k8s集群监控方案发展: Heapster+cAdvisor-》metrics-server-》prometheus-operator -》kube-prometheus-》kube-prometheus-stack
参考资料
- 官网:https://prometheus-operator.dev/
- prometheus-operator https://github.com/prometheus-operator/prometheus-operator/
- kube-prometheus https://github.com/prometheus-operator/kube-prometheus
- kube-prometheus-stack https://github.com/prometheus-community/helm-charts/tree/main/charts/kube-prometheus-stack
- 【云原生】Kubernetes—-Metrics-Server组件与HPA资源 https://blog.csdn.net/hy199707/article/details/139631044
- k8s全栈监控之metrics-server和prometheus https://www.cnblogs.com/cuishuai/p/9857120.html
- k8s部署Promehteus(kube-prometheus&kube-prometheus-stack)监控 https://www.cnblogs.com/liugp/p/16444580.html
- Prometheus on k8s 部署与实战操作进阶篇 https://baijiahao.baidu.com/s?id=1775453145487726755&wfr=spider&for=pc
k8s集群监控介绍
- metrics-server:核心资源指标收集,用于实时CPU和Mem数据,为kube-scheduler,HPA等k8s核心组件,以及kubectl top命令和Dashboard等UI组件提供数据来源。
-
kube-state-metrics:关注的是K8s对象的状态,比如Deployment的副本数、Pod的状态等,不采集资源使用指标。不要混淆它与metrics-server,两者数据互补。
prometheus-k8s:通常是在Prometheus-Operator部署中的Prometheus实例,主要负责抓取apiserver,scheduler,controller-manager,kubelet组件数据和存储监控数据,提供查询和告警功能。
- prometheus-operator:用来简化和自动化Prometheus的部署管理,比如通过CRD (如 ServiceMonitor) 自动化配置 Prometheus 抓取规则;定义监控目标、服务发现等。
- kube-prometheus: 为基于 Prometheus 和 Prometheus Operator 的完整集群监控堆栈提供示例配置。这包括部署多个 Prometheus 和
Alertmanager 实例、指标导出器(例如用于收集节点指标的 node_exporter)、抓取将 Prometheus
链接到各种指标端点的目标配置,以及用于通知集群中潜在问题的示例警报规则。
- The Prometheus Operator:创建CRD自定义的资源对象
- Highly available Prometheus:创建高可用的Prometheus
- Highly available Alertmanager:创建高可用的告警组件
- Prometheus node-exporter:创建主机的监控组件
- Prometheus Adapter for Kubernetes Metrics APIs:创建自定义监控的指标工具(例如可以通过nginx的request来进行应用的自动伸缩)
- kube-state-metrics:监控k8s相关资源对象的状态指标
- Grafana:进行图像展示
- kube-prometheus-stack: “kube-prometheus-stack” 是 “kube-prometheus” 项目的更新版本,进行了大量的改进和扩展, 它提供了更多的功能、改进和修复, 是一个便捷的综合性监控解决方案,适合在 Kubernetes 环境中快速部署和使用。。
1.Operator介绍
1.1 有状态和无状态的介绍
无状态是指该服务运行的实例不会在本地存储需要持久化的数据,并且多个实例对于同一个请求响应的结果是完全一致的,多个实例可以共享相同的持久化数据。例如:nginx实例,jar实例等。
有状态服务可以说是 需要数据存储功能的服务,每个实例都需要有自己独立的持久化存储。例如:mysql数据库,prometheus等。
无状态相关的k8s资源有:Deployment等。
有状态相关的k8s资源有:StatefulSet等。
Operator的场景就是专门给有状态应用而设计的。
1.2 CRD介绍
CRD,称之为自定义资源定义,其本质上是一段声明:用户定义用户定义的资源对象,配合K8S提供的对象控制器(CRD Controller)来实现资源的管理。
我们在日常使用K8S做编排工作时,经常会管理Deployment、StatefulSet、Service、Job等资源对象,我们可以通过对Yaml文件的编辑实现对各类资源的编排,在通过kubectl等命令,完成像集群资源的申请等操作。但是在日常业务开发过程中,虽然可以通过最基础的资源满足基本需求,但是管理起来往往会很麻烦。
CRD,较好的完善了关于资源自定义的API,开发者可以将原子资源(Deploment、Service、ConfigMap、Job)等统一管理起来,用于表述整个应用程序或某个服务对象。
1.3 operator介绍
Operator旨在简化复杂有状态应用管理的框架,它是一个感知应用状态的控制器,通过扩展Kubernetes API来自动创建、管理和配置应用实例。
Operator 是由 CoreOS 开发的,用来扩展 Kubernetes API,特定的应用程序控制器,它用来创建、配置和管理复杂的有状态应用,如数据库、缓存和监控系统。Operator 基于 Kubernetes 的资源和控制器概念之上构建,但同时又包含了应用程序特定的领域知识。创建Operator 的关键是CRD(自定义资源)的设计。
operator主要是为解决特定应用或服务关于如何运行、部署及出现问题时如何处理提供的一种特定的自定义方式。比如:
- 按需部署应用服务(总不能用一大堆configmap来管理吧,会很混乱)
- 实现应用状态的备份和还原,完成版本升级,比如数据库 schema 或额外的配置设置的改动
- 为分布式应用进行master选举,例如etcd,或者master-slave架构的mysql集群。
当前CoreOS提供的以下四种Operator:
- etcd:创建etcd集群
- Rook:云原生环境下的文件、块、对象存储服务
- Prometheus:创建Prometheus监控实例
- Tectonic:部署Kubernetes集群
2.Prometheus Operator介绍
Prometheus Operator 为 Kubernetes 提供了对 Prometheus 机器相关监控组件的本地部署和管理方案,该项目的目的是为了简化和自动化基于 Prometheus 的监控栈配置,主要包括以下几个功能:
- Kubernetes 自定义资源:使用 Kubernetes CRD 来部署和管理 Prometheus、Alertmanager 和相关组件。
- 简化的部署配置:直接通过 Kubernetes 资源清单配置 Prometheus,比如版本、持久化、副本、保留策略等等配置。
- Prometheus 监控目标配置:基于熟知的 Kubernetes 标签查询自动生成监控目标配置,无需学习 Prometheus 特地的配置。
Prometheus Operator架构图:
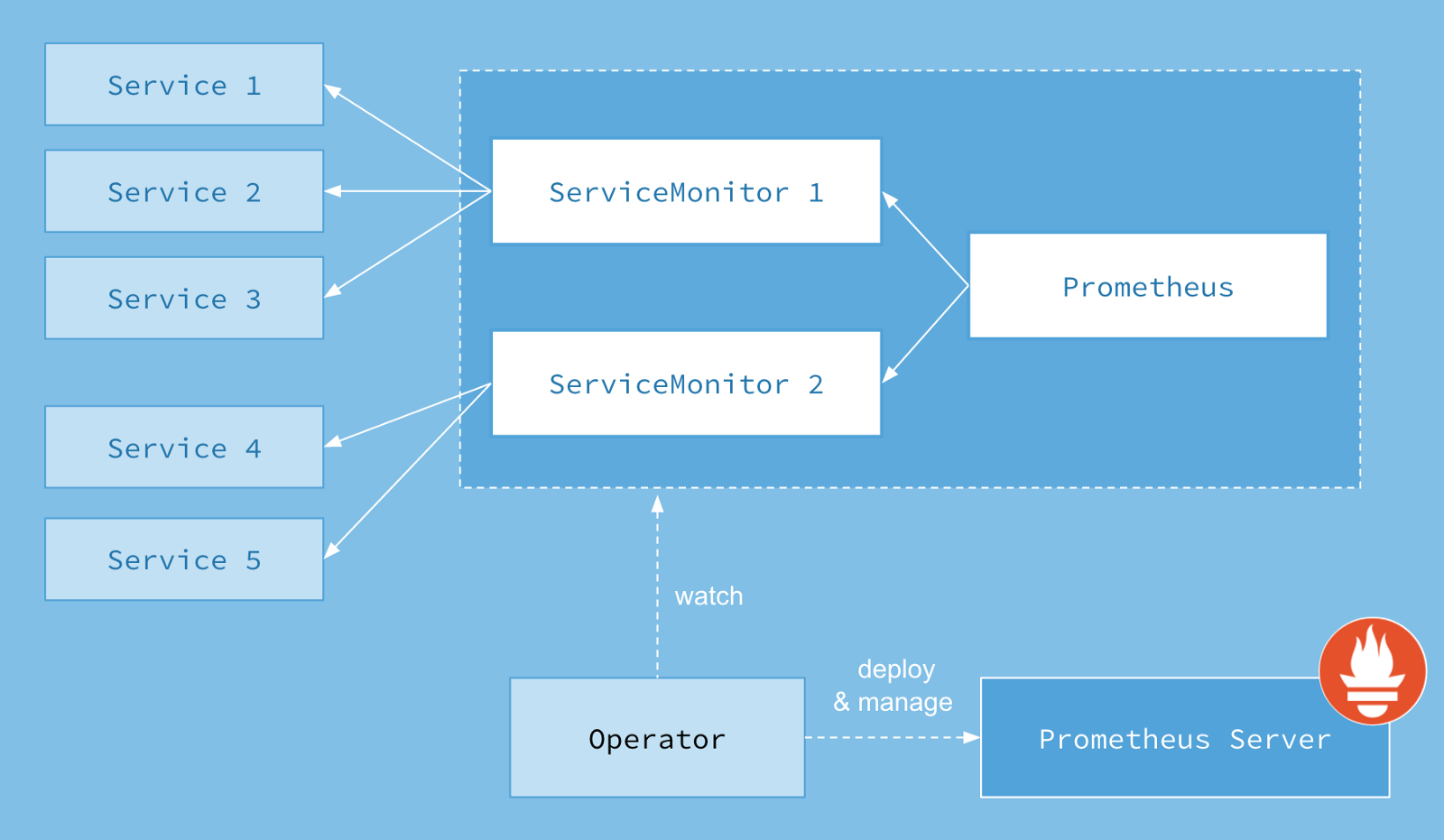
图上的每一个对象都是 Kubernetes 中运行的资源。
Operator是最核心的部分,作为一个控制器,他会去创建Prometheus、PodMonitor、ServiceMonitor、AlertManager以及PrometheusRule这5个CRD资源对象,然后会一直监控并维持这5个资源对象的状态。
其中创建的Prometheus这种资源对象就是作为Prometheus Server存在,而PodMonitor和ServiceMonitor就是exporter的各种抽象,是用来提供专门提供metrics数据接口的工具,Prometheus就是通过PodMonitor和ServiceMonitor提供的metrics数据接口去pull数据的,当然alertmanager这种资源对象就是对应的AlertManager的抽象,而PrometheusRule是用来被Prometheus实例使用的报警规则文件。
Operator
Operator 即 Prometheus Operator,在 Kubernetes 中以 Deployment 运行。其职责是部署和管理 Prometheus Server,根据
ServiceMonitor 动态更新 Prometheus Server 的监控对象。
Prometheus Server
Prometheus Server 会作为 Kubernetes 应用部署到集群中。为了更好地在 Kubernetes 中管理 Prometheus,CoreOS 的开发人员专门定义了一个命名为
Prometheus 类型的 Kubernetes 定制化资源。我们可以把 Prometheus看作是一种特殊的 Deployment,它的用途就是专门部署 Prometheus
Server。
Service
这里的 Service 就是 Cluster 中的 Service 资源,也是 Prometheus 要监控的对象,在 Prometheus 中叫做 Target。每个监控对象都有一个对应的
Service。比如要监控 Kubernetes Scheduler,就得有一个与 Scheduler 对应的 Service。当然,Kubernetes 集群默认是没有这个 Service
的,Prometheus Operator 会负责创建。
ServiceMonitor
Operator 能够动态更新 Prometheus 的 Target 列表,ServiceMonitor 就是 Target 的抽象。比如想监控 Kubernetes
Scheduler,用户可以创建一个与 Scheduler Service 相映射的 ServiceMonitor 对象。Operator 则会发现这个新的 ServiceMonitor,并将
Scheduler 的 Target 添加到 Prometheus 的监控列表中。
ServiceMonitor 也是 Prometheus Operator 专门开发的一种 Kubernetes 定制化资源类型。
Alertmanager
除了 Prometheus 和 ServiceMonitor,Alertmanager 是 Operator 开发的第三种 Kubernetes 定制化资源。我们可以把 Alertmanager
看作是一种特殊的 Deployment,它的用途就是专门部署 Alertmanager 组件。
3.kube-prometheus安装
- prometheus-operator https://github.com/prometheus-operator/prometheus-operator/
- kube-prometheus https://github.com/prometheus-operator/kube-prometheus
使用kube-prometheus安装
## 下载yuml,部署
git clone https://github.com/coreos/kube-prometheus.git
cd kube-prometheus/manifests/setup
kubectl apply -f .
## 查看创建的pod:
kubectl get pod -n monitoring
## 查看创建的Service
kubectl get svc -n monitoring
## 查看grafana
http://ip:30772/
## 查看prometheus
http://ip:31656/targets
4.使用Helm3安装kube-prometheus-stack
# 添加repo
$ helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
$ helm repo update
$ helm search repo prometheus-community/prometheus
# 拉包
$ helm pull prometheus-community/kube-prometheus-stack
# 解包
$ tar -xf kube-prometheus-stack-19.2.3.tgz
# 创建命名空间
$ kubectl create ns kube-prometheus-stack
$ helm install mykube-prometheus-stack kube-prometheus-stack \
-n kube-prometheus-stack \
--set prometheus-node-exporter.hostRootFsMount=false \
--set prometheus.ingress.enabled=true \
--set prometheus.ingress.hosts='{prometheus.k8s.local}' \
--set prometheus.ingress.paths='{/}' \
--set prometheus.ingress.pathType=Prefix \
--set alertmanager.ingress.enabled=true \
--set alertmanager.ingress.hosts='{alertmanager.k8s.local}' \
--set alertmanager.ingress.paths='{/}' \
--set alertmanager.ingress.pathType=Prefix \
--set grafana.ingress.enabled=true \
--set grafana.ingress.hosts='{grafana.k8s.local}' \
--set grafana.ingress.paths='{/}' \
--set grafana.ingress.pathType=Prefix
#清理
$ helm uninstall mykube-prometheus-stack -n kube-prometheus-stack