集群日志收集架构ELK、EFK
参考资料
- 日志平台:ELK(Logstash、ElasticSearch、Kibana):https://github.com/helm/charts/tree/master/stable/elastic-stack
- 日志平台:EFK(Filebeat/Fluentd/Fluent-bit、Logstash、ElasticSearch、Kibana)
- 官网地址: https://www.elastic.co/cn/
- 官网权威指南: https://www.elastic.co/guide/cn/elasticsearch/guide/current/index.html
- 安装指南:https://www.elastic.co/guide/en/elasticsearch/reference/5.x/rpm.html
前言
现在系统都是分布式的,集群化的,那就代表着我们的应用会分布在很多服务器上面;那应用的日志文件就会分布在各个服务器上面。
系统出现了问题,第一时间想到的是先要判断到底哪个服务出现了问题;技术人员连接生产环境服务器,查看服务器上面的应用日志。
那么多的服务器,技术人员这个时候就会很抓狂,一个个的查看分析日志,是比较愚蠢的方法。ELK是常用的方案。
一、ELK方案
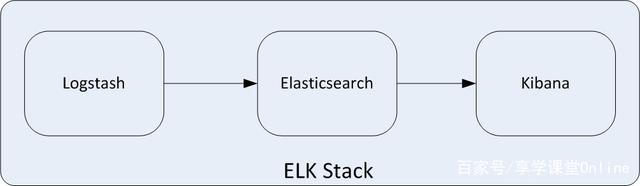
ELK 是elastic公司提供的一套完整的日志收集以及展示的解决方案,是三个产品的首字母缩写,分别是ElasticSearch、Logstash 和 Kibana。
- ElasticSearch简称ES,它是一个实时的分布式搜索和分析引擎,它可以用于全文搜索,结构化搜索以及分析。它是一个建立在全文搜索引擎 Apache Lucene 基础上的搜索引擎,使用 Java 语言编写。
- Logstash是一个具有实时传输能力的数据收集引擎,用来进行数据收集(如:读取文本文件)、解析,并将数据发送给ES。
- Kibana为 Elasticsearch 提供了分析和可视化的 Web 平台。它可以在 Elasticsearch 的索引中查找,交互数据,并生成各种维度表格、图形。
这三款软件都是开源软件,通常配合使用,而且又先后归于Elastic.co公司名下
二、ELK的用途
传统意义上,ELK是作为替代Splunk的一个开源解决方案。Splunk 是日志分析领域的领导者。日志分析并不仅仅包括系统产生的错误日志,异常,也包括业务逻辑,或者任何文本类的分析。而基于日志的分析,能够在其上产生非常多的解决方案,譬如:
- 1.问题排查。我们常说,运维和开发这一辈子无非就是和问题在战斗,运维和开发能够快速的定位问题,甚至防微杜渐,把问题杀死在摇篮里。日志分析技术显然问题排查的基石。
- 2.监控和预警。日志,监控,预警是相辅相成的。基于日志的监控,预警使得运维有自己的机械战队,大大节省人力以及延长运维的寿命。
- 3.关联事件。多个数据源产生的日志进行联动分析,通过某种分析算法,就能够解决生活中各个问题。比如金融里的风险欺诈等。
- 4.数据分析。 这个对于数据分析师,还有算法工程师都是有所裨益的。
三、ElasticSearch介绍
ElasticSearch是一个实时的分布式搜索和分析引擎,采用java语言编写,现在的最新版本已经ElasticSearch7.5.x,他的主要特点如下:
- 实时搜索、实时分析分布式架构、实时文件存储文档导向,
- 所有对象都是文档高可用,易扩展,支持集群,分片与复制接口友好,支持json
四、Logstash介绍
logstash是一款轻量级的、开源的日志收集处理框架,它可以方便的把分散的、多样化的日志收集起来,并进行自定义的过滤分析处理,然后输出到指定的位置(如:es)。
Logstash工作原理
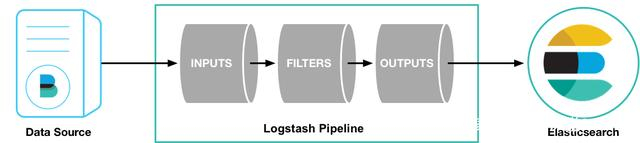
如上图,Logstash的数据处理过程主要包括:Inputs, Filters, Outputs 三部分,
另外在Inputs和Outputs中可以使用Codecs对数据格式进行处理。
这四个部分均以插件形式存在,用户通过定义pipeline配置文件,设置需要使用的input,filter,output,codec插件,以实现特定的数据采集,数据处理,数据输出等功能。
- (1)Inputs:用于从数据源获取数据,常见的插件如file,syslog,redis,beats等
- (2)Filters:用于处理数据如格式转换,数据派生等,常见的插件如grok, mutate, drop, clone, geoip等
- (3)Outputs:用于数据输出,常见的插件如elastcisearch,file, graphite, statsd等
- (4)Codecs:Codecs不是一个单独的流程,而是在输入和输出等插件中用于数据转换的模块,用于对数据进行编码处理,常见的插件如json,multiline
五、Kibana介绍
Kibana是一个开源的分析和可视化平台,设计用于和Elasticsearch一起工作。
可以用Kibana来搜索,查看,并存储在Elasticsearch索引中的数据进行交互。
可以轻松地执行高级数据分析,并且以各种图标、表格和地图的形式可视化数据。
Kibana使得理解大量数据变得很容易。它简单的、基于浏览器的界面使你能够快速创建和共享动态仪表板,实时显示Elasticsearch查询的变化。
六、Filebeat介绍
虽然我们的logstash功能已经非常强大了,里面包含采集,过滤,转换等功能;正因为有很多的功能,导致了它比较耗资源。其实在我们应用服务器端只需要采集日志功能就行了,没有必要logstash其他的功能;
所以Filebeat等beat组件就出现了,它们比较小巧,而且不耗资源,也完全够用。
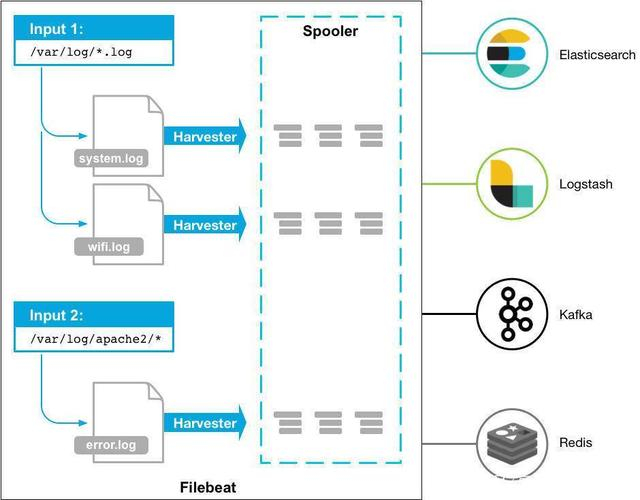
Filebeat是一个轻量级的托运人,用于转发和集中日志数据。Filebeat作为代理安装在服务器上,监视您指定的日志文件或位置,收集日志事件,并将它们转发到Elasticsearch或 Logstash进行索引。
Filebeat的工作原理:启动Filebeat时,它会启动一个或多个输入,这些输入将查找您为日志数据指定的位置。对于Filebeat找到的每个日志,Filebeat启动一个收集器。
每个收集器为新内容读取单个日志,并将新日志数据发送到libbeat,libbeat聚合事件并将聚合数据发送到您为Filebeat配置的输出。
官方流程图如下:
七、ELK常见架构
最简单的ELK应用架构
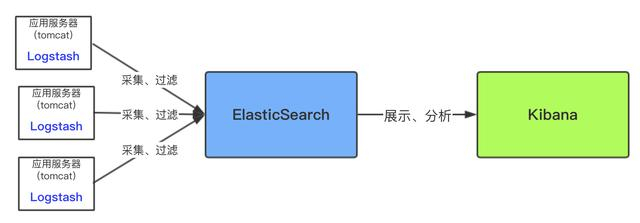
上面架构是简单粗暴的架构,这种架构对数据源服务器(即应用服务器)性能影响较大,因为Logsash是需要安装和运行在需要收集的数据源服务器(即应用服务器)中,然后将收集到的数据实时进行过滤,过滤环节是很耗时间和资源的,过滤完成后才传输到ES中。
下面是优化后的架构图:
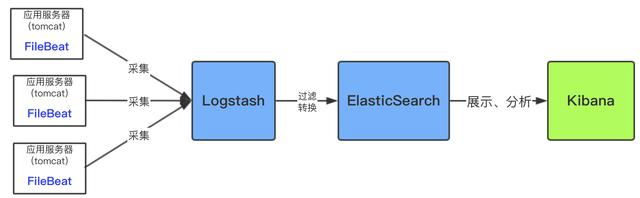
用filebeat采集日志有效降低了收集日志对业务系统的系统资源的消耗。再通过logstash服务器可以过滤,转换日志。这样即满足了日志的过滤转换,也保障了业务系统的性能。
当然上面的架构中,是支持集群的
如果日志文件量特别大,以及收集的服务器日志比较多;这样架构中需加入消息中间件做一下缓冲
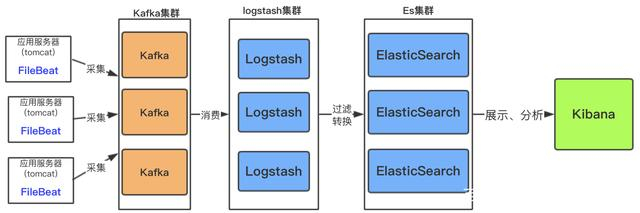
此架构适合大型集群,海量数据的业务场景,消息队列kafka集群架构有效保障了收集数据的安全性和稳定性,而后端logstash和es均采用了集群模式搭建,从整体上提高了ELK的系统的高效性,扩展性和吞吐量。
八、搭建ELK日志分析系统
8.1基于二进制文件部署ELK
- Filebeat+Kafka+Logstash+ElasticSearch+Kibana 日志采集方案: https://www.cnblogs.com/willpan-z/p/10307967.html
- ELK(Filebeat+Kafka+Logstash+ElasticSearch+Kibana):https://www.cnblogs.com/sxFu/p/14751779.html
- Filebeat+Kafka+Logstash+ElasticSearch+Kibana搭建完整版:https://www.cnblogs.com/jiashengmei/p/8857053.html
- 日志篇- ES+Logstash+Filebeat+Kibana+Kafka+zk 安装配置与使用详解 https://blog.csdn.net/qq_35550345/article/details/107045153
Filebeat安装配置
## 1.下载
wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-8.10.2-x86_64.rpm
rpm -ivh filebeat-7.17.5-x86_64.rpm
## 2.cat /etc/ilebeat/filebeat.yml
filebeat.inputs:
filebeat.config.inputs:
path: ${path.config}/child/*.yml
enabled: true
reload.enabled: true
reload.period: 60s
filebeat.config.modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: true
reload.period: 5s
#==================== Elasticsearch template setting ==========================
setup.template.settings:
index.number_of_shards: 3
#-----------------------kafka output ----------------------------------------
output.kafka:
hosts: ["kafka1:9092","kafka2:9092","kafka3:9092"]
topic: '%{[fields.modletype]}'
username: 'admin'
password: '123456'
sasl.mechanism: 'SCRAM-SHA-256'
partition.round_robin:
reachable_only: false
required_acks: 1
compression: gzip
max_message_bytes: 1000000
keep_alive: 10s
## 3.cat /etc/ilebeat/child/test-nginx.yml
- type: log
paths:
- /data/nginx/logs/*access*.log
exclude_lines: ['^DBG'] #不包含匹配该格式的日志
#clean_inactive: 24h
#ignore_older: 20h
close_inactive: 1m
close_timeout: 2h
fields:
ip: 36.134.227.197
modletype: test-nginx
datacenter: gy
# level: debug
# review: 1
multiline.pattern: ^\{
multiline.negate: true #false,匹配pattern的行合并到上一行;true,不匹配pattern的行合并到上一行
multiline.match: after #合并到上一行的末尾或开头
processors:
- decode_json_fields:
fields: ["message"]
process_array: false
max_depth: 3
target: ""
overwrite_keys: false
## 启动服务
sudo systemctl daemon-reload
sudo systemctl enable filebeat # 设置开机自启
sudo systemctl start filebeat # 启动服务
journalctl -u filebeat -f # 查看日志
logstash安装配置
elasticsearch安装配置
kibana安装配置
8.2 基础docker部署ELK
基于 Docker 的 ELK 高可用集群架构 https://blog.csdn.net/IT_ZRS/article/details/125466805
8.3 基于k8s部署ELK
logstash.yml
apiVersion: v1
kind: ConfigMap
metadata:
name: logstash-config
namespace: elk
data:
logstash.conf: |-
input{
kafka{
bootstrap_servers => "kafka1:9093, kafka29093, kafka3:9093"
group_id => "elk-logstash-consumer"
security_protocol => "SASL_PLAINTEXT"
sasl_mechanism => "SCRAM-SHA-256"
sasl_jaas_config => "org.apache.kafka.common.security.scram.ScramLoginModule required username='admin' password='admin-secret';"
type => "test-nginx"
topics => "test-nginx"
consumer_threads => 6
decorate_events => true
#enable_auto_commit => false
codec => "json"
auto_offset_reset => "latest"
heartbeat_interval_ms => "30000"
session_timeout_ms => "60000"
fetch_max_bytes => "1048576"
fetch_max_wait_ms => "10000"
receive_buffer_bytes => "2097152"
}
}
filter {
truncate {
fields => [ "message" ]
length_bytes => 32764
}
if ( "Exception" in [message] and "ERROR" in [message] ){
mutate {
add_field => [ "show","exception" ]
}
}
# ["1-半日","2-日","3-周","4-月"]
ruby {
code => "event.set('index_day', (event.get('@timestamp').time.localtime + 28800).strftime('%Y.%m.%Ww'))"
}
}
output {
elasticsearch {
action => "index"
hosts => ["es-ip:9092"]
#workers => 5
password => "123456"
user => "elastic"
index => "test-nginx"
http_compression => true
timeout => 280
}
}
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: logstash
namespace: elk
labels:
name: logstash
spec:
replicas: 1
selector:
matchLabels:
name: logstash
template:
metadata:
labels:
app: logstash
name: logstash
spec:
containers:
- name: logstash
image: crpi-39k23aqntb3h78w8.cn-hangzhou.personal.cr.aliyuncs.com/wdsheng/logstash:7.12.0
ports:
- containerPort: 5044
protocol: TCP
- containerPort: 9600
protocol: TCP
volumeMounts:
- name: logstash-config
mountPath: /usr/share/logstash/pipeline/logstash.conf
subPath: logstash.conf
volumes:
- name: logstash-config
configMap:
name: logstash-config
---
apiVersion: v1
kind: Service
metadata:
namespace: elk
name: logstash
labels:
app: logstash
spec:
type: ClusterIP
ports:
- port: 5044
name: logstash
selector:
app: logstash
elasticsearch.yml
apiVersion: apps/v1
kind: Deployment
metadata:
generation: 1
labels:
app: elasticsearch-logging
version: v1
name: elasticsearch
namespace: elk
spec:
minReadySeconds: 10
progressDeadlineSeconds: 600
replicas: 1
revisionHistoryLimit: 10
selector:
matchLabels:
app: elasticsearch-logging
version: v1
strategy:
type: Recreate
template:
metadata:
creationTimestamp: null
labels:
app: elasticsearch-logging
version: v1
spec:
affinity:
nodeAffinity:
containers:
- env:
- name: discovery.type
value: single-node
- name: ES_JAVA_OPTS
value: -Xms512m -Xmx512m
- name: MINIMUM_MASTER_NODES
value: "1"
image: docker.elastic.co/elasticsearch/elasticsearch:7.12.0-amd64
imagePullPolicy: IfNotPresent
name: elasticsearch-logging
ports:
- containerPort: 9200
name: db
protocol: TCP
- containerPort: 9300
name: transport
protocol: TCP
resources:
limits:
cpu: "1"
memory: 1Gi
requests:
cpu: "1"
memory: 1Gi
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
volumeMounts:
- mountPath: /data
name: es-persistent-storage
dnsPolicy: ClusterFirst
imagePullSecrets:
- name: user-1-registrysecret
initContainers:
- command:
- /sbin/sysctl
- -w
- vm.max_map_count=262144
image: alpine:3.6
imagePullPolicy: IfNotPresent
name: elasticsearch-logging-init
resources:
securityContext:
privileged: true
procMount: Default
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
restartPolicy: Always
schedulerName: default-scheduler
securityContext:
terminationGracePeriodSeconds: 30
volumes:
- hostPath:
path: /opt/paas/hanju/es_data
type: ""
name: es-persistent-storage
- name: config
configMap:
name: elasticsearch-config
---
apiVersion: v1
kind: Service
metadata:
namespace: elk
name: elasticsearch
labels:
app: elasticsearch-logging
spec:
type: ClusterIP
ports:
- port: 9200
name: elasticsearch
selector:
app: elasticsearch-logging
---
kind: ConfigMap
apiVersion: v1
metadata:
name: elasticsearch-config
namespace: elk
labels:
app: elasticsearch
role: master
data:
elasticsearch.yml: |-
action.auto_create_index: true
kibana.yml
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: kibana
namespace: elk
labels:
name: kibana
spec:
replicas: 1
selector:
matchLabels:
name: kibana
template:
metadata:
labels:
app: kibana
name: kibana
spec:
containers:
- name: kibana
image: docker.elastic.co/kibana/kibana:7.12.0
ports:
- containerPort: 5601
protocol: TCP
env:
- name: ELASTICSEARCH_URL
value: http://elasticsearch:9200
volumeMounts:
- name: config
mountPath: /usr/share/kibana/config/kibana.yml
readOnly: true
subPath: kibana.yml
volumes:
- name: config
configMap:
name: kibana-config
---
apiVersion: v1
kind: ConfigMap
metadata:
namespace: elk
name: kibana-config
data:
kibana.yml: |-
server:
name: kibana
host: "0"
elasticsearch:
hosts: [ "http://elasticsearch:9200" ]
i18n:
locale: "zh-CN"
---
apiVersion: v1
kind: Service
metadata:
name: kibana
namespace: elk
spec:
type: NodePort
ports:
- protocol: TCP
port: 80
targetPort: 5601
nodePort: 31100
selector:
app: kibana
8.4 日志采集步骤
- filebeat配置采集目录,topic定义, 输出到kafka
- logstash消费topic,上传es,创建index
- kibana配置es, 索引模式, 检索
九、日志采集工具对比
- Logstash、Filebeat、Fluentd、Fluent-bit、Logagent、logtail对比
- 9款日志管理工具大比拼,选型必备!:https://developer.aliyun.com/article/1203599
问题记录
1.but this cluster currently has [3000]/[3000] maximum shards open;”}}}}
- https://zhidao.baidu.com/question/1550300702681858267.html
- https://knight.blog.csdn.net/article/details/105707342
- https://blog.csdn.net/liupeng_qwert/article/details/78273140
#查看集群健康状态
curl -u elastic:123456 -X GET "192.168.0.1:9200/_cluster/health?pretty"
#查看集群配置
curl -u elastic:123456 -X GET "192.168.0.1:9200/_cluster/settings?pretty"
#查看集群nodes
curl -u elastic:123456 -X GET "192.168.0.1:9200/_cat/nodes?pretty"
#查看集群集群分片
curl -u elastic:123456 -X GET 192.168.0.1:9200/_cluster/settings?pretty
# 修改集群分片上上限,默认1000
curl -u elastic:123456 -X PUT 192.168.0.1:9200/_cluster/settings -H "Content-Type: application/json" -d '{ "persistent": { "cluster.max_shards_per_node": "2000" } }'
2.使用logstash将es集群中的日志数据导入到mysql数据库中
# 下载logstash
根据es集群的版本,选择相应版本的logstash
这里的es集群版本为7.1.1,选择了7.11.2版本的logstash
wget https://artifacts.elastic.co/downloads/logstash/logstash-7.11.2-linux-x86_64.tar.gz
tar -zxvf logstash-7.11.2-linux-x86_64.tar.gz
# 插件安装
./logstash-plugin list | grep jdbc
./logstash-plugin install logstash-output-jdbc
# mysql-connector-java-5.1.40.jar可以找研发
mv mysql-connector-java-5.1.40.jar /etc/logstash/conf.d/
# 编辑导数据的配置文件
input中配置es集群的信息,query字段配置的查询参数,需要提前使用curl测试查询
output中配置mysql数据库的信息,注意connection_string和statement中库和表的参数配置
output中statement的表字段,值需要一一对应
vim convert_sql_from_es.conf
input {
elasticsearch {
hosts => "192.168.0.2:9200"
index => "test-operation-2024-04"
user => "elastic"
password => "123456"
query => '{"query":{"match_all":{}}}'
#query => '{"query": { "range": { "@timestamp": { "gte": "now-1y/d", "lt": "now" } } }}'
}
}
output {
jdbc {
connection_string => "jdbc:mysql://192.168.0.1:3306/test?characterEncoding=utf8&useSSL=false&serverTimezone=UTC&rewriteBatchedStatements=true"
username => "root"
password => "123456"
driver_jar_path => "/etc/logstash/conf.d/mysql-connector-java-5.1.40.jar"
driver_class => "com.mysql.jdbc.Driver"
statement => ["INSERT INTO tezt_operationlog (phone, operationContent, actionId, userId, orgId, serialNo, timestamp, userName, mediaName) VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?)", "[phone]", "[operationContent]", "[actionId]", "[userId]", "[orgId]", "[serialNo]", "[timestamp]", "[userName]", "[mediaName]"]
}
}
# 导入
/data/logstash-7.11.2/bin/logstash -f /data/logstash-7.11.2/config/convert_sql_from_es.conf