hive-site.xml
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://192.168.145.1:3306/hive?serverTimezone=Asia/Shanghai</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.cj.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>root</value>
</property>
<property>
<name>hive.querylog.location</name>
<value>/data/hive_repo/querylog</value>
</property>
<property>
<name>hive.exec.local.scratchdir</name>
<value>/data/hive_repo/scratchdir</value>
</property>
<property>
<name>hive.downloaded.resources.dir</name>
<value>/data/hive_repo/resources</value>
</property>
//4.上传mysql驱动包mysql-connector-java-8.0.16.jar到hive/lib目录下
//5.修改bigdata128中的core-site.xml,然后同步到集群中的另外两个节点上
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
[root@bigdata128 hadoop]# scp -rq /data/sof/hadoop-3.2.0/etc/hadoop/core-site.xml bigdata129:/data/sof/hadoop-3.2.0/etc/hadoop/
[root@bigdata128 hadoop]# scp -rq /data/sof/hadoop-3.2.0/etc/hadoop/core-site.xml bigdata130:/data/sof/hadoop-3.2.0/etc/hadoop/
//6.重启Hadoop集群
[root@bigdata128 hadoop-3.2.0]# sbin/stop-all.sh
[root@bigdata128 hadoop-3.2.0]# sbin/start-all.sh
//7.mysql 新建database "hive"
注意:编码最好使用latin-1,utf-8有时会有问题??
//8.初始化Hive的Metastore
[root@bigdata04 apache-hive-3.1.2-bin]# bin/schematool -dbType mysql -initSchema
执行之后发现报错了,提示hive-site.xml文件中的第3215行内容有问题<description>内容格式问题,删除即可
重新初始化Hive的Metastore,需要执行一会,完成后会在mysql中hive库生成相关表;
目前针对Hive不需要启动任何进程,安装完成。
4、Hive使用方式之命令行方式
- bin/hive【官方不推荐使用】
1.链接:[root@bigdata04 apache-hive-3.1.2-bin]# bin/hive
2.查表:show tables;
3.创建表:create table t1(id int,name string);
4.插数据:insert into t1(id,name) values(1,"zs"); //实际是执行了一个mapreduce任务
5.查询:select * from t1;
6.删表:drop table t1;
7.退出:quit;
- beeline命令,通过HiveServer2连接hive,轻量级客户端工具:bin/beeline -u jdbc:hive2://localhost:10000 -n root
//开启服务: [root@bigdata04 apache-hive-3.1.2-bin]# bin/hiveserver2
1.链接:bin/beeline -u jdbc:hive2://localhost:10000 -n root //在启动beeline的时候指定一个对这个目录有操作权限的用户
2.查表:show tables;
3.创建表:create table t1(id int,name string);
4.插数据:insert into t1(id,name) values(1,"zs"); //实际是执行了一个mapreduce任务
5.查询:select * from t1;
6.删表:drop table t1;
7.退出:quit;
在工作中我们如果遇到了每天都需要执行的命令,那我肯定想要把具体的执行sql写到脚本中去执行,但是现在这种用法每次都需要开启一个会话,好像还没办法把命令写到脚本中。
- hive后面可以使用 -e 命令,就可以放到shell脚本中执行了,这样每次hive都会开启一个新的会话,执行完毕以后再关闭这个会话。
5、Hive使用方式之JDBC方式
- 需要先开启Hive 远程服务【端口号默认为10000】, 启动方式:bin/hiveserver2
- 案例:在Java代码中通过Hive的JDBC建立连接
//1.添加hive-jdbc的依赖
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-jdbc</artifactId>
<version>3.1.2</version>
<exclusions>
<!-- 去掉 log4j依赖 -->
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
</exclusions>
</dependency>
//2.实现
/**
* JDBC代码操作 Hive
* 注意:需要先启动hiveserver2服务
* Created by xuwei
*/
public class HiveJdbcDemo {
public static void main(String[] args) throws Exception{
//指定hiveserver2的连接
String jdbcUrl = "jdbc:hive2://192.168.182.103:10000";
//获取jdbc连接,这里的user使用root,就是linux中的用户名,password随便指定即
Connection conn = DriverManager.getConnection(jdbcUrl, "root", "any")
//获取Statement
Statement stmt = conn.createStatement();
//指定查询的sql
String sql = "select * from t1";
//执行sql
ResultSet res = stmt.executeQuery(sql);
//循环读取结果
while (res.next()){
System.out.println(res.getInt("id")+"\t"+res.getString("name"));
}
}
//3.在项目的resources目录中增加log4j2.xml配置文件
<?xml version="1.0" encoding="UTF-8"?>
<Configuration status="INFO">
<Appenders>
<Console name="Console" target="SYSTEM_OUT">
<PatternLayout pattern="%d{YYYY-MM-dd HH:mm:ss} [%t] %-5p %c{1}:%
</Console>
</Appenders>
<Loggers>
<Root level="info">
<AppenderRef ref="Console" />
</Root>
</Loggers>
</Configuration>
6、Set命令的使用 hive命令行中可以使用set命令临时设置一些参数的值,其实就是临时修改hive-site.xml中参数的值
- Hive命令行下执行set命令【仅当前会话有效】
- Hive脚本 ~/.hiverc 中配置set命令【当前机器有效】
- 如何查看Hive历史操作命令:[root@bigdata04 apache-hive-3.1.2-bin]# more ~/.hivehistory
7、Hive的日志配置
- Hive运行时日志
- Hive任务执行日志
[root@bigdata04 conf]# mv hive-log4j2.properties.template hive-log4j2.properties
[root@bigdata04 conf]# mv hive-log4j2.properties.template hive-log4j2.propert
[root@bigdata04 conf]# vi hive-log4j2.properties
property.hive.log.level = WARN
property.hive.root.logger = DRFA
property.hive.log.dir = /data/hive_repo/log
property.hive.log.file = hive.log
property.hive.perflogger.log.level = INFO
修改 hive-exec-log4j2.properties.template 这个文件,去掉 .template 后缀
[root@bigdata04 conf]# vi hive-exec-log4j2.properties
property.hive.log.level = WARN
property.hive.root.logger = FA
property.hive.query.id = hadoop
property.hive.log.dir = /data/hive_repo/log
property.hive.log.file = ${sys:hive.query.id}.log
8、Hive中数据库的操作
- 创建数据库 :create database mydb1;
- 创建数据库的时候通过location来指定hdfs目录的位置:create database mydb2 location ‘/user/hive/mydb2’;
- 查看数据库列表 :show databases;
- 选择数据库: use default;
- 删除数据库: drop database mydb1;
9、Hive中表的操作 :表中的数据是存储在hdfs中的,但是表的名称、字段信息是存储在metastore中的
- 创建表:create table t2(id int);
- 查看表结构信息: desc t2;
- 显示当前数据库中所有的表名:show tables;
- 查看表的创建信息: show create table t2;
- 修改表名 :alter table t2 rename to t2_bak;
- 加载数据(批量插数据): load data local inpath ‘/data/soft/hivedata/t2.data’ into table default.t2_bak
- (hdfs命令加载数据)自己手工通过put命令把数据上传到t2_bak目录中:[root@bigdata04 hivedata]# hdfs dfs -put /data/soft/hivedata/t2.data /user/hive/warehouse/t2_bak/t2_bak-2.data
- 表增加字段及注释、删除表: alter table t2_bak add columns (name string);
- 指定列和行的分隔符 :hive是有默认的分隔符的,默认的行分隔符是 ‘\n’ ,就是换行符,而默认的列分隔符呢,是 \001 。
创建表的时候指定一下分隔符
create table t3_new(
id int comment 'ID',
stu_name string comment 'name',
stu_birthday date comment 'birthday',
online boolean comment 'is online'
)row format delimited
fields terminated by '\t'
lines terminated by '\n';
10、Hive中数据类型的应用
hive作为一个类似数据库的框架,也有自己的数据类型,便于存储、统计、分析。Hive中主要包含两大数据类型
- 基本数据类型:常用的有INT,STRING,BOOLEAN,DOUBLE等
- 复合数据类型:常用的有ARRAY,MAP,STRUCT等
示例1: 建一张表,指定了一个array数组类型的字段叫favors, 一个map字段score
//建表
create table stu(
id int,
name string,
favors array<string>,
scores map<string,int>
)row format delimited
fields terminated by '\t'
collection items terminated by ','
map keys terminated by ':'
lines terminated by '\n';
//数据test2.data
1 zhangsan swing,sing,coding chinese:80,math:90,english:100
2 lisi music,football chinese:89,english:70,math:88
//load 数据
load data local inpath '/data/soft/hivedata/test2.data' into table default.stu2
//.查询所有学生的语文和数学成绩
select id,name,scores['chinese'],scores['math'] from stu2;
示例2:种复合类型struct,某学校有2个实习生,zhangsan、lisi,每个实习生都有地址信息,一个是户籍地所在的城市,一个是公司所在的城市
//建表
create table stu3(
id int,
name string,
address struct<home_addr:string,office_addr:string>
)row format delimited
fields terminated by '\t'
collection items terminated by ','
lines terminated by '\n';
//数据test3.data
1 zhangsan bj,sh
2 lisi gz,sz
//load 数据
load data local inpath '/data/soft/hivedata/test3.data' into table default.stu3
//.查询地址
select id,name,address.home_addr from stu3;
Struct和Map的区别 如果从建表语句上来分析,其实这个Struct和Map还是有一些相似之处的来总结一下:
map中可以随意增加k-v对的个数
struct中的k-v个数是固定的
map在建表语句中需要指定k-v的类型
struct在建表语句中需要指定好所有的属性名称和类型
map中通过[]取值
struct中通过.取值,类似java中的对象属性引用
map的源数据中需要带有k-v
struct的源数据中只需要有v即可
11、Hive表类型之内部表 + 外部表
内部表: 也可以称为受控表, Hive中的默认表类型
- 表数据默认存储在 warehouse 目录中
- 在加载数据的过程中,实际数据会被移动到 warehouse目录中
- 删除表时,表中的数据和元数据将会被同时删除
外部表 :建表语句中包含 External 的表叫外部表
- 外部表在加载数据的时候,实际数据并不会移动到warehouse目录中,只是与外部数据建立一个链接(映射关系)
- 表的定义和数据的生命周期互相不约束,数据只是表对hdfs上的某一个目录的引用而已,
- 当删除表定义的时候,只会删除表的元数据, 数据依然是存在的。仅删除表和数据之间引用关系
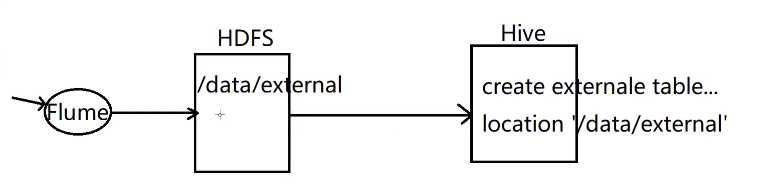
//主要就是在建表语句中增加了EXTERNAL 以及在最后通过locatin指定了这个表数据的存储位置,注意这个路径是hdfs的路径
create external table external_table (
key string
) location '/data/external';
//此时到hdfs的 /user/hive/warehouse/ 目录下查看,是看不到这个表的目录的,因为这个表的目录是刚才通过location指定的目录
//metastore中的tbls表,这里看到external_table的类型是外部表
//原始数据文件为 external_table.data
//往这个外部表中加载数据,原始数据文件为 external_table.data
load data local inpath '/data/soft/hivedata/external_table.dat into table external_t1
此时加载的数据会存储到hdfs的 /data/external 目录下
注意:实际上内外部表是可以互相转化的,需要我们做一下简单的设置即可。
内部表转外部表
alter table tblName set tblproperties (‘external’=‘true’);
外部表转内部表
alter table tblName set tblproperties (‘external’=‘false’);
在实际工作中,我们在hive中创建的表95%以上的都是外部表 大致流程:
我们先通过flume采集数据,把数据上传到hdfs中,然后在hive中创建外部表和hdfs上的数据绑定关系,就可以使用sql查询数据了,所以连load数据那一步都可以省略了,因为是先有数据,才创建的表
12、Hive表类型之内部分区表
引入
假设我们的web服务器每天都产生一个日志数据文件,Flume把数据采集到HDFS中,每一天的数据存储 到一个日期目录中。我们如果想查询某一天的数据的话,hive执行的时候默认会对所有文件都扫描一遍,然后再过滤出来我们想要查询的那一天的数据
如果你已经采集了一年的数据,这样每次计算都需要把一年的数据取出来,再过滤出来某一天的数据,效率就太低了,会非常浪费资源,
所以我们可以让hive在查询的时候,根据你要查询的日期,直接定位到对应的日期目录。这样就可以直接查询满足条件的数据了,效率提升可不止一点点啊,是质的提升
分区可以理解为分类,通过分区把不同类型的数据放到不同目录中 分区的标准就是指定分区字段,分区字段可以有一个或多个,根据咱们刚才举的例子,分区字段就是日期 分区表的意义在于优化查询,查询时尽量利用分区字段,如果不使用分区字段,就会全表扫描,最典型的一个场景就是把天作为分区字段,查询的时候指定天
//建表
hive (default)>create table partition_1 (
id int,
name string
) partitioned by (dt string)
row format delimited
fields terminated by '\t';
//data partition_1.data
1 zhangsan
2 lisi
//load data
hive (default)>load data local inpath '/data/soft/hivedata/partition_1.data' into table default.partition_1 partition (dt=20200101)
//看一下hdfs中的信息,刚才创建的分区信息在hdfs中的体现是一个目录:/user/hive/warehouse/partition_1/dt=2020-01-01
//手动在表中只创建分区
hive (default)> alter table partition_1 add partition (dt='2020-01-02');
//向这个新建分区中添加数据,可以使用刚才的load命令或者hdfs的put命令都可以
hive (default)> load data local inpath '/data/soft/hivedata/partition_2.data' into table default.partition_1 partition (dt=20200102)
// 查看表中有哪些分区
hive (default)>show partitions partition_1;
创建多个分区
某学校,有若干二级学院,每年都招很多学生,学校的统计需求大部分会根据年份和学院名称作为条件
所以为了提高后期的统计效率,我们最好是使用年份和学院名称作为分区字段
//建分区表
create table partition_2 (
id int,
name string
) partitioned by (year int, school string)
row format delimited
fields terminated by '\t';
// partition_2.data 数据文件中只需要有id和name这两个字段的值就可以了,具体year和school这两个分区字段是在加载分区的时候指定的。
1 zhangsan
2 lisi
3 wangwu
// load
hive (default)> load data local inpath '/data/soft/hivedata/partition_2.data' into table default.partition_2 partition (year=2020, school=JSJ)
hive (default)> load data local inpath '/data/soft/hivedata/partition_2.data' into table default.partition_2 partition (year=2019, school=JSJ)
hive (default)> load data local inpath '/data/soft/hivedata/partition_2.data' into table default.partition_2 partition (year=2020, school=YY)
hive (default)> load data local inpath '/data/soft/hivedata/partition_2.data' into table default.partition_2 partition (year=2019, school=YY)
//查看分区信息
hive (default)> show partitions partition_2;
OK
partition
year=2019/school=english
year=2019/school=xk
year=2020/school=english
year=2020/school=xk
//查询
select * from partition_2; 【全表扫描,没有用到分区的特性】
select * from partition_2 where year = 2019;【用到了一个分区字段进行过滤】
select * from partition_2 where year = 2019 and school = 'YY';【用到了两个分区字段进行过滤】
13、Hive表类型之外部分区表 外部分区表就是在外部表的基础上又增加了分区–工作中最常用的表
//建分区表
create external table ex_par (
id int,
name string
) partitioned by (year int, school string)
row format delimited
fields terminated by '\t'
location '/data/ex_par';
//load data
load data local inpath '/data/soft/hivedata/ex_par.data' into table ex_par partation(dt='20200101')
//删除分区:删除后虽然分区目录还在,show partitions 已查不到分区信息了,查询表数据是查不出来的,由于这个是一个分区表,这份数据没有和任何分区绑定,所以就查询不出来
hive (default)> alter table ex_par drop partition(dt='2020-01-01');
//数据已经上传上去后,需要通过alter add partition命令 ,指定分区目录location
hive (default)> alter table ex_par add partition(dt='20200101') location '/data/ex_par/dt=20200101'
总结一下:
load data local inpath '/data/soft/hivedata/ex_par.data' into table ex_par partation(dt='20200101')
这条命令做了两件事情,上传数据,添加分区(绑定数据和分区之间的关系)
hdfs dfs -mkdir /data/ex_par/dt=20200101
hdfs dfs -put /data/soft/hivedata/ex_par.data /data/ex_par/dt=20200101
alter table ex_par add partition(dt='20200101') location '/data/ex_par/dt=20200101'
上面这三条命令做了两个事情,上传数据,添加分区(绑定数据和分区之间的关系)
14-1、Hive表类型之桶表(实际用的少)
- 桶表是对数据进行哈希取值,然后放到不同文件中存储
- 物理上,每个桶就是表(或分区)里的一个文件
- 桶表的主要作用:1. 数据抽样 2. 提高某些查询效率如join操作
//创建桶表
create table bucket_tb(
id int
) clustered by (id) into 4 buckets; //分到4个桶
往桶中加载数据:不能使用load data的方式,而是需要使用其它表中的数据
//1.在插入数据之前需要先设置开启桶操作
hive (default)> set hive.enforce.bucketing=true;
//2.初始化一个表b,用于向桶表中加载数据
more b_source.data
1
2
3
4
//3.建b
hive (default)> create table b_source(id int);
//4.load数据到b
hive (default)> load data local inpath '/data/soft/hivedata/b_source.data' into table b_source
//5.向桶表中加载数据
hive (default)> insert into table bucket_tb select id from b_source
//6.查看桶表中的数据
hive (default)> select * from bucket_tb;
14-2、Hive表类型之视图
//创建视图
hive (default)>create view v1 as select t3_new.id,t3_new.stu_name from t3_new
//查看到这个视图,但是仓库里么有相应的文件或目录,虚拟的
hive (default)>show tables
//通过视图查询数据
hive (default)> select * from v1;
//查看视图的结构,
hive (default)> desc v1;
15、Hive数据处理综合案例
需求:Flume按天把日志数据采集到HDFS中的对应目录中,使用SQL按天统计每天数据的相关指标
分析一下:
日志采集:Flume按天把日志数据保存到HDFS中的对应目录中
针对Flume的source可以使用execsource、channel可以使用基于文件的或者内存的,sink使用hdfssink,
在hdfssink的path路径中需要使用%Y%m%d获取日期,将每天的日志数据采集到指定的hdfs目录中
建表:
由于这份数据可能会被多种计算引擎使用,所以建议使用外部表,这样就算我们不小心把表删了,数据也还是在的
还有就是这份数据是按天分目录存储的,在实际工作中,离线计算的需求大部分都是按天计算的,所以在这里最好在表中增加日期这个分区字段
所以最终决定使用外部分区表。
实现思路:
1.先基于原始的json数据创建一个外部分区表,表中只有一个字段,保存原始的json字符串即可,分区字段是日期和数据类型
2.再创建一个视图,视图中实现的功能就是查询前面创建的外部分区表,在查询的时候会解析json数据中的字段
//1.创建一个外部分区表
create external table ex_par_more_type(
log string
)partitioned by(dt string,d_type string)
row format delimited
fields terminated by '\t'
location '/moreType';
//2.加载数据:注意,此时数据已经通过flume采集到hdfs中了,不需要使用load命令了,只需要使用一个alter命令添加分区信息就可以
hive (default)> alter table ex_par_more_type add partition(dt='20200504',d_type='giftRecord') location '/moreType/20200504/giftRecord'
hive (default)> alter table ex_par_more_type add partition(dt='20200504',d_type='userInfo') location '/moreType/20200504/userInfo'
hive (default)> alter table ex_par_more_type add partition(dt='20200504',d_type='videoInfo') location '/moreType/20200504/videoInfo'
//3.创建视图,创建视图时从数据中查询需要的字段信息
由于这三种类型的数据字段是不一样的,所以创建一个视图还搞不定,只能针对每一种类型创建一个视图
create view gift_record_view as
select get_json_object(log,'$.send_id') as se
,get_json_object(log,'$.good_id') as good_id
,get_json_object(log,'$.video_id') as video_id
,get_json_object(log,'$.gold') as gold
,dt
from ex_par_more_type
where d_type = 'giftRecord';
create view user_info_view as select get_json_object(log,'$.uid') as uid
,get_json_object(log,'$.nickname') as nickname
,get_json_object(log,'$.usign') as usign
,get_json_object(log,'$.sex') as sex
,dt
from ex_par_more_type
where d_type = 'userInfo';
create view video_info_view as select get_json_object(log,'$.id') as id
,get_json_object(log,'$.uid') as uid
,get_json_object(log,'$.lat') as lat
,get_json_object(log,'$.lnt') as lnt
,dt
from ex_par_more_type
where d_type = 'videoInfo';
//4.查询视图,指定日期查询
hive (default)> select * from gift_record_view where dt = '20200504';
//5.定时任务addPartition.sh:flume每天都会采集新的数据上传到hdfs上面,所以我们需要每天都做一次添加分区的操作。
00 01 * * * root /bin/bash /data/soft/hivedata/addPartition.sh >> /data/soft/hivedata/addPartition.log
[root@bigdata04 hivedata]# vi addPartition.sh
#!/bin/bash
# 每天凌晨1点定时添加当天日期的分区
if [ "a$1" = "a" ]
then
dt=`date +%Y%m%d`
else
dt=$1
fi
# 指定添加分区操作: 如果指定的分区已存在,重复添加分区会报错,所以增加判断if not exists
hive -e "
alter table ex_par_more_type add if not exists partition(dt='${dt}',d_type='giftRecord') location '/moreType/${dt}/giftRecord'
alter table ex_par_more_type add if not exists partition(dt='${dt}',d_type='userInfo') location '/moreType/${dt}/userInfo'
alter table ex_par_more_type add if not exists partition(dt='${dt}',d_type='videoInfo') location '/moreType/${dt}/videoInfo'
"
16、Hive高级函数 通过 show functions; 来查看hive中的内置函数,mysql中支持的函数这里面大部分都支持
16-1、Hive高级函数之分组排序取TopN
row_number和over函数通常搭配在一起使用
- row_number会对数据编号,编号从1开始
- over可以理解为把数据划分到一个窗口内,里面可以加上partition by,表示按照字段对数据进行分组,
- 可以加上order by 表示对每个分组内的数据按照某个字段进行排序
需求:有一份学生的考试分数信息,语文、数学、英语这三门,需要计算出班级中单科排名前三名学生的姓名
//1.准备数据student_score.data
[root@bigdata04 hivedata]# more student_score.data
1 zs1 chinese 80
2 zs1 math 90
3 zs1 english 89
4 zs2 chinese 60
5 zs2 math 75
6 zs2 english 80
7 zs3 chinese 79
8 zs3 math 83
9 zs3 english 72
10 zs4 chinese 90
11 zs4 math 76
12 zs4 english 80
13 zs5 chinese 98
14 zs5 math 80
15 zs5 english 70
//2.建表
create external table student_score(
id int,
name string,
sub string,
score int
)row format delimited
fields terminated by '\t'
location '/data/student_score';
//3.load数据
[root@bigdata04 hivedata]# hdfs dfs -put /data/soft/hivedata/student_score.dat /data/student_score
//4.分组排序查询
hive (default)> select *, row_number() over (partition by sub order by score desc) as num from student_score;
//5.分组排序查询, 每科取前三
hive (default)> select * from(
select *, row_number() over (partition by sub order by score desc) as num from student_score
) where num <=3;
//6.排名:rank() over() 是跳跃排序,有两个第一名时接下来就是第三名(在各个分组内)
hive (default)> select *, rank() over (partition by sub order by score desc) as num from student_score;
//7.排名:dense_rank() over() 是连续排序,有两个第一名时仍然跟着第二名(在各个分组内)
hive (default)> select *, dense_rank() over (partition by sub order by score desc) as num from student_score;
16-2、Hive高级函数之行转列(把多行数据转为一列数据)
行转列这种需求主要需要使用到
- CONCAT_WS():指定的分隔符拼接多个字段的值,最终转化为一个带有分隔符的字符串
- COLLECT_SET():返回一个list集合,集合中的元素会重复,一般和group by 结合在一起使用
- COLLECT_LIST(): 返回一个set集合,集合汇中的元素不重复,一般和group by 结合在一起使用
//1.测试数据student_favors.data
[root@bigdata04 hivedata]# more student_favors.data
zs swing
zs footbal
zs sing
zs codeing
zs swing
//2.建表
create external table student_favors(
name string,
favor string
)row format delimited
fields terminated by '\t'
location '/data/student_favors';
//3.load数据
[root@bigdata04 hivedata]# hdfs dfs -put /data/soft/hivedata/student_favors.data /data/student_favors
//4.分组、聚合、拼接
hive (default)> select name,concat_ws(',',collect_list(favor)) as favor_list from student_favors group by namep;
//collect去重
hive (default)> select name,concat_ws(',',collect_set(favor)) as favor_list from student_favors group by namep;
16-3、Hive高级函数之列转行(把一列数据转成多行)
主要使用到
- SPLIT():字串符切割成数组
- EXPLODE():数可以接受array或者map
- explode(ARRAY):表示把数组中的每个元素转成一行
- explode(MAP) :表示把map中每个key-value对,转成一行,key为一列,value为一列
- LATERAL VIEW: 通常和split, explode等函数一起使用,可以对这份数据产生一个支持别名的虚拟表
//1.测试数据student_favors_2.data
[root@bigdata04 hivedata]# more student_favors_2.data
zs swing,footbal,sing
ls codeing,swing
//2.建表
create external table student_favors_2(
name string,
favorlist string
)row format delimited
fields terminated by '\t'
location '/data/student_favors_2';
//3.load数据
[root@bigdata04 hivedata]# hdfs dfs -put /data/soft/hivedata/student_favors_2.data /data/student_favors_2
//4.拆分、列转行、拼其他列
select name,favor_new from student_favors_2 lateral view explode(split(favorlist,',')) from student_favors_2;
16-4、Hive的排序函数
- order by跟sql语言中的order by作用是一样的,会对查询的结果做一次全局排序,使用这个语句的时候生成的reduce任务只有一个
- sort by,如果有多个reduce,在每个reducer端都会做排序,保证了局部有序(每个reducer出来的数据是有序的,但不能保证所有的数据是全局有序的,除非只有一个reducer)
- ditribute by:只会根据指定的key对数据进行分区,但是不会排序。一般情况下可以和sort by 结合使用,先对数据分区,再进行排序
- cluster by:的功能就是distribute by和sort by的简写形式( cluster by id 等于 distribute by id sort by id)
16-5、Hive的分组和去重函数
- GROUP BY :对数据按照指定字段进行分组
- DISTINCT:对数据中指定字段的重复值进行去重
16-6、一个SQL语句分析-数据倾斜问题

17、Hive的Web工具-HUE
- Hue-非技术人员操作Hive的利器
- 在Hue中提交Hive任务,查看任务执行结果