应用监控、告警-Prometheus
参考资料
- 官网:https://prometheus.io/docs/introduction/overview/
- 下载:https://prometheus.io/download/
- 教程文档:
-
Kubernetes技术栈 青牛踏雪的博客prometheus:https://www.prometheus.wang/ - yunlzheng博客-prometheus-book:https://yunlzheng.gitbook.io/prometheus-book/
- 看云博客Prometheus:https://www.kancloud.cn/jiaxzeng/kubernetes/3125895
-
- 监控平台搭建博客:Prometheus + Grafana
- 耳东xErdong博客 https://blog.51cto.com/erdong/category1/p_2
- 监控系统部署-普罗米修斯 https://blog.51cto.com/u_64214/5602483
- Prometheus+Grafana+alertmanager构建企业级监控系统 https://www.cnblogs.com/yangmeichong/category/2185187.html
- prometheus之记录规则(recording rules)与告警规则(alerting rule)
- 使用prometheus exporter实现rocketmq集群监控指标采集
- https://blog.csdn.net/u012867699/article/details/138344866
- https://blog.csdn.net/sinat_14840559/article/details/119782996
- https://blog.csdn.net/zpsimon/article/details/124249989
- Dashboard:https://grafana.com/grafana/dashboards/14612-rocketmq/
- prometheus监控rabbitmq,rabbitmq_exporter
- https://www.cnblogs.com/user-sunli/p/16178925.html
一、Prometheus简介
Prometheus受启发于Google的Brogmon监控系统(相似的Kubernetes是从Google的Brog系统演变而来),从2012年开始由前Google工程师在Soundcloud以开源软件的形式进行研发的系统监控和告警工具,
Prometheus 于 2016 年加入了 CNCF,成为了继 Kubernetes 之后的第二个托管项目。
1.1 特性
- 强大的查询功能:Prometheus灵活的查询语言PromQL能够对收集的时间序列数据进行切片和分片,以便生成特定的图、表和警报。
- 高效的存储:Prometheus以一种高效的自定义格式将时序数据存储在内存和本地磁盘上。不依赖分布式存储;单服务器节点是自治的。
- 便于可视化:Prometheus有多种可视化数据的模式:内置表达式浏览器、Grafana集成和控制台模板语言。
- 操作简单:每台服务器都是独立的,只依赖于本地存储。所有二进制文件都是静态链接的,易于部署。
- 警报精确:告警是根据Prometheus灵活的PromQL定义并传递到Alertmanager。再由Alertmanager负责管理、整合和分发各种警报到不同地目的地。
- 大量的集成:现有的Exporters允许将第三方数据连接到Promehteus。示例:系统统计信息,以及Docker、HAProxy、StatsD和JMX metrics。
1.2 局限性
- Prometheus 是基于 Metric 的监控,不适用于日志(Logs)、事件(Event)、调用链(Tracing)。
- Prometheus 默认是 Pull 模型,合理规划你的网络,尽量不要转发。
- 对于集群化和水平扩展,官方和社区都没有银弹,需要合理选择 Federate、Cortex、Thanos等方案。
- 监控系统一般情况下可用性大于一致性,容忍部分副本数据丢失,保证查询请求成功。这个后面说 Thanos 去重的时候会提到。
- Prometheus 不一定保证数据准确,这里的不准确一是指 rate、histogram_quantile 等函数会做统计和推断,产生一些反直觉的结果,这个后面会详细展开。二来查询范围过长要做降采样,势必会造成数据精度丢失,不过这是时序数据的特点,也是不同于日志系统的地方。
1.3 组件
- Prometheus Server: 用于收集和存储时间序列数据。Prometheus Server是Prometheus组件中的核心部分,负责实现对监控数据的获取,存储以及查询。
- 可以通过静态配置管理监控目标,也可以配合使用Service Discovery的方式动态管理监控目标
- Exporters: 用于暴露已有的第三方服务的 metrics 给 Prometheus。Exporter将监控数据采集的端点通过HTTP服务的形式暴露给Prometheus Server,Prometheus Server通过访问该Exporter提供的Endpoint端点,即可获取到需要采集的监控数据。
- Alertmanager: 从 Prometheus server 端接收到 alerts 后,会进行去除重复数据,分组,并路由到对方的接受方式,发出报警。常见的接收方式有:电子邮件,pagerduty 等。
- WEB UI:Prometheus Server内置的Express Browser UI,通过这个UI可以直接通过PromQL实现数据的查询以及可视化。 一些其他的工具。
- Push Gateway: 主要用于短期的 jobs。由于这类 jobs 存在时间较短,可能在 Prometheus 来 pull 之前就消失了。为此,这些 jobs 可以直接向 Prometheus server 端推送它们的 metrics。
- Client Library: 客户端库,为需要监控的服务生成相应的 metrics 并暴露给 Prometheus server。当 Prometheus server 来 pull 时,直接返回实时状态的 metrics。
1.4 存储引擎
TSDB 作为 Prometheus 的存储引擎完美契合了监控数据的应用场景:
- 存储的数据量级十分庞大
- 大部分时间都是写入操作
- 写入操作几乎是顺序添加,大多数时候数据到达后都以时间排序
- 写操作很少写入很久之前的数据,也很少更新数据。大多数情况在数据被采集到数秒或者数分钟后就会被写入数据库
- 删除操作一般为区块删除,选定开始的历史时间并指定后续的区块。很少单独删除某个时间或者分开的随机时间的数据
- 基本数据大,一般超过内存大小。一般选取的只是其一小部分且没有规律,缓存几乎不起任何作用
- 读操作是十分典型的升序或者降序的顺序读
- 高并发的读操作十分常见
1.5 架构
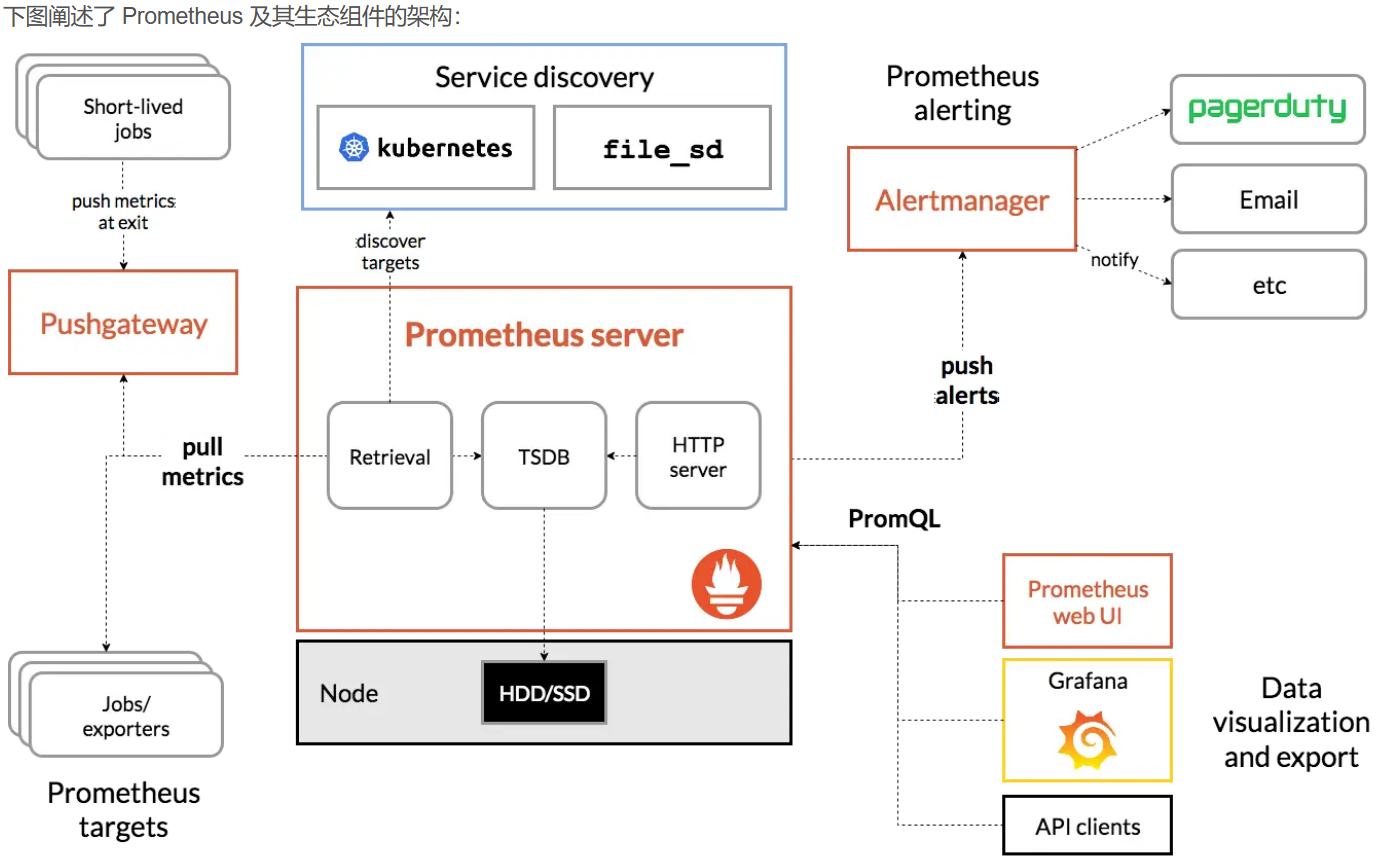
整个 Prometheus 可以分为四大部分
- Prometheus 服务器:Prometheus Server 是 Prometheus 组件中的核心部分,负责实现对监控数据的获取,存储以及查询。
- NodeExporter 业务数据源:业务数据源通过 Pull/Push 两种方式推送数据到 Prometheus Server。
- AlertManager 报警管理器:Prometheus 通过配置报警规则,如果符合报警规则,那么就将报警推送到 AlertManager,由其进行报警处理。
- 可视化监控界面:Prometheus 收集到数据之后,由 WebUI 界面进行可视化图标展示。目前我们可以通过自定义的 API 客户端进行调用数据展示,也可以直接使用 Grafana 解决方案来展示。
Prometheus 的实现架构并不复杂。其实就是收集数据、处理数据、可视化展示,再进行数据分析进行报警处理
1.6 高可用、联邦集群
在默认情况下,用户只需要部署多套 Prometheus,采集相同的 Targets 即可实现基本的 HA。
由于 Prometheus 基于 Pull 模型,当有大量的 Target 需要采样本时,单一 Prometheus 实例在数据抓取时可能会出 现一些性能问题,联邦集群的特性可以让 Prometheus 将样本采集任务划分到不同的 Prometheus 实例中,并且通 过一个统一的中心节点进行聚合,从而可以使 Prometheuse 可以根据规模进行扩展。
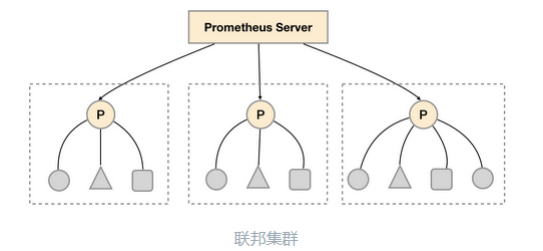
如上图所示,在每个数据中心部署单独的 Prometheus Server,用于采集当前数据中心监控数据。并由一个中 心的 Prometheus Server 负责聚合多个数据中心的监控数据。这一特性在 Promthues 中称为联邦集群。
1.7 告警
通过在 Prometheus 中定义 AlertRule(告警规则),Prometheus 会周期性的对告警规则进行计算,如果满足告警 触发条件就会向 Alertmanager 发送告警信息
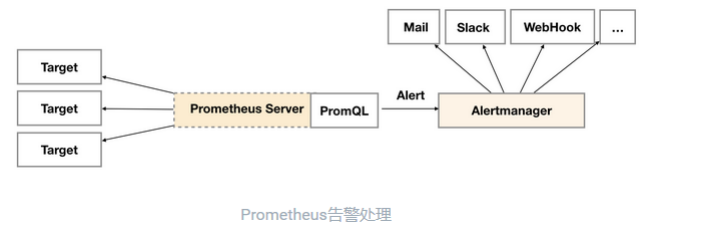
在 Prometheus 中一条告警规则主要由以下几部分组成:
- 告警名称:用户需要为告警规则命名,当然对于命名而言,需要能够直接表达出该告警的主要内容
- 告警规则:告警规则实际上主要由 PromQL 进行定义,其实际意义是当表达式(PromQL)查询结果持续多长 时间(During)后出发告警
Alertmanager 特性:
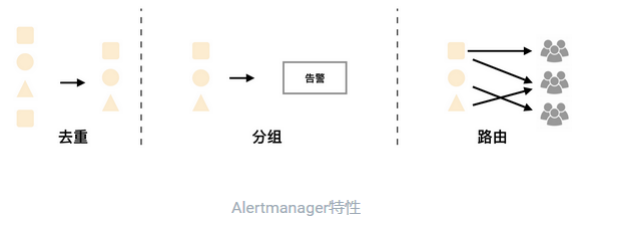
- 分组:分组机制可以将详细的告警信息合并成一个通知。在某些情况下,比如由于系统宕机导致大量的告警被同时触 发,在这种情况下分组机制可以将这些被触发的告警合并为一个告警通知,避免一次性接受大量的告警通知,而无 法对问题进行快速定位。
- 抑制:抑制是指当某一告警发出后,可以停止重复发送由此告警引发的其它告警的机制。 例如,当集群不可访问时触发了一次告警,通过配置 Alertmanager 可以忽略与该集群有关的其它所有告警。 这样可以避免接收到大量与实际问题无关的告警通知。抑制机制同样通过 Alertmanager 的配置文件进行设置。
- 静默:静默提供了一个简单的机制可以快速根据标签对告警进行静默处理。如果接收到的告警符合静默的配置, Alertmanager 则不会发送告警通知。 静默设置需要在 Alertmanager 的 Werb 页面上进行设置。
二、部署 Prometheus
- 安装Prometheus Server https://www.prometheus.wang/quickstart/install-prometheus-server.html
- https://blog.51cto.com/u_64214/5602483
2.1 离线tar部署Prometheus
## 下载从https://prometheus.io/download/找到最新版本的Prometheus Sevrer软件包:
export VERSION=2.13.0
curl -LO https://github.com/prometheus/prometheus/releases/download/v$VERSION/prometheus-$VERSION.darwin-amd64.tar.gz
## 解压,并将Prometheus相关的命令,添加到系统环境变量路径即可:
tar -xzf prometheus-${VERSION}.darwin-amd64.tar.gz
cd prometheus-${VERSION}.darwin-amd64
## 解压后当前目录会包含默认的Prometheus配置文件promethes.yml:
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: 'prometheus'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ['localhost:9090']
## Promtheus作为一个时间序列数据库,其采集的数据会以文件的形似存储在本地中,默认的存储路径为data/,因此我们需要先手动创建该目录:
mkdir -p data
用户也可以通过参数--storage.tsdb.path="data/"修改本地数据存储的路径。
## 启动prometheus服务,其会默认加载当前路径下的prometheus.yaml文件
nohup ./prometheus --config.file=prometheus.yml &
2.2 docker部署 Prometheus
docker run -p 9090:9090 -v /etc/prometheus/prometheus.yml:/etc/prometheus/prometheus.yml prom/prometheus
三、部署xx-Exporter采集主机、中间件、集群运行数据
3.1 离线tar包部署Node Exporter采集主机运行数据
## 从https://prometheus.io/download/获取最新的node exporter版本的二进制包。
curl -OL https://github.com/prometheus/node_exporter/releases/download/v0.17.0/node_exporter-0.17.0.linux-amd64.tar.gz
tar -xzf node_exporter-0.17.0.linux-amd64.tar.gz
cd node_exporter-0.17.0.linux-amd64/
mv node_exporter /usr/local/bin/
## 配置脚本/etc/rc.d/init.d/node_exporter
cat >> /etc/rc.d/init.d/node_exporter <<EOF
#!/bin/bash
#
# /etc/rc.d/init.d/node_exporter
#
# Prometheus node exporter
#
# description: Prometheus node exporter
# processname: node_exporter
# Source function library.
. /etc/rc.d/init.d/functions
PROGNAME=node_exporter
PROG=/usr/local/bin/$PROGNAME
USER=root
LOGFILE=/var/log/prometheus.log
LOCKFILE=/var/run/$PROGNAME.pid
start() {
echo -n "Starting $PROGNAME: "
cd /opt/prometheus/
daemon --user $USER --pidfile="$LOCKFILE" "$PROG &>$LOGFILE &"
echo $(pidofproc $PROGNAME) >$LOCKFILE
echo
}
stop() {
echo -n "Shutting down $PROGNAME: "
killproc $PROGNAME
rm -f $LOCKFILE
echo
}
case "$1" in
start)
start
;;
stop)
stop
;;
status)
status $PROGNAME
;;
restart)
stop
start
;;
reload)
echo "Sending SIGHUP to $PROGNAME"
kill -SIGHUP $(pidofproc $PROGNAME)#!/bin/bash
;;
*)
echo "Usage: service node_exporter {start|stop|status|reload|restart}"
exit 1
;;
esac
EOF
## 运行node exporter
service node_exporter start
## 启动成功后,查看端口
netstat -anplt|grep 9100
## 访问http://localhost:9100/metrics,可以看到当前node exporter获取到的当前主机的所有监控数据
## 修改Prometheus配置文件, Prometheus Server能够从node exporter获取到监控数据
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
# 采集node exporter监控数据
- job_name: 'node'
static_configs:
- targets: ['localhost:9100']
## 重启Prometheus
3.2 node_exporter部署之认证(启用 TLS)
- https://blog.csdn.net/weixin_42562106/article/details/117367297
- https://blog.csdn.net/scand123/article/details/137275087
- –web.config高版本参数改成了–web.config.file
3.3 配置node-exporter参数
- https://github.com/prometheus/node_exporter
- https://www.cnblogs.com/heian99/p/17026955.html
四、Grafana配置Prometheus数据源、添加各类指标监控面板
4.1 离线部署Grafana:
参考https://wdsheng0i.github.io/dev-ops/2021/03/28/loki.html
4.2 Grafana添加Prometheus数据源、导入node-dashboard.json
浏览器访问:https://grafana.com/grafana/dashboards ,在页面中搜索 node exporter,在 grafana 页面中,+ Create -> Import ,输入面板 ID 号或者上传 JSON 文件,点击 Load,即可导入监控面板
五、k8s部署 Prometheus + Grafana
- Kubernetes + Prometheus + Grafana + Exporter部署笔记: https://juejin.cn/post/6844903758384594951
- k8s + prometheus + grafana + Exporter + alertmanager监控加邮件告警: https://blog.csdn.net/weixin_49343462/article/details/121839755?spm=1001.2014.3001.5501
六、AlertManager部署、告警规则配置
6.1 二进制包离线部署alertmanager
alertmanager最新版本的下载地址可以从Prometheus官方网站https://prometheus.io/download/获取。
# 1.下载解压
下载地址:https://prometheus.io/download/#alertmanager
上传解压:tar xvf alertmanager-$VERSION.darwin-amd64.tar.gz
# 2.
6.2 docker部署alertmanager
docker run --name alertmanager -d -p 9093:9093 quay.io/prometheus/alertmanager
6.3 告警阈值维护说明
七、Exporter分类
广义上讲所有可以向Prometheus提供监控样本数据的程序都可以被称为一个Exporter。而Exporter的一个实例称 为target
从Exporter的来源上来讲,主要分为两类:
7.1 开源社区提供的exporter、采集方案:
- 主机监控:node_exporter
- 数据库监控:mysql-exporter…
- 消息队列监控:kafka-exporter…
- redis监控:redis-exporter…
- zookeeper监控:zookeeper-exporter
- https://blog.csdn.net/weixin_42467874/article/details/127548045
- http服务中间件监控:nginx_exporter…
- http拨测、TLS证书监控:blackbox…
- 进程监控:process_exporter
- 容器监控:cAdvisor部署
- GPU监控:dcgm-exporter

7.2 用户自定义的exporter
用户还可以基于Prometheus提供的Client Library创建自己的 Exporter程序,目前Promthues社区官方提供了对以下编程语言的支持:Go、Java/Scala、Python、Ruby。同 时还有第三方实现的如:Bash、C++、Common Lisp、Erlang,、Haskeel、Lua、Node.js、PHP、Rust等。