参考资料
java架构直通车-第7周 主从复制高可用Redis集群
java架构直通车-第8周 Redis缓存雪崩,穿透
一.分布式架构概述 + Redis入门与基础
1-1 分布式架构概述
系统架构尽量不要过度设计,最好随着业务发展扩大来演进
- 单体架构:
- 优点:
- 小团队、迭代周期短、速度快、部署运维简单
- 缺点:
- 单节点宕机即服务不可用(解决方案:多节点、集群)
- 系统复杂后耦合度高(解决方案:服务拆分解耦、微服务)
- 单节点并发能力有限(解决方案:负载均衡分摊压力)
- 优点:
- 集群架构:多节点组成,每个节点服务相同
- 优点:
- 高可靠:提高单体应用的并发能力
- 高可用:单节点宕机仍可用
- 可扩展性:增减节点
- 缺点:
- 分布式会话
- 定时任务、mq延时任务实现定时任务
- 部署复杂
- 优点:
- 分布式架构:不同业务子系统部署在不同服务器上;
- 每个子系统可负责一个或多个业务
- 子系统(服务)间可通信
- 子系统可集群部署
- 对用户透明
- 优点:
- 业务解耦
- 系统模块化,可复用化
- 提高系统并发:因为业务请求被分散到不同服务器上
- 缺点:
- 架构复杂度增加
- 调试复杂
- 部署复杂
- 子系统通信耗时、异常状况
- 新人融入慢
- 设计原则
- 异步解耦,mq
- 幂等一致性
- 拆分原则
- 融合分布式中间件
- 容错、高可用
1-2 分布式缓存,Redis,Redis使用场景
为什么使用分布式缓存
再分布式架构中(分布式服务器节点)使用的缓存技术,最著名的分布式缓存例子莫过于Memcached、 Redis
- 内存式缓存:高性能的读取速度
- 缓冲:能有效地降低对后台数据库服务器的压力
- 跨服务器缓存:进行分布式计算
为何引入Redis
二八原则:80%是读操作
Redis是一种Key-Value键值型的高性能的内存数据库
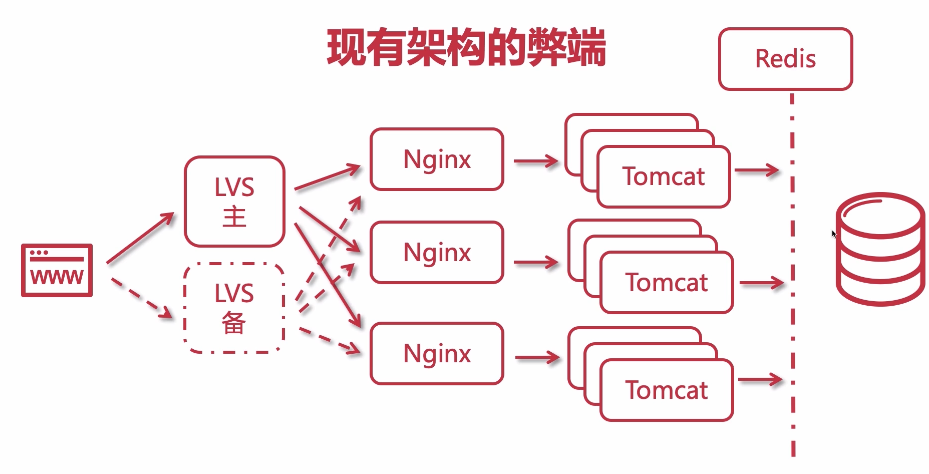
Redis适用场景
Redis应用场景
Redis常见应用场景
Redis-使用场景
- 缓存(数据查询、短连接、新闻内容、商品内容等等)(最多使用) 采用Redis的List数据结构方便实现最新列表 等业务场景
- 商品列表
- 收藏列表
- 好友列表
- 评论列表
- @提示列表
- 应用排行榜:sorted set 多了一个权重参数score,集合中元素能够按score进行排列
- 任务队列(秒杀、抢购、12306等等)
- 消息队列
- 数据过期处理(可以精确到毫秒):登录验证码,短信验证码
- 分布式集群架构中的session:使用hash数据类型
- 存储社交关系:
- 聊天室的在线好友列表
- 好友/粉丝/关注,可以存set中,用交集、并集、差集等操作,可计算共同喜好,全部的喜好,自己独有的喜好等功能
- 各种计数:Redis的命令都是原子性的,String数据结构可以轻松地利用INCR,DECR等命令来计数。
- 商品维度计数(喜欢数,评论数,鉴定数,浏览数,etc)
- 用户维度计数(动态数、关注数、粉丝数、喜欢商品数、发帖数 等)
- 网站访问统计
1-3 分布式缓存方案与技术选型对比:Redis VS Memcache VS Ehcache
https://www.cnblogs.com/qlqwjy/p/7788912.html
Redis
Redis是一个开源的使用ANSIC语言编写、支持网络、可基于内存亦可持久化的日志型、高性能的Key-Value数据库
- 优点
- 内存数据库:性能极高 – Redis能支持超过 100K+ 每秒的读写频率。
- 可持久化:
- 丰富的数据类型: String, List, Hash, Set, sorted Set
- 支持分布式、集群、主从同步备份等
- 线程安全:单进程单线程
- 采用 IO 多路复用机制,非阻塞IO(epoll)
- 丰富的特性: Redis还支持 publish/subscribe, 通知, key 过期等等特性。
- 原子: Redis的所有操作都是原子性的,同时Redis还支持对几个操作全并后的原子性执行。
- 缺点
- 数据库容量受到物理内存的限制
- 单进程单线程
Ehcache
是一个纯Java的进程内缓存框架,具有快速、精干等特点,是Hibernate中默认CacheProvider
- 优缺点:
- 基于JVM快速、简单;
- 集群、分布式架构下 不支持
Memcached
基于一个存储键/值对的hashmap。其守护进程(daemon)是用C写的,但是客户端可以用任何语言来编写,并通过memcached协议与守护进程通信
- 优缺点:
- 内存数据库:性能极高
- 多核处理,多线程
- 无法持久化,无法容灾
- 数据类型单一:String
1-4 Redis单机部署与配置
1 Linux环境安装
2 windows环境安装
3 reids配置详解
==基本配置
daemonize no 是否以后台进程启动
databases 16 创建database的数量(默认选中的是database 0)
save 900 1 #刷新快照到硬盘中,必须满足两者要求才会触发,即900秒之后至少1个关键字发生变化。
save 300 10 #必须是300秒之后至少10个关键字发生变化。
save 60 10000 #必须是60秒之后至少10000个关键字发生变化。
stop-writes-on-bgsave-error yes #后台存储错误停止写。
rdbcompression yes #使用LZF压缩rdb文件。
rdbchecksum yes #存储和加载rdb文件时校验。
dbfilename dump.rdb #设置rdb文件名。
dir ./ #设置工作目录,rdb文件会写入该目录。
==主从配置
slaveof <masterip> <masterport> 设为某台机器的从服务器
masterauth <master-password> 连接主服务器的密码
slave-serve-stale-data yes # 当主从断开或正在复制中,从服务器是否应答
slave-read-only yes #从服务器只读
repl-ping-slave-period 10 #从ping主的时间间隔,秒为单位
repl-timeout 60 #主从超时时间(超时认为断线了),要比period大
slave-priority 100 #如果master不能再正常工作,那么会在多个slave中,选择优先值最小的一个slave提升为master,优先值为0表示不能提升为master。
repl-disable-tcp-nodelay no #主端是否合并数据,大块发送给slave
slave-priority 100 从服务器的优先级,当主服挂了,会自动挑slave priority最小的为主服
===安全
requirepass foobared # 需要密码
rename-command CONFIG b840fc02d524045429941cc15f59e41cb7be6c52 #如果公共环境,可以重命名部分敏感命令 如config
===限制
maxclients 10000 #最大连接数
maxmemory <bytes> #最大使用内存
maxmemory-policy volatile-lru #内存到极限后的处理
volatile-lru -> LRU算法删除过期key
allkeys-lru -> LRU算法删除key(不区分过不过期)
volatile-random -> 随机删除过期key
allkeys-random -> 随机删除key(不区分过不过期)
volatile-ttl -> 删除快过期的key
noeviction -> 不删除,返回错误信息
#解释 LRU ttl都是近似算法,可以选N个,再比较最适宜T踢出的数据
maxmemory-samples 3
====日志模式
appendonly no #是否仅要日志
appendfsync no # 系统缓冲,统一写,速度快
appendfsync always # 系统不缓冲,直接写,慢,丢失数据少
appendfsync everysec #折衷,每秒写1次
no-appendfsync-on-rewrite no #为yes,则其他线程的数据放内存里,合并写入(速度快,容易丢失的多)
auto-AOF-rewrite-percentage 100 当前aof文件是上次重写是大N%时重写
auto-AOF-rewrite-min-size 64mb aof重写至少要达到的大小
====慢查询
slowlog-log-slower-than 10000 #记录响应时间大于10000微秒的慢查询
slowlog-max-len 128 # 最多记录128条
1-5 Redis命令行客户端redis-cli基本使用
redis-cli :进入到redis客户端
auth pwd :输入密码
set key value :设置缓存
get key :获得缓存
del key :删除缓存
exists key:判断某个key是否存在
redis-cli -a password ping :查看是否存活
keys *:查看所有的key (不建议在生产上使用,有性能影响)
type key:key的类型
SETNX:是「SET if Not eXists」的缩写,就是只有key不存在时才设置值,可以防止覆盖数据
- 用途:用来实现分布式锁
禁用:flushall 清空整个 Redis 服务器的数据(删除所有数据库的所有 key )
注意:如果不小心运行了flushall,立即shutdown nosave,关闭服务器,然后手工编辑aof文件,去掉文件中的flushall相关行,然后开启服务器,就可以倒回原来是数据。如果flushall之后,系统恰好bgwriteaof了,那么aof就清空了,数据丢失。
select index:切换数据库,总共默认16个
save:保存rdb快照
lastsave:上次保存时间
shutdown [save/nosave]
showlog:显示慢查询
quit #退出连接
1-6 Redis的数据类型 - string
String(最大512M):Value 不仅是 String,也可以是数字
- set key value [ex 秒数] [px 毫秒数] [nx/xx]如果ex和px同时写,则以后面的有效期为准 nx:如果key不存在则建立
xx:如果key存在则修改其值 - setnx rekey data:设置已经存在的key,不会覆盖
- get/set/del:查询/设置/删除
- mset key1 value1 key2 value2 一次设置多个值
- mget key1 key2 :一次获取多个值
- msetnx:连续设置,如果存在则不设置
- append key value :把value追加到key 的原值上
- setrange key offset value:把字符串的offset偏移字节改成value 如果偏移量 > 字符串长度,该字符自动补0x00
- getrange key start end:截取数据,end=-1 代表到最后
- setrange key start newdata:从start位置开始替换数据
- getrange key start stop:获取字符串中[start,stop]范围的值,下标,左数从0开始,右数从-1开始 注意:当start> length,则返回空字符串,当stop>=length,则截取至字符串尾,如果start所处位置在stop右边,则返回空字符串
- getset key nrevalue:获取并返回旧值,在设置新值
- incr key:自增1,返回新值,如果incr一个不是int的value则返回错误,incr一个不存在的key,则设置key为1
- decr key:类减1
- incrby key 2:跳2自增
- incrbyfloat by 0.7: 自增浮点数
- decrby key num:累减给定数值
- setbit key offset value:设置offset对应二进制上的值,返回该位上的旧值 注意:如果offset过大,则会在中间填充0 , offset最大到多少: 2^32-1,即可推出最大的字符串为512M
- bitop operation destkey key1 [key2..]对key1、key2做opecation并将结果保存在destkey上 opecation可以是AND OR NOT XOR
- strlen key:取指定key的value值的长度
- setex key time value:设置key对应的值value,并设置有效期为time秒
1-7 Redis的数据类型 - hash
Hash:Hash 是一个 String 的 Key 和 Value 的映射表,Hash 特别适合存储对象。常用命令:hget,hset,hgetall 等
hash:类似map,存储结构化数据结构,比如存储一个对象(不能有嵌套对象)
Redis hash 是一个string类型的field和value的映射表,它的添加、删除操作都是O(1) (平均)。hash特别适用于存储对象,将一个对象存储在hash类型中会占用更少的内存,并且可以方便的存取整个对象。
配置: hash_max_zipmap_entries 64 #配置字段最多64个 hash_max_zipmap_value 512 #配置value最大为512字节
- hset user field value:设置myhash的field为value,例如 “hset user name imooc”-> 创建一个user对象,这个对象中包含name属性,name值为imooc
- hsetnx key field value:不存在的情况下设置myhash的field为value
- hmset key field1 value1 field2 value2:同时设置多个field-> hset user age 18 phone 139123123
- hget key field:获取指定的hash field
- hmget key field1 field2:一次获取多个field
- hincrby key age 2:累加属性
- hincrbyfloat key age 2.2:累加属性
- hexists key age:判断属性是否存在
- hlen key:返回hash的field数量
- hdel key field:删除指定的field
- hkeys key:返回hash所有的field
- hvals key:返回hash所有的value
- hdel key:删除对象
- hgetall key:获取某个hash中全部的field及value:hgetall user:获得整个对象user的内容
1-8 Redis的数据类型 - list
List :双向链表实现,常用命令:lpush、rpush、lpop、rpop、lrange(获取列表片段)等
Redis的list类型其实就是一个每个子元素都是string类型的双向链表,链表的最大长度是2^32。
list既可以用做栈,也可以用做队列。
list的pop操作还有阻塞版本,主要是为了避免轮询
- lpush key value:把值插入到链表头部: lpush userList 1 2 3 4 5:构建一个list,从左边开始存入数据
- rpush key value:把值插入到链表尾部: rpush userList 1 2 3 4 5:构建一个list,从右边开始存入数据
- lpop key :返回并删除链表头部元素,从左侧开始拿出一个数据
- rpop key: 返回并删除链表尾部元素,从右侧开始拿出一个数据
- lrange key start stop:返回链表中[start, stop]中的元素
- lrem key count value:从链表中删除value值,删除count的绝对值个value后结束,count > 0 从表头删除 count < 0 从表尾删除 count=0 全部删除
- lset list index value:把某个下标的值替换
- lrem list num value:删除几个相同数据
- ltrim key start stop:剪切key对应的链接,切[start, stop]一段并把改制重新赋给key
- lindex list index:获取list下标的值
- llen key:计算链表的元素个数
- llen list:list长度
-
linsert key after before searchValue value:在key 链表中寻找search,并在searchValue值之前 之后插入value - rpoplpush source dest:把source 的末尾拿出,放到dest头部,并返回单元值 应用场景: task + bak 双链表完成安全队列 业务逻辑: rpoplpush task bak接收返回值并做业务处理,如果成功则rpop bak清除任务,如果不成功,下次从bak表取任务
- brpop,blpop key timeout:等待弹出key的尾/头元素 timeout为等待超时时间,如果timeout为0则一直等待下去,应用场景:长轮询ajax,在线聊天时能用到
1-9 Redis的数据类型 - set
Set :String 类型的无序、去重集合。集合是通过 hashtable 实现的。常用命令:sdd、spop、smembers、sunion
特点:无序性、确定性、唯一性
- (1)sadd key value1 value2:往集合里面添加元素
- (2)smembers key:获取集合所有的元素
- (3)srem key value:删除集合某个元素
- (4)spop key:返回并删除集合中1个随机元素(可以坐抽奖,不会重复抽到某人)
- (5)srandmember key:随机取一个元素
- (6)sismember key value:判断集合是否有某个值
- (7)scard key:返回集合元素的个数
- (8)smove source dest value:把source的value移动到dest集合中
- (9)sinter key1 key2 key3:求key1 key2 key3的交集
- (10)sunion key1 key2:求key1 key2 的并集
- (11)sdiff key1 key2:求key1 key2的差集
- (12)sinterstore res key1 key2:求key1 key2的交集并存在res里
1-10 Redis的数据类型 - zset
Zset :有序的并且不重复的集合,常用命令:zadd、zrange、zrem、zcard 等。
概念:它是在set的基础上增加了一个顺序属性,这一属性在添加修改元素的时候可以指定,每次指定后,zset会自动按新的值调整顺序。可以理解为有两列的mysql表,一列存储value,一列存储顺序,操作中key理解为zset的名字。
和set一样sorted,sets也是string类型元素的集合,不同的是每个元素都会关联一个double型的score。sorted set的实现是skip list和hash table的混合体。
当元素被添加到集合中时,一个元素到score的映射被添加到hash table中,所以给定一个元素获取score的开销是O(1) 。另一个score到元素的映射被添加的skip list,并按照score排序,所以就可以有序地获取集合中的元素。添加、删除操作开销都是O(logN) 和skip list的开销一致,redis的skip list 实现是双向链表,这样就可以逆序从尾部去元素。sorted set最经常使用方式应该就是作为索引来使用,我们可以把要排序的字段作为score存储,对象的ID当元素存储。
- (1)zadd key score1 value1 score2 value2:添加元素
- (2)zrange key start stop [withscores]:把集合排序后,返回名次[start,stop]的元素 默认是升续排列 withscores 是把score也打印出来
- (3)zrank key member:查询member的排名(升序0名开始)
- (4)zrangebyscore key min max [withscores] limit offset N:集合(升序)排序后取score在[min, max]内的元素,并跳过offset个,取出N个
- (5)zrevrank key member:查询member排名(降序 0名开始)
- (6)zremrangebyscore key min max:按照score来删除元素,删除score在[min, max]之间
- (7)zrem key value1 value2:删除集合中的元素
- (8)zremrangebyrank key start end:按排名删除元素,删除名次在[start, end]之间的
- (9)zcard key:返回集合元素的个数
- (10)zcount key min max:返回[min, max]区间内元素数量
- (11)zinterstore dest numkeys key1[key2..] [WEIGHTS weight1 [weight2…]] [AGGREGATE
二.SpringBoot整合Redis实战
- Jedis:是 Redis 官方首选的 Java 客户端开发包
- Redisson:
- spring-boot-starter-data-redis:集成使用RedisTemplate,spring封装Jedis操作
- 可视化工具 redis-desktop-manager
2-1 聊一聊多路复用器,阻塞和非阻塞
2-2 Redis 架构单线程模型原理解析
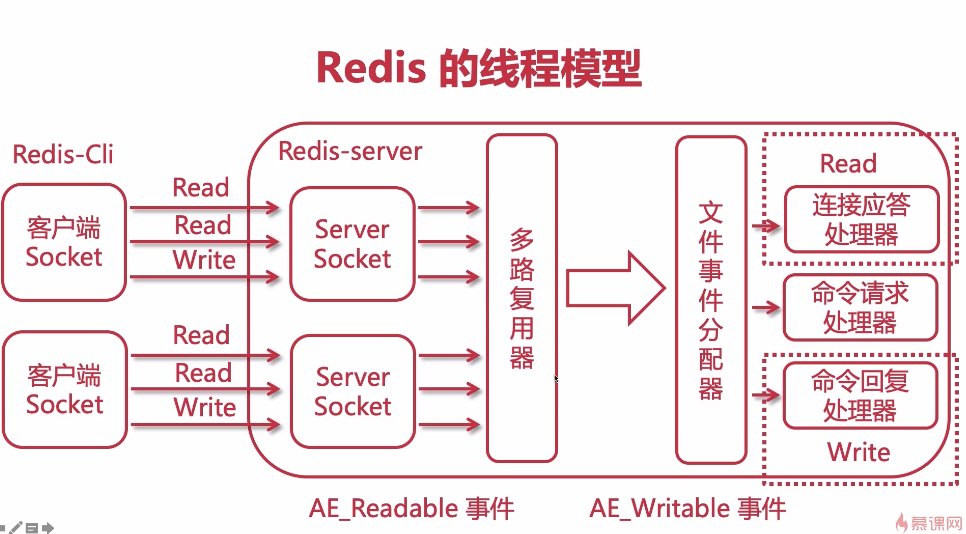
单线程为什么快:
- 非阻塞IO多路复用
- 内存操作
- 单线程避免上下文切换损耗
2-3 SpringBoot整合Redis实战
//1.添加依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
//2.配置Redis,没有设置序列化器RedisTemplate会选择默认序列化器JdkSerializationRedisSerializer
//SpringBoot会自动在容器中生成一个RedisTemplate和一个StringRedisTemplate
//但是这个RedisTemplate的泛型是<Object,Object>,在代码中的需要类型转换,使用不方便、安全,
//并且RedisTemplate没有设置序列化方式,对象的状态信息转为存储或传输的形式需要序列化。
//所以我们需要自己配置RedisConfig:
@Configuration
public class RedisConfig {
@Bean
public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory factory) {
RedisTemplate<String, Object> template = new RedisTemplate<String, Object>();
template.setConnectionFactory(factory);
// 使用Jackson2JsonRedisSerialize 替换默认序列化
Jackson2JsonRedisSerializer jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer(Object.class);
// 如果序列化对象中有日期格式,可以自定义日期的序列化类,处理日期的序列化方式。其他需要序列化的类型,也可以按此处理。
ObjectMapper om = new ObjectMapper();
// 在序列化中增加类信息,否则无法反序列化。
om.enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL);
om.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY);
jackson2JsonRedisSerializer.setObjectMapper(om);
StringRedisSerializer stringRedisSerializer = new StringRedisSerializer();
//key采用String的序列化方式
template.setKeySerializer(stringRedisSerializer);
//value序列化方式采用jackson
template.setValueSerializer(jackson2JsonRedisSerializer);
//hash的key也采用String的序列化方式
template.setHashKeySerializer(stringRedisSerializer);
//hash的value序列化方式采用jackson
template.setHashValueSerializer(jackson2JsonRedisSerializer);
template.afterPropertiesSet();
return template;
}
}
//3.添加配置
spring:
cache:
type: redis
redis:
host: 127.0.0.1
password: 123456
# 连接超时时间(毫秒)
timeout: 10000
# Redis默认情况下有16个分片,这里配置具体使用的分片,默认是0
database: 0
lettuce:
pool:
# 连接池最大连接数(使用负值表示没有限制) 默认 8
max-active: 8
# 连接池最大阻塞等待时间(使用负值表示没有限制) 默认 -1
max-wait: -1
# 连接池中的最大空闲连接 默认 8
max-idle: 8
# 连接池中的最小空闲连接 默认 0
min-idle: 0
//4.封装redis服务类RedisService或者直接使用redisTemplate
@Autowired
private RedisTemplate redisTemplate;
redisTemplate.opsForValue().set(key, value);
//使用RedisService
redisService.setTakeOverTime("key1", "123", 10L);
三.Redis持久化与主从复制(读写分离)
3-1 Redis 的发布(pub)与订阅(sub)
虽然有发布订阅功能,但是不建议用作消息,专做缓存更专业
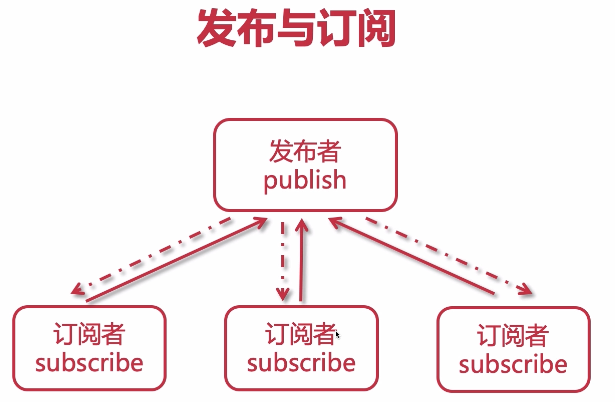
//订阅:执行命令后开始监听chanel
# redic-cli
>subscribe food java bigdata
Reading messages...(press Ctrl-C to quit)
//发布:
# redic-cli
>public food duck
//监听结果: 订阅者收到发布的信息
"message" "food" "duck"
//批量订阅:所有imooc开头的chanel
# redic-cli
>psubscribe imooc*
Reading messages...(press Ctrl-C to quit)
3-2 Redis的持久化机制 - RDB(redis-database)
RDB(redis-database): 每隔特定时间, 内存快照备份-dump.rdb,恢复的时候把快照文件读进内存
优势:
- 全量备份、灾备恢复快、效率高、
- 子进程备份时,主进程不会有写入修改或删除,保证备份数据的完整性
劣势:
- 非实时存在丢少量数据风险、
- 子进程占用内存会和父进程一样,造成CPU负担
RDB的配置
1.保存位置,可以在redis.conf自定义:
dir /usr/local/redis/working
dbfilename dump.rdb
2.保存机制:
save 900 1
save 300 10
save 60 10000
save 10 3
* 如果1个缓存更新,则15分钟后备份
* 如果10个缓存更新,则5分钟后备份
* 如果10000个缓存更新,则1分钟后备份
* 演示:更新3个缓存,10秒后备份
* 演示:备份dump.rdb,删除重启
1.stop-writes-on-bgsave-error
yes:如果save过程出错,则停止写操作
no:可能造成数据不一致
2.rdbcompression
yes:开启rdb压缩模式
no:关闭,会节约cpu损耗,但是文件会大,道理同nginx
3.rdbchecksum
3-3 Redis的持久化机制 - AOF(append-only-file)
- 1.以日志的形式来记录用户请求的写操作。读操作不会记录,写操作才会存存储。
- 2.文件以追加的形式而不是修改的形式。
- 3.redis的aof恢复其实就是把追加的文件从开始到结尾读取执行写操作。
优势
- 1.实时持久化,可以秒级别为单位备份,如发生问题,也只会丢失最后一秒的数据,增加了可靠性和数据完整性
- 2.以log日志形式追加,如磁盘满了,会执行redis-check-aof工具
- 3.数据太大时,redis可以后台自动重写aof。当redis继续把日志追加到老的文件中去时,重写是非常安全的,不会影响客户端作。
- 4.AOF日志包含所有写操作,便于redis的解析恢复。
劣势
- 1.相同的数据,同一份数据,AOF比RDB大,恢复效率低
- 2.针对不同的同步机制,AOF会比RDB慢,因为AOF每秒都会备份做写操作,这样相对与RDB来说就略低。 每秒备份fsync没毛病,但是 的每次写入就做一次备份fsync的话,那么redis的性能就会下降。
AOF配置
# AOF 默认关闭,yes可以开启
appendonly no
# AOF 的文件名
appendfilename "appendonly.aof"
# no:不同步
# everysec:每秒备份,推荐使用
# always:每次操作都会备份,安全并且数据完整,但是慢性能差
appendfsync everysec
# 重写的时候是否要同步,no可以保证数据安全
no-appendfsync-on-rewrite no
# 重写机制:避免文件越来越大,自动优化压缩指令,会fork一个新的进程去完成重写动作,新进程里的内存数据会被重写
# 当前AOF文件的大小是上次AOF大小的100% 并且文件体积达到64m,满足两者则触发重写
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
到底采用RDB还是AOF呢?
1.如果你能接受一段时间的缓存丢失,那么可以使用RDB
2.如果你对实时性的数据比较care,那么就用AOF
3-4 Redis4.0-AOF/RDB混合持久化模式
3-5 Redis 主从复制原理解析
3-6 多虚拟机克隆方案
3-7 搭建Redis主从复制Master-slave(读写分离)
3-8 Redis无磁盘化复制原理解析
3-9 Redis 缓存过期处理与内存淘汰机制
过期删除策略:redis采用的是 定期删除 + 惰性删除策略
- 定期删除:每过段时间(默认100ms)检查一次redis,随机抽取进行检查,删除里面过期键
- 惰性删除:每次取值时检查是否过期,是否需要删除
- 定时删除:用一个定时器来负责监规key,过期则自动删除(内存及时释放,但是十分消耗CPU资源)
采用定期删除+惰性删除就没其他问题了?
不是,如果定期删除没删key,然后也没即时去请求key,也就是说惰性删除也没生效。这样,redis的内存会越来越高。那就应采用内存淘汰机制。
在redis.conf中有一行配置
# maxmemory-policy volatile-lru
内存淘汰回收机制
- 不淘汰
- 1)noeviction:当内存不足以容纳新写入数据时,新写入操作会报错。不回收,应该没人用吧
- 未设置超期: 最近最少使用、随机
- 2)allkeys-lru:当内存不足以容纳新写入数据时,在键空间中,移除最近最少使用的key。推荐使用
- 3)allkeys-random:当内存不足以容纳新写入数据时,在键空间中,随机删除某个key。应该也没人用吧
- 设置超期: 最近最少使用、即将超期、随机
- 4)volatile-lru:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,删除最近最少使用的key。一般是把redis既做缓存,又做持久化存储的时候才用。不推荐
- 5)volatile-random:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,随机删除某个key 不推荐
- 6)volatile-ttl:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,有更早过期时间的key先删除。不推荐
ps:如果没有设置expire的key, 不满足先决条件(prerequisites); 那举volatile-lru, volatile-random 、 volatile-ttl 策略的行为, 和 noeviction(不删除) 基本上一致。
四.Redis 哨兵机制与实现
- 监控、提醒、自动故障转移
- Redis哨兵架构及数据丢失问题分析
4.0 redis哨兵模式-部署
4-1 Redis 的哨兵模式
4-2 Redis 哨兵机制与实现 - 1
4-3 Redis 哨兵机制与实现 - 2
4-4 解决原Master恢复后不同步问题
4-5 图解哨兵
4-6 附:哨兵信息检查
4-7 SpringBoot 集成Redis哨兵 -配置
4-8 redis实现分布式锁
Redis实现分布式锁
Redis分布式锁的Java实现(基于Lua脚本)
五.Redis Custer集群
- 3.0-redis-cluster: Redis Custer数据分布式算法-Hash slot
- twemproxy
- codis
5-1 redis-cluster 5.x集群-环境部署
5-2 搭建Redis的三主三从集群模式
5-3 什么是slot槽节点
5-4 Springboot集成Redis集群
六.Redis缓存雪崩、击穿、穿透、一致性等常见问题与批量查询的优化设计
6-1 缓存穿透的解决方案-布隆过滤器
定义:查一个不存在的key,缓存中无,库中无,所以不会更新到缓存中,每次都会查库
解决方案:
- 布隆过滤器,将所有可能存在的数据哈希到一个足够大的bitmap中,一个一定不存在的数据会被 这个bitmap拦截掉
- 访问key未在DB查询到值,也将空值写入缓存,但可设置较短过期时间
缓存穿透之布隆过滤器
布隆过滤器基本思想
使用布隆过滤器
6-2 缓存雪崩与预防
缓存全失效、过期、缓存服务器故障 -> 导致 请求全查库
解决方案:
- 设置过期时间尽量随机分散,比如过期时间加个随机数
- 缓存reload机制、提前更新缓存
- 后台限流降级、
- 加锁或队列控制读写
- 主从或集群,提供备用缓存服务
6-3 缓存击穿解决方案
数据存在,但在redis中已过期,此时大量并发请求都会从DB加载数据并回设到缓存
解决方案:
- 使用互斥锁(mutex key),在缓存失效的时候(判断拿出来的值为空),不是立即去load db,而是先使用缓存工具的某些带成功操作返回值的操作(比如Redis的SETNX或者Memcache的ADD)去set一个mutex key,当操作返回成功时,再进行load db的操作并回设缓存;否则,就重试get缓存的方法
6-4 缓存一致性问题
先写库再更缓存、或者先更缓存再写库,都可能出现异常导致数据不一致问题
问题:如何保证Redis缓存和数据库的双写一致性
6-5 multiGet 批量查询优化
6-6 pipeline 批量查询优化
问题记录
问:多慢才叫慢?
答:由slowlog-log-slower-than 10000,来指定(单位为微秒)
问:服务器存储多少条慢查询记录
答:由slowlog-max-len 128,来做限制
如果不小心运行了flushall, 立即 shutdown nosave ,关闭服务器 然后 手工编辑aof文件, 去掉文件中的 “flushall ”相关行, 然后开启服务器,就可以导入回原来数据.