集群日志收集架构ELK、EFK
参考资料
- 日志平台:ELK(ElasticSearch、Logstash、Kibana):https://github.com/helm/charts/tree/master/stable/elastic-stack
- 日志平台:EFK(ElasticSearch、Fluent-bit/Fluentd、Kibana)
- 官网地址: https://www.elastic.co/cn/
- 官网权威指南: https://www.elastic.co/guide/cn/elasticsearch/guide/current/index.html
- 安装指南:https://www.elastic.co/guide/en/elasticsearch/reference/5.x/rpm.html
- Spring Boot 搭建 ELK,这才是正确看日志的方式!
- 快速搭建ELK日志分析系统
前言
介绍了项目中如何使用logback组件记录系统的日志情况;现在我们的系统都是分布式的,集群化的,那就代表着我们的应用会分布在很多服务器上面;那应用的日志文件就会分布在各个服务器上面。
问题
突然有一天我们系统出现了问题,我们第一时间想到的是先要判断到底哪个服务出现了问题;我们的技术人员就连接生产环境服务器,查看服务器上面的应用日志。
那么多的服务器,技术人员这个时候就会很抓狂,一个个的查看分析日志,是比较愚蠢的方法。那有什么好的方式呢?今天老顾给大家介绍常规的方案。
一、ELK方案
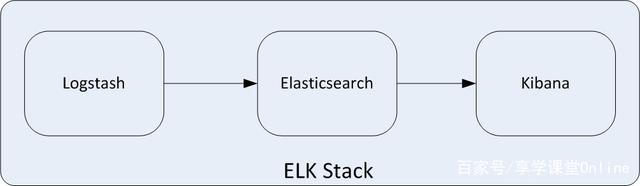
ELK 是elastic公司提供的一套完整的日志收集以及展示的解决方案,是三个产品的首字母缩写,分别是ElasticSearch、Logstash 和 Kibana。
- ElasticSearch简称ES,它是一个实时的分布式搜索和分析引擎,它可以用于全文搜索,结构化搜索以及分析。它是一个建立在全文搜索引擎 Apache Lucene 基础上的搜索引擎,使用 Java 语言编写。
- Logstash是一个具有实时传输能力的数据收集引擎,用来进行数据收集(如:读取文本文件)、解析,并将数据发送给ES。
- Kibana为 Elasticsearch 提供了分析和可视化的 Web 平台。它可以在 Elasticsearch 的索引中查找,交互数据,并生成各种维度表格、图形。
这三款软件都是开源软件,通常配合使用,而且又先后归于Elastic.co公司名下
二、ELK的用途
传统意义上,ELK是作为替代Splunk的一个开源解决方案。Splunk 是日志分析领域的领导者。日志分析并不仅仅包括系统产生的错误日志,异常,也包括业务逻辑,或者任何文本类的分析。而基于日志的分析,能够在其上产生非常多的解决方案,譬如:
- 1.问题排查。我们常说,运维和开发这一辈子无非就是和问题在战斗,运维和开发能够快速的定位问题,甚至防微杜渐,把问题杀死在摇篮里。日志分析技术显然问题排查的基石。
- 2.监控和预警。日志,监控,预警是相辅相成的。基于日志的监控,预警使得运维有自己的机械战队,大大节省人力以及延长运维的寿命。
- 3.关联事件。多个数据源产生的日志进行联动分析,通过某种分析算法,就能够解决生活中各个问题。比如金融里的风险欺诈等。
- 4.数据分析。 这个对于数据分析师,还有算法工程师都是有所裨益的。
三、ElasticSearch介绍
ElasticSearch是一个实时的分布式搜索和分析引擎,采用java语言编写,现在的最新版本已经ElasticSearch7.5.x,他的主要特点如下:
- 实时搜索、实时分析分布式架构、实时文件存储文档导向,
- 所有对象都是文档高可用,易扩展,支持集群,分片与复制接口友好,支持json
四、Logstash介绍
logstash是一款轻量级的、开源的日志收集处理框架,它可以方便的把分散的、多样化的日志收集起来,并进行自定义的过滤分析处理,然后输出到指定的位置(如:es)。
Logstash工作原理
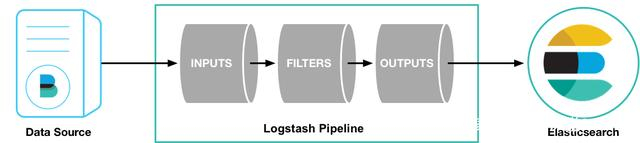
如上图,Logstash的数据处理过程主要包括:Inputs, Filters, Outputs 三部分, 另外在Inputs和Outputs中可以使用Codecs对数据格式进行处理。
这四个部分均以插件形式存在,用户通过定义pipeline配置文件,设置需要使用的input,filter,output,codec插件,以实现特定的数据采集,数据处理,数据输出等功能。
- (1)Inputs:用于从数据源获取数据,常见的插件如file,syslog,redis,beats等
- (2)Filters:用于处理数据如格式转换,数据派生等,常见的插件如grok, mutate, drop, clone, geoip等
- (3)Outputs:用于数据输出,常见的插件如elastcisearch,file, graphite, statsd等
- (4)Codecs:Codecs不是一个单独的流程,而是在输入和输出等插件中用于数据转换的模块,用于对数据进行编码处理,常见的插件如json,multiline
五、Kibana介绍
Kibana是一个开源的分析和可视化平台,设计用于和Elasticsearch一起工作。
可以用Kibana来搜索,查看,并存储在Elasticsearch索引中的数据进行交互。
可以轻松地执行高级数据分析,并且以各种图标、表格和地图的形式可视化数据。
Kibana使得理解大量数据变得很容易。它简单的、基于浏览器的界面使你能够快速创建和共享动态仪表板,实时显示Elasticsearch查询的变化。
六、什么是Filebeat
虽然我们的logstash功能已经非常强大了,里面包含采集,过滤,转换等功能;正因为有很多的功能,导致了它比较耗资源。其实在我们应用服务器端只需要采集日志功能就行了,没有必要logstash其他的功能;
所以Filebeat等beat组件就出现了,它们比较小巧,而且不耗资源,也完全够用。
Filebeat是一个轻量级的托运人,用于转发和集中日志数据。Filebeat作为代理安装在服务器上,监视您指定的日志文件或位置,收集日志事件,并将它们转发到Elasticsearch或 Logstash进行索引。
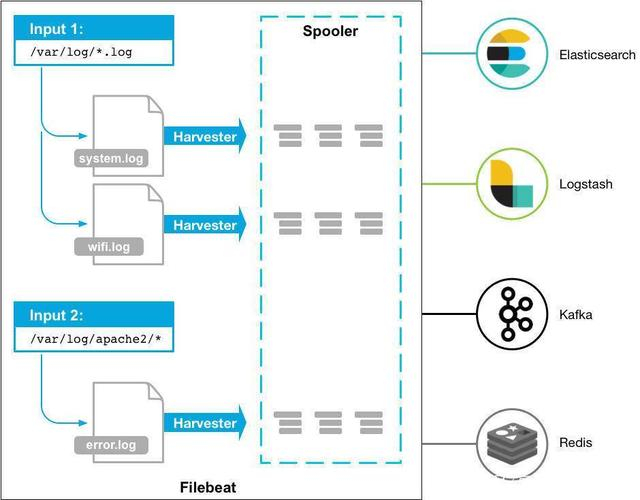
Filebeat的工作原理:启动Filebeat时,它会启动一个或多个输入,这些输入将查找您为日志数据指定的位置。对于Filebeat找到的每个日志,Filebeat启动一个收集器。
每个收集器为新内容读取单个日志,并将新日志数据发送到libbeat,libbeat聚合事件并将聚合数据发送到您为Filebeat配置的输出。
官方流程图如下:
七、ELK常见架构
最简单的ELK应用架构
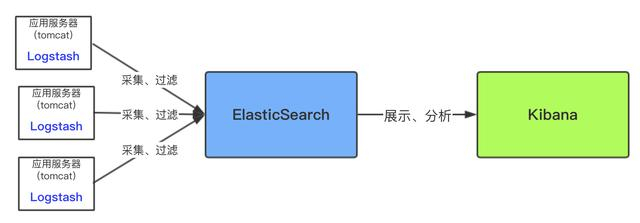
上面架构是简单粗暴的架构,这种架构对数据源服务器(即应用服务器)性能影响较大,因为Logsash是需要安装和运行在需要收集的数据源服务器(即应用服务器)中,然后将收集到的数据实时进行过滤,过滤环节是很耗时间和资源的,过滤完成后才传输到ES中。
下面是优化后的架构图:
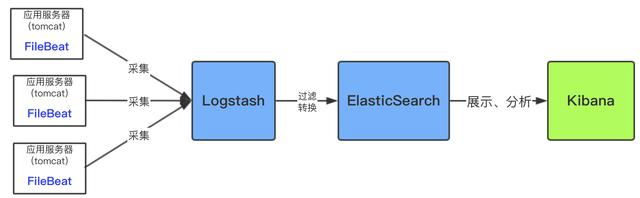
用filebeat采集日志有效降低了收集日志对业务系统的系统资源的消耗。再通过logstash服务器可以过滤,转换日志。这样即满足了日志的过滤转换,也保障了业务系统的性能。
当然上面的架构中,是支持集群的
如果日志文件量特别大,以及收集的服务器日志比较多;这样架构中需加入消息中间件做一下缓冲
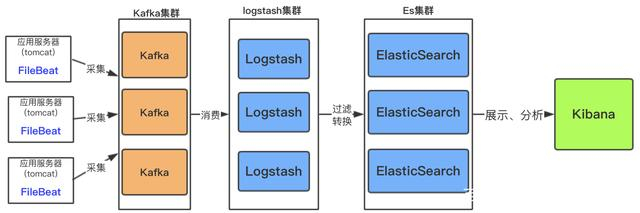
此架构适合大型集群,海量数据的业务场景,消息队列kafka集群架构有效保障了收集数据的安全性和稳定性,而后端logstash和es均采用了集群模式搭建,从整体上提高了ELK的系统的高效性,扩展性和吞吐量。
八、搭建ELK日志分析系统
超详细ELK日志分析系统配置过程 https://blog.csdn.net/weixin_49343462/article/details/112231592