数据库基础、sql优化、数据库优化、数据库运维
参考资料
一、数据库基础
1.1 基础概念介绍
- 数据库服务器:安装数据库实例的机器(计算机)
- 实例:数据库服务,用于创建数据库,存储并提供数据
- 数据库DB(Database ):是按照数据结构来组织、存储和管理数据的仓库
- 外模式:用户级,也称用户模式,一般对应于SQL的视图
- 模式:对数据库所有用户的数据的整体逻辑描述,对应于基本表
- 内模式:物理级,又称为存储模式,对应于存储文件
- 表:表是记录的集合
- 记录:用来描述一个实体
- 字段:用来表示实体的具体属性
- E-R图:即用实体、属性、联系来描述现实世界的概念模型
- DBMS(DataBase Management System)是数据库管理系统 ,Mysql、Oracle、Postgresql、MS SQLSever …
- DBA(Database Administrator)是数据库管理员,是从事管理和维护数据库管理系统(DBMS) 的相关工作人员的统称,属于运维工程师的一个分支,主要负责业务数据库从设计、测试到部署交付的全生命周期管理
1.2 范式介绍
NF的意义:
Normal form作为设计的标准范式,其最大的意义就是为了避免数据的冗余和插入/删除/更新的异常
- 1NF:符合1NF的关系中的每个属性(表中的字段)都不可再分,1NF是所有关系型数据库的最基本要求
- 2NF:满足1NF,表中的字段必须完全依赖于全部主键而非部分主键 (一般我们都会做到)
- 3NF:满足2NF,非主键外的所有字段必须互不依赖,非主属性不传递依赖于主键,消除非主属性之间的依赖关系,只保留非主属性与主键的依赖关系。
- BCNF:
1.3 数据字典
1.4 用户及权限
用户:数据库用户即使用和共享数据库资源的人(账号),数据库用户的权限分为三类:
- 1、在当前数据库中创建数据库对象及进行数据库备份的权限,
- 主要有:创建表、视图、存储过程、规则、默认值对象、函数的权限及执行存储过程的权限。
- 2、用户对数据库表的操作权限及执行存储过程的权限,主要有:
- 对表或试图执行SELECT,INSERT,DELETE,UPDATE语句的权限;
- REFERENCES:用户对表的主键和唯一索引字段生成外码引用的权限;
- EXECUTE:执行存储过程的权限。
- 3、用户数据库中指定表字段的操作权限,
- 主要有: 对表字段进行SELECT、UPDATE操作的权限;
示例:
http://www.cnblogs.com/stephen-liu74/archive/2012/05/18/2302639.html
--创建用户、密码:
create user adminUser password '123456';
--创建用户:
create user adminUser;
--修改密码:
alter user adminUser password '123456';
--授权库、模式、表给用户:
grant all on DATABASE db_demo to adminUser
grant all on SCHEMA sch_test to adminUser
grant all on all tables in schema sch_test to adminUser;
-- 给'角色'授权
alter role testrole createrole;
alter role testrole createdb;
alter role testrole replication;
alter role testrole bypassrls;
1.5 SQL四种语言:DDL、DML、DCL、TCL
- 数据定义(SQL DDL)用于定义SQL模式、基本表、视图和索引的创建和撤消操作。
- 数据操纵(SQL DML)数据操纵分成数据查询和数据更新两类。数据更新又分成插入、删除、和修改三种操作。
- 数据控制(SQL DCL)包括对基本表和视图的授权,完整性规则的描述,事务控制等内容。
- 事务控制(Transaction Control Language)事务控制语言。
1.DDL(Data Definition Language)数据库定义语言used to define the database structure or schema.
DDL是SQL语言的四大功能之一。
用于定义数据库的三级结构,包括外模式、概念模式、内模式及其相互之间的映像,定义数据的完整性、安全控制等约束
DDL不需要commit.
CREATE
ALTER
DROP
TRUNCATE
COMMENT
RENAME
2.DML(Data Manipulation Language)数据操纵语言used for managing data within schema objects.
由DBMS提供,用于让用户或程序员使用,实现对数据库中数据的操作。
DML分成交互型DML和嵌入型DML两类。
依据语言的级别,DML又可分成过程性DML和非过程性DML两种。
需要commit.
SELECT
INSERT
UPDATE
DELETE
MERGE
CALL
EXPLAIN PLAN
LOCK TABLE
3.DCL(Data Control Language)数据库控制语言 授权,角色控制等
GRANT 授权
REVOKE 取消授权
4.TCL(Transaction Control Language)事务控制语言
SAVEPOINT 设置保存点
ROLLBACK 回滚
SET TRANSACTION
1.6 UUID
--oracle
SELECT sys_guid() FROM db_test.t_student;
--postgresql
INSERT INTO t_student VALUES( uuid_generate_v4(), NULL, NULL);
SELECT uuid_generate_v1() FROM db_test.t_student;
1.7 数据库锁机制、事务
参考:
定义:
锁是计算机协调多个进程或线程并发访问同一资源的机制。所以,锁是一种机制,是在多个事务并发访问同一资源时起协调作用的。
数据库中的数据也是一种资源,当多个事务同时去修改同一条数据时,就有可能导致数据不一致的问题。因此我们需要一种机制来将事务对数据的访问顺序化,以保证数据库数据的一致性,这种机制就是锁机制。
数据库事务的隔离性就是通过锁机制来实现的。
分类:
按照锁的粒度来说,MySQL中各存储引擎使用了三种类型的锁机制:行级锁、表级锁、页级锁。
- 1.行级锁:开销大,加锁慢; 可能出现死锁;锁定粒度最小,发生锁冲突的概率最低, 并发度也最高;
- 2.表级锁:开销小,加锁快; 不会出现死锁(如MyISAM引擎是不会出现死锁的);锁定粒度大,发生锁冲突的概率最高, 并发度最低,可能导致超时;
- 3.页级锁:介于行锁和表锁之间
MySQL常用的存储引擎对应的锁机制:
- MyISAM采用表级锁;
- InnoDB(MySQL使用最频繁的存储引擎)支持行级锁和表级锁,默认采用行级锁;
- BDB支持页级锁和表级锁,默认采用页级锁;(实际上在5.1版本后,MySQL就不再支持BDB存储引擎了,因为BDB被Oracle收购了,此处了解一下支持页级锁的存储引擎有BDB即可)
共享(读)锁 & 排他(写)锁:
- 共享锁:又称为读锁或S锁,是在进行读取操作时创建的锁
- 事务A对数据D加了S锁后,其他任何事务只能对数据D加S锁,不能加X锁。即允许其他事物进行读操作,但是不允许事务A在内的任何事务对数据进行修改。 即”我读的时候,你也能读,但我们大家都不能写”。
- 排他锁:又称为写锁或X锁,是在进行写操作(增、删、改)时创建的锁
- 事务A对数据D加上X锁之后,其他事务对数据D既不能加S锁,也不能加X锁;获得排他锁的事务既能读数据,也能写数据(增、删、改)。 即”我在”读写”的时候,你既不能读,也不能写”
什么时候会加锁:
- 对于select操作,InnoDB不会对数据加任何锁,如果需要,事务可以给select操作显式的加共享锁或排他锁
- 对于写操作(insert、update、delete),InnoDB会自动给涉及的数据加X锁;
共享锁:select ... lock in share mode;
在select语句后面加lock in share mode,MySQL会对查询结果中的每行都加S锁。
如:select * from t_course where course_type='course_type1' lock in share mode;此时其他事务可以对锁定的数据加S锁,但不能加X锁,否则会被阻塞。
排他锁:select ... for update;
在select语句后面加for update,MySQL会对查询结果中的每行都加X锁。
如:select * from t_course where course_type='course_type2' for update;此时其他事务既不能对锁定的数据加S锁,也不能加X锁
1.8 视图
1.视图定义:在 SQL 中,视图是基于 SQL 语句的结果集的可视化的表。
- 视图包含行和列,就像一个真实的表。
- 视图中的字段就是来自一个或多个数据库中的真实的表中的字段。
- 我们可以向视图添加 SQL 函数、WHERE 以及 JOIN语句,我们也可以提交数据,就像这些来自于某个单一的表。
注释:数据库的设计和结构不会受到视图中的函数、where 或 join 语句的影响。
2.视图的特点。
- 视图中的数据并不属于视图本身,而是属于基本的表,对视图可以像表一样进行insert,update,delete操作。
- 视图不能被修改,表修改或者删除后应该删除视图再重建。
- 视图的数量没有限制,但是命名不能和视图以及表重复,具有唯一性。
- 视图可以被嵌套,一个视图中可以嵌套另一个视图。
- 视图不能索引,不能有相关联的触发器和默认值,sql server不能在视图后使用order by排序。
3.视图操作示例
创建视图:
CREATE VIEW view_name AS
SELECT column_name(s) FROM table_name
WHERE condition
删除视图:
DROP VIEW view_name
1.9 函数
- 分区函数
- 分组函数
- 聚合函数
- 自定义函数使用
mysql:创建function
1.查看mysql创建函数的功能是否开启:
mysql> show variables like '%func%';
2.如果Value处值为OFF,则需将其开启
mysql> set global log_bin_trust_function_creators=1;
3.创建函数
DELIMITER $$
DROP FUNCTION IF EXISTS genPerson$$
CREATE FUNCTION genPerson(name varchar(20)) RETURNS varchar(50)
BEGIN
DECLARE str VARCHAR(50) DEFAULT '';
SET @tableName=name;
SET str=CONCAT('create table ', @tableName,'(id int, name varchar(20));');
return str;
END $$
DELIMITER ;
4.执行函数
SELECT genPerson('a');
postgresql:创建function
CREATE FUNCTION insertStudent(id VARCHAR, name VARCHAR)
RETURNS BOOLEAN AS $$
BEGIN
insert into t_student(id, name);
END ;
$$ LANGUAGE plpgsql
1.10 存储过程
https://www.runoob.com/w3cnote/mysql-stored-procedure.html
- 存储过程Procedure是一组为了完成特定功能的SQL语句集合,经编译后存储在数据库中,用户通过指定存储过程的名称并给出参数来执行。
- 存储过程中可以包含逻辑控制语句 和 数据操纵语句,它可以接受参数、输出参数、返回单个或多个结果集以及返回值。
- 由于存储过程在创建时即在数据库服务器上进行了编译并存储在数据库中,所以存储过程运行要比单个的SQL语句块要快。
- 同时由于在调用时只需用提供存储过程名和必要的参数信息,所以在一定程度上也可以减少网络流量、简单网络负担
// 声明语句结束符,可以自定义:
DELIMITER $$
或
DELIMITER //
// 声明存储过程:
CREATE PROCEDURE demo_in_parameter(IN paramIn int)
// 存储过程开始和结束符号:
BEGIN、END
// 变量定义
DECLARE l_int int unsigned default 4000000;
DECLARE l_numeric number(8,2) DEFAULT 9.95;
DECLARE l_date date DEFAULT '1999-12-31';
DECLARE l_datetime datetime DEFAULT '1999-12-31 23:59:59';
// 变量赋值:
SET @p_in=1
// 变量定义:
DECLARE l_int int unsigned default 4000000;
// MySQL存储过程的参数用在存储过程的定义,共有三种参数类型,IN,OUT,INOUT
N 输入参数: 表示调用者向过程传入值(传入值可以是字面量或变量)
OUT 输出参数: 表示过程向调用者传出值(可以返回多个值)(传出值只能是变量)
INOUT 输入输出参数: 既表示调用者向过程传入值,又表示过程向调用者传出值(值只能是变量)
mysql存储过程示例:
-- 创建带参数的存储过程
DELIMITER //
CREATE PROCEDURE GetScoreByStu (IN name VARCHAR(30))
BEGIN
SELECT student_score FROM tb_students_score WHERE student_name=name;
END //
-- 调用带参数的存储过程
CALL GetScoreByStu('Green');
-- 删除存储过程
DELIMITER ;
DROP PROCEDURE GetScoreByStu;
1.11 触发器
触发器是一个特殊的存储过程,不同的是存储过程要用CALL来调用,而触发器不需要使用CALL;
只要当一个预定义的事件发生的时候,就会被自动执行。
1.12 临时表
- 临时表与永久表相似,但临时表存储在tempdb中,当不再使用时会自动删除。
- 临时表有两种类型:本地和全局。它们在名称、可见性以及可用性上有区别。
- 本地临时表的名称以单个数字符号 (#) 打头;它们仅对当前的用户连接是可见的;当用户从 SQL Server 实例断开连接时被删除。
- 全局临时表的名称以两个数字符号 (##) 打头,创建后对任何用户都是可见的,当所有引用该表的用户从 SQL Server 断开连接时被删除。
1.13 触发器存储过程和函数的区别
- 1.一般来说,存储过程实现的功能要复杂一点,而函数的实现的功能针对性比较强。
- 2.对于存储过程来说可以返回参数,而函数只能返回值或者表对象。
- 3.存储过程一般是作为一个独立的部分来执行,而函数可以作为查询语句的一个部分来调用,由于函数可以返回一个表对象,因此它可以在查询语句中位于FROM关键字的后面。
- 4.当存储过程和函数被执行的时候,SQL Manager会到procedure cache中去取相应的查询语句,如果在procedure cache里没有相应的查询语句,SQL Manager就会对存储过程和函数进行编译。
触发器是特殊的存储过程,
存储过程需要程序调用,而触发器会自动执行;
在什么时候用触发器?
要求系统根据某些操作自动完成相关任务,比如,根据买掉的产品的输入数量自动扣除该产品的库存量。
什么时候用存储过程?
存储过程就是程序,它是经过语法检查和编译的SQL语句,所以运行特别快。
1.14 索引
索引定义:
索引是由数据库表中一列或者多列组合而成,其作用是提高对表中数据的查询速度;
类似于图书的目录,方便快速定位,寻找指定的内容;
索引的优缺点:
- 优点:提高查询数据的速度;
- 缺点:创建和维护索引的时间增加了;
索引分类
- 1.普通索引: 这类索引可以创建在任何数据类型中;
- 2.唯一性索引: 使用 UNIQUE 参数可以设置,在创建唯一性索引时,限制该索引的值必须是唯一的;
- 3.全文索引: 使用 FULLTEXT 参数可以设置,全文索引只能创建在 CHAR,VARCHAR,TEXT 类型的字段上。主要作用 就是提高查询较大字符串类型的速度;只有 MyISAM 引擎支持该索引,Mysql 默认引擎不支持;
- 4.单列索引: 在表中可以给单个字段创建索引,单列索引可以是普通索引,也可以是唯一性索引,还可以是全文索引;
- 5.联合索引(复合索引、多列索引):多个列(a,b,c)建一个索引,最左原则,必须含a才走索引
- 6.空间索引: 使用 SPATIAL 参数可以设置空间索引。空间索引只能建立在空间数据类型上,这样可以提高系统获取空间数 据的效率;只有 MyISAM 引擎支持该索引,Mysql 默认引擎不支持;
- 7.聚集索引(聚簇索引)查询更快-索引顺序与数据物理存储顺序一致,每张表只能建一个,一般指主键索引,不用回表
1.15 连接查询
连接查询是将两个或两个以上的表按照某个条件连接起来,从中选取需要的数据;
- 内连接查询(缺省:inner join): 内连接查询是一种最常用的连接查询。内连接查询可以查询两个或者两个以上的表;
- merge [(type)] join归并连接
- hash [(type)] join哈希连接
- Nested [(type)] Loop Join嵌套循环连接
- 外连接查询:外连接可以查出某一张表的所有信息。 如 SELECT 属性名列表 FROM 表名 1 LEFT|RIGHT JOIN 表名 2 ON 表名 1.属性名
1=表名 2.属性名 2 ;
- 左连接查询:可以查询出“表名 1”的所有记录,而“表名 2”中,只能查询出匹配的记录;
- 右连接查询:可以查询出“表名 2”的所有记录,而“表名 1”中,只能查询出匹配的记录;
- 全外连接(full join):不仅包括符号连接表的匹配行,还包括两个连接表中的所有记录。
- CROSS JOIN:笛卡尔积:产生表A和表B的数据进行一个N*M的组合
- 反连接anti-join
- SEMI JOIN:半连接
1.16 分页
物理分页和逻辑分页
1、物理分页(数据库本身提供的分页方式):
物理分页就是数据库本身提供了分页方式,如MySQL的limit,Oracle中使用rownum好处是效率高,不好的地方就是不同数据库有不同的搞法。
2、逻辑分页:
逻辑分页利用游标分页,好处是所有数据库都统一,坏处就是效率低。
3、常用orm框架采用的分页技术:
①:hibernate 采用的是物理分页;
②:MyBatis 使用RowBounds实现的分页是逻辑分页,也就是先把数据记录全部查询出来,然在再根据offset和limit截断记录返回(数据量大的时候会造成内存溢出)
不过可以用插件或其他方式能达到物理分页效果。
mybatis的物理分页插件: 如Mybatis-PageHelper
为了在数据库层面上实现物理分页,又不改变原来MyBatis的函数逻辑,可以编写plugin截获MyBatis
Executor的statementhandler,重写SQL来执行查询
二、sql优化
2.1 sql优化理论
- 1.postgresql执行SQL语句时,首先通过语法分析模块(词法分析、语法分析(语法树)、语义分析(查询树)),然后通过查询优化器进行逻辑优化和物理优化,生成计划树,就是执行计划。
- 2.逻辑优化: 是基于规则的优化,对SQL进行重写。比如谓词下推,连接顺序交换等
- 3.物理优化:是基于代价的优化,数据库建立了各种代价模型,对各种物理路径进行代价的评估,选择一条代价相对较低的执行。物理路径包括扫描路径、连接路径等。
- 4.代价计算: 代价的计算需要用到统计信息和选择率。统计信息记录了表内数据的抽样信息,定期进行统计。根据统计信息,数据库可以计算出一个约束条件可以过滤掉多少数据,计算出选择率。根据选择率可以得到各种物理路径的代价。
- 5.连接路径: 嵌套循环连接、哈希连接、归并连接。
2.2 执行计划explain
1.语法
explain[(option[,...])]
explain [analyze][verbose]statement
//可选的option选项有:
analyze[boolean]:得到statement的真实运行时间。默认是false
verbose[boolean]:得到statement语句的执行计划和执行计划中的每个节点的详细信息。默认为false
costs[boolean]:得到计划中每个接地哪的cost,rows,width的估算值,默认为true
buffers[boolean]:analyze出现时可选。缓存的使用情况
共享缓存(shared blocks)的hit,read,dirtied,written数值
本地缓存(local blocks)的hit,read,dirtied,written数值
临时快(temp blocks)的read,written数值
timing[boolean]:analyze出现时可选。显示每个节点的启动时间和总时间花费。默认true
format{text|xml|json|yaml}:指定执行计划的输出格式
text:默认值。以行为单位,显示每个结点的计划信息,以缩进格式表示子节点的计划信息。buffers参数时的文本格式,只输出非零值
xml:xml格式
json:json格式
yaml:以yaml格式显示执行计划
2.常用组合
一般查询
explain analyze select ... ;
查询缓存及详细信息
explain (analyze,verbose,buffers) select ... ;
针对更新插入删除的执行计划查询
begin;
explain analyze insert/update/delete ... ;
rollback;
3.关键字
- cost:重要的指标。cost=0.00..16.11有两个部分,启动时间=0.00 和总时间=16.11。单位是毫秒。这个指标也只是预测值。启动时间也有解释为找到符合条件的第一行所花的时间。
- rows:返回的行数,如果执行vacuum和analyze那么返回的结果更加接近实际值
- width:查询结果所有字段的总宽度,并非关键指标。
- actual time:实际花费的时间。
- loops:循环的次数
- buffers:缓冲命中数
- output: 输出的字段名
- planning time: 生成执行计划时间
- execution time:执行执行计划时间
4.阅读顺序
- 1.嵌套层次最深的,最先执行
- 2.同样嵌套深度的,从上到下,先予执行
- 3.每一步的cost包括上一步
5.节点
- Seq Scan: 表扫描
- parallel Seq Scan 并行全表扫描
- Index Scan:索引扫描(读取索引块,然后读取数据文件)
- Index Only Scan:索引只读扫描(只读取索引文件,根据映射文件获取数据)
- Nested [(type)] Loop:嵌套循环连接。type可能是Inner,left,right,full,semi,anti。inner的可以显示省略
- Merge[(type)] Join 归并连接。type同上
- Hash[(type)] Join:哈希连接。type同上
2.3 sql优化总结
1.sql优化方案
- 0).添加索引:外键索引、重点查询字段索引
- 1).提前缩小结果集
- 2).尽量少的关联表的数量
- 3).尽量使用共享sql,减少表扫描次数,多处使用的结果集可用with as,只有一处使用直接嵌套子查询
- 5).利用with减少表扫描的次数
- 6).避免超长sql,优化逻辑,优化需求,代码处理
- 4).代码处理:程序处理减少sql依赖,尽量减小sql性能压力
- 5).尽量减少数据库访问次数,避免循环查库
- 6).尽量少使用select*
- 7).尽量减少order by 和group by
- 8).尽量不使用db_link
- 9).用case…when…then…else减少表扫描次数
- 10).用where字句代替having字句
- 11).用exist/not exist代替in/not in
- 12).优化需求、优化逻辑
- 13).优化意识更重要:
- 对性能的影响,设计〉SQL优化〉参数优化,设计阶段就要考虑性能。
2.影响使用索引的因素
- 能否走索引,是操作符是否被对应的索引访问方法支持来决定的。
- 是否用索引是优化器决定的,如果走索引的成本低,可以走索引。
- 或者使用了开关,禁止全表扫(大幅度增加全表扫描的代价,并不是真的禁用),也可以走索引。
3.强调一下公司规范
- 所有逻辑外键需创建索引
- 多级子表应该包含所有上级表的主键(如主表<-子表关系:A<-B<-C,C要有B、A的逻辑外键,以此类推)
- 表连接join条件用到的字段必须类型相同,避免隐式转换造成索引失效
- 书写规范禁用select *
4.常见不走索引的情况
- 1).数据类型不匹配:表连接join条件用到的字段必须类型相同,避免隐式转换造成索引失效
- 2).where条件等号两边字段类型不同,不走索引;
- 3).where子句索引列进行表达式或函数操作
- 4).like的全模糊匹配(btree)
- 5).like %小明 后面的字符当首位为通配符时不走索引;
- 6).结果集数据占比大
- 7)、使用不等于操作符如:<>、!= 等不走索引;
- 8).组合索引,但查询谓词并未使用组合索引的第一列
- 9).索引字段 is null 不走索引;
- 10).对于count(*)当索引字段有not null约束时走索引,否则不走索引;
- 11).not in ,not exist
- 12).条件字段选择性弱,查出的结果集较大,不走索引;
- 13).优化器分析的统计信息陈旧也可能导致不走索引;
- 14).索引字段前加了函数或参加了运算不走索引;
- 15).长时间未进行表分析(vacuum analyze),统计信息不准确
https://www.cnblogs.com/b3051/p/8478500.html
1、查询谓词没有使用索引的主要边界,换句话说就是select *,可能会导致不走索引。
比如,你查询的是SELECT * FROM T WHERE Y=XXX;假如你的T表上有一个包含Y值的组合索引,但是优化器会认为需要一行行的扫描会更有效,这个时候,优化器可能会选择TABLE
ACCESS FULL,但是如果换成了SELECT Y FROM T WHERE Y = XXX,优化器会直接去索引中找到Y的值,因为从B树中就可以找到相应的值。
2、单键值的b树索引列上存在null值,导致COUNT()不能走索引。
如果在B树索引中有一个空值,那么查询诸如SELECT COUNT() FROM T 的时候,因为HASHSET中不能存储空值的,所以优化器不会走索引,有两种方式可以让索引有效,一种是SELECT
COUNT(*) FROM T WHERE XXX IS NOT NULL或者把这个列的属性改为not null (不能为空)。
3、索引列上有函数运算,导致不走索引
如果在T表上有一个索引Y,但是你的查询语句是这样子SELECT * FROM T WHERE FUN(Y) =
XXX。这个时候索引也不会被用到,因为你要查询的列中所有的行都需要被计算一遍,因此,如果要让这种sql语句的效率提高的话,在这个表上建立一个基于函数的索引,比如CREATE
INDEX IDX FUNT ON T(FUN(Y));这种方式,等于Oracle会建立一个存储所有函数计算结果的值,再进行查询的时候就不需要进行计算了,因为很多函数存在不同返回值,因此必须标明这个函数是有固定返回值的。
4、隐式转换导致不走索引。
索引不适用于隐式转换的情况,比如你的SELECT * FROM T WHERE Y = 5
在Y上面有一个索引,但是Y列是VARCHAR2的,那么Oracle会将上面的5进行一个隐式的转换,SELECT * FROM T WHERE TO_NUMBER(Y) =
5,这个时候也是有可能用不到索引的。
5、表的数据库小或者需要选择大部分数据,不走索引
在Oracle的初始化参数中,有一个参数是一次读取的数据块的数目,比如你的表只有几个数据块大小,而且可以被Oracle一次性抓取,那么就没有使用索引的必要了,因为抓取索引还需要去根据rowid从数据块中获取相应的元素值,因此在表特别小的情况下,索引没有用到是情理当中的事情。
6、cbo优化器下统计信息不准确,导致不走索引
很长时间没有做表分析,或者重新收集表状态信息了,在数据字典中,表的统计信息是不准确的,这个情况下,可能会使用错误的索引,这个效率可能也是比较低的。
7、!=或者<>(不等于),可能导致不走索引,也可能走 INDEX FAST FULL SCAN 例如select id from test where id<>100
8、表字段的属性导致不走索引,字符型的索引列会导致优化器认为需要扫描索引大部分数据且聚簇因子很大,最终导致弃用索引扫描而改用全表扫描方式,
9.建立组合索引,但查询谓词并未使用组合索引的第一列,此处有一个INDEX SKIP SCAN概念,
10、like ‘%liu’ 百分号在前
11,not in ,not exist
可以尝试把not in 或者 not exsts改成左连接的方式(前提是有子查询,并且子查询有where条件)。
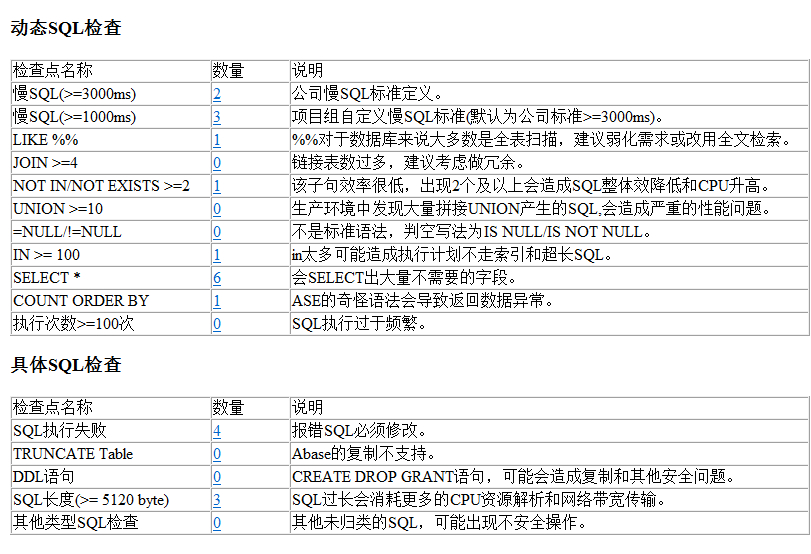
2.4 动态Sql检查
三、数据库优化
3.1 数据库集群(读写分离、主从复制、主从热备)
3.2 查询缓存
- 查询缓存指在内存或外存上建立一个存储空间,用来保存上次查询结果,再进行同样的查询时,直接从存储空间读取,提升查询效率
- commit()清理缓存的原因:对数据库进行增删改查操作,如果不及时清理缓存,就会丢失数据的实时性,造成脏读
3.2 分区
3.2 分表
水平分表
- 以字段(如月份)为依据,按一定的策略,如hash,将数据存不同的表
- 每个表结构相同
- 适用表数据量大
垂直分表
- 以字段为依据,按字段活跃性,将表字段拆分到不同表
- 每个表结构不同,但有字段关联
- 适用表字段多,表宽
3.2 分库
水平分库
- 以字段为依据,按一定的策略,如hash,将数据存不同的库
- 每个库表结构相同
垂直分库
- 以表为依据,将不同业务表分到不同库===>服务化
- 每个库表结构不同
3.2 分库分表工具
mycat
- 基于mycat实现数据库读写分离
- 基于mycat实现数据库切分策略剖析
- mycat全局表-er表-分片策略分析
sharding-sphere
四、数据库运维
4.1 postgrasql备份-恢复
windows
--cd到目录:
postgrasql\10.0\bin
--#备份
pg_dump -h 127.0.0.1 -U sa -d db_test -p 5432 -f E:/database.bak
--按提示输入密码
--#恢复
psql -h 127.0.0.1 -U sa -d db_test -p 5432 -f E:/database.bak
linux
--切换数据库用户
su postgresql
--cd到目录:
cd /home/postgrasql/10.0/bin
--备份
pg_dump -h 127.0.0.1 -U root -d db_test -p 5432 -f /opt/postgrasql/database_$cur_time.bak
--按提示输入密码
--恢复
psql -h 127.0.0.1 -U root -d db_test -p 5432 -f /opt/postgrasql/database_20200101101010.bak
定时任务每日自动备份数库shell脚本“backup.sh”
#!/bin/bash
HOME="/opt/postgresql/10.0/lib/"
cur_time=`date +%Y-%m-%d`
if [ "$LD_LIBRARY_PATH" != "$HOME" ]; then
echo "no LD_LIBRARY_PATH"
export LD_LIBRARY_PATH=$HOME
echo "set LD_LIBRARY_PATH"
fi
if [ "$PGPASSWORD" != "root" ]; then
echo "$(date): no password"
export PGPASSWORD="root"
#echo "$PGPASSWORD"
/opt/db/postgresql/bin/pg_dump -h 127.0.0.1 -U root -d db_test -p 6543 -f /opt/databasebak/database_test_$cur_time.bak
echo "$(date):db_test backup success"
else
echo "$(date): has password"
/opt/db/postgresql/bin/pg_dump -h 127.0.0.1 -U root -d db_test -p 6543 -f /opt/databasebak/database_test_$cur_time.bak
echo "$(date):db_test backup success"
fi
4.2 mysql备份恢复
4.3 生产环境数据库操作注意事项
先备份,后操作
五、数据库原理

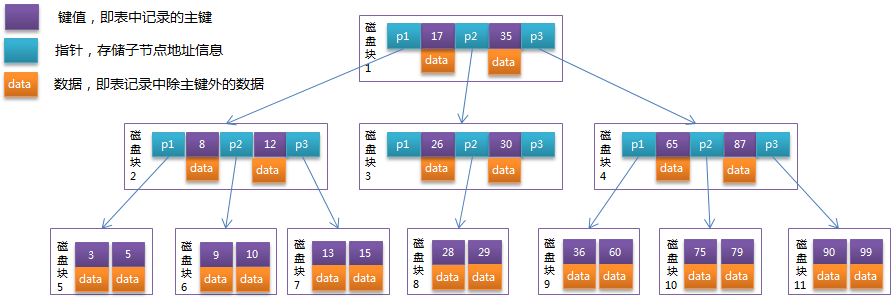
5.0 B-tree和B+tree
B-tree
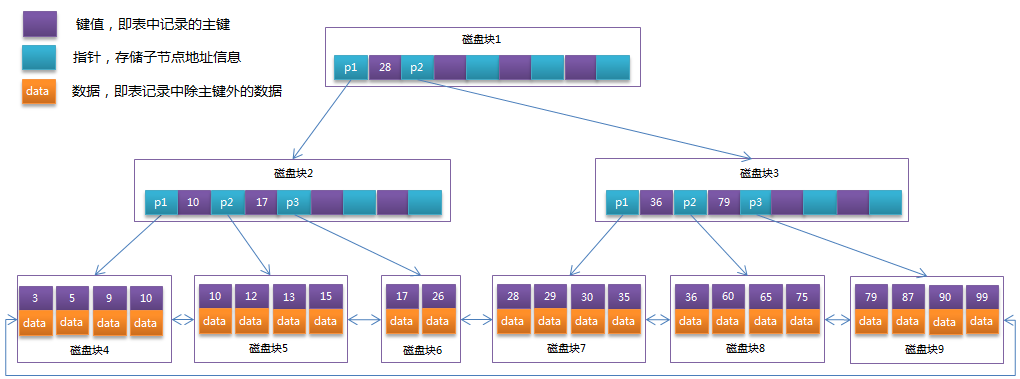
B+tree
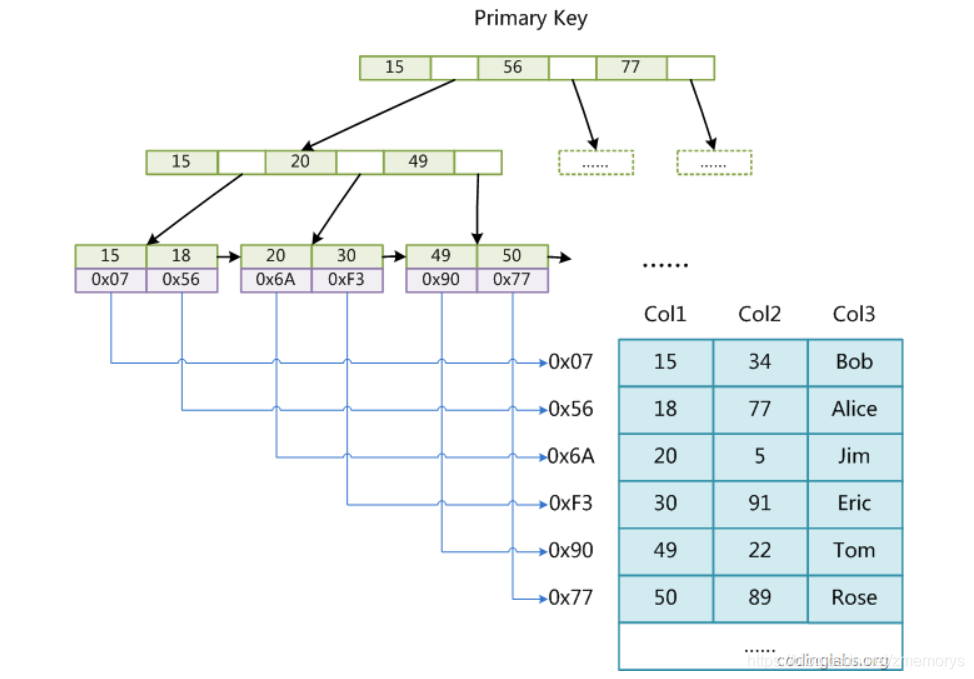
5.1 存储引擎MYISAM、
MYISAM 存储文件结构:
- .frm 表结构文件- .myd 数据文件
- .myi 索引文件
索引B+tree结构:存储的都是索引列,不含数据,叶子节点仅存储了记录的地址
5.2 存储引擎innodb
INNODB存储文件结构:
- .frm 表结构文件
- .ibd 数据文件,ibd既包括数据也包括索引,表数据文件本身就是按B+Tree组织的一个索引结构文件,主键索引叶节点包含了完整的数据记录
索引数据B+tree结构:叶子节点存储数据,叶子以上节点存储索引列
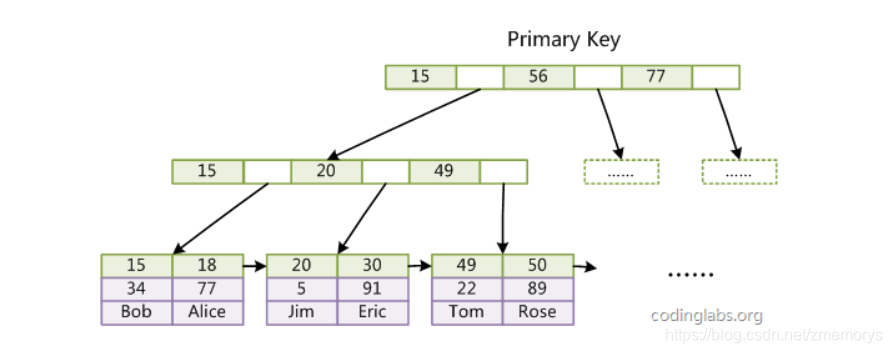
- InnoDB主索引(同时也是数据文件)的图,可以看到叶节点包含了完整的数据记录,这种索引叫做【聚集索引】。
- 因为InnoDB的数据文件本身要按主键聚集,所以InnoDB要求表必须有主键(MyISAM可以没有),
- 如果没有显式指定,则MySQL系统会自动选择一个可以唯一标识数据记录的列作为主键,
- 如果不存在这种列,则MySQL自动为InnoDB表生成一个隐含字段ROWID作为主键,这个字段长度为6个字节,类型为长整形
5.3 索引存储数据量的计算
计算机在存储数据的时候,最小存储单位是以扇区计算,一个扇区的大小是512字节b,而文件系统(如XFS/EXT4)最小单位是块,一个块的大小是4KB=8扇区
- InnoDB引擎存储数据的时候,是以页为单位(对应b+tree的一个节点),每个数据页的默认大小是16KB(可以通过show global status like “Innodb_page_size” 看到该值是16384),对应操作系统中的4个文件块,
-
如果数据库存储的一条记录大小是1KB,那么一页(b+tree一个叶子节点,仅叶子节点存数据记录)可以存储16条数据;
对于b+tree非叶子节点存储的则是【索引列和指针】,在InnoDB中,指针大小是6个字节,当索引列的类型为BigInt时占用8个字节,此时一个索引列数据14KB,一页(b+tree一个非叶子节点)可以存16384/(8+6)=1170条索引列
层高为3的树为例计算:
- 第一层,共一个根节点,可以存16384/(8+6)=1170条索引列,每个索引列指向下一层的一个节点,即2层有 1170 个节点
- 第二层,共有1170个节点, 可以存1170 *1170个索引列, ,每个索引列指向下一层的一个节点,即3层有 1170 *1170 个节点
- 第三层,共有 1170 *1170 个节点,每个节点可以存16条记录,所以共存 1170 *1170 *16 =21902400,大约2200万条数据
在查找某条数据时,将对一次页(查找B+tree的一个节点)的查找代表一次IO,所以在这种千万级的表中通过主键索引查找一条数据,最多3次IO就可以找到一条数据。而很多时候树的根节点基本都是在内存中,所以多数时候只需要2次IO。
5.4 回表查询
InnoDB有两大类索引
- 聚集索引(clustered index)—– 聚集索引,叶子节点存储行记录
- 普通索引(secondary index)—–普通索引,叶子节点存储主键值,
那普通索引的查询过程 通常情况下,需要扫码两遍索引树。
- 先查普通索引树,定位到主键值
- 再查主键索引树,定位行记录
它的性能较扫一遍索引树更低,这就是所谓的【回表查询】
六、数据库管理工具
6.1 数据库建模工具
- 开源数据库模型建模工具-PDMan!
- powerDesigner建模
- Navicate建模
6.2 数据库脚本版本控制工具
- Flyway简介
- Flyway数据库版本控制器理解与使用
- https://blog.csdn.net/u012397189/article/details/114988615?spm=1001.2014.3001.5501
6.3 客户端链接UI工具:
- Navicate:
- dbvisualizer:
- Datagrip(jetbrains公司产品):
- SQL Server:自带图形界面
- PLSql:oracle:
- sqlyog:mysql
- sqldbx:sybase
问题总结
1.为什么非主键索引结构叶子节点存储的是主键值?
一是保证一致性,更新数据的时候只需要更新主键索引树,
二是节省存储空间。
2.为什么推荐InnoDB表必须有主键?
保证会有主键索引树的存在(因为数据存放在主键索引树上面),如果没有mysql会自己生成一个rowid作为自增的主键主键索引
3.为什么推荐使用整型的自增主键?
一是方便查找比较,
二是新增数据的时候只需要在最后加入,不会大规模调整树结构,如果是UUID的话,大小不好比较,新增的时候也极有可能在中间插入数据,会导致树结构大规调整,造成插入数据变慢。
4.聚集索引一般是表中的主键索引,如果表中没有显示指定主键,则会选择表中的第一个不允许为NULL的唯一索引,如果还是没有的话,就采用Innodb存储引擎为每行数据内置的6字节ROWID作为聚集索引。