分布式消息队列-Kafka
参考资料
- 消息队列MQ
- 消息中间件(一)MQ详解及四大MQ比较
- MQ消息队列详解、四大MQ的优缺点分析
- Kafka学习之路 (一)
- Kafka学习之路 (二)Kafka的架构
- 秒懂 kafka HA(高可用)
- 大白话 kafka 架构原理
一、JMS & 消息中间件
1.1 JMS(JAVA Message Service,java消息服务):
是一个消息服务的标准或者说是规范,允许应用程序组件基于JavaEE平台创建、发送、接收和读取消息。它使分布式通信耦合度更低,消息服务更加可靠以及异步性。
消息中间件(MOM:Message Orient middleware)
JMS用途和优点:
- 1.将数据从一个应用程序传送到另一个应用程序,或者从软件的一个模块传送到另外一个模块;
- 2.负责建立网络通信的通道,进行数据的可靠传送。
- 3.保证数据不重发,不丢失
- 4.能够实现跨平台操作,能够为不同操作系统上的软件集成技工数据传送服务
1.2 MQ:Message Queue,消息队列
是一个消息的接受和转发的容器,可用于消息推送。
顾名思义,它就是一个队列,简单来说就是一个应用程序A将数据丢到一个队列中,由另一个应用程序B从队列中拿到这个数据,再去做一些其他的业务操作。我们把应用程序A叫做生产者,应用程序B叫做消费者,它们之间传输的数据称作消息。
常见MQ组件:
- ActiveMQ: 一款开源的JMS具体实现。由Apache出品的消息中间件,完全支持JMS1.1和J2EE 1.4规范的 JMS Provider实现,非常快速,支持多种语言的客户端和协议。
- RabbitMQ: https://blog.csdn.net/yuanlong122716/category_9754690.html
- RocketMQ:
- Kafka: 是一个分布式、分区的、多副本的、多订阅者,基于zookeeper协调的分布式日志系统(也可以当做MQ系统),常见可以用于web/nginx日志、访问日志,消息服务等等
- ZeroMQ: 号称最快的消息队列系统,尤其针对大吞吐量的需求场景。
1.3 MQ的使用场景
- 应用解耦
假设系统A通过调用接口推送数据给B、C、D,如果后续系统E也需要被推送、或者B不再需要被推送呢?
那我们就需要修改系统A的代码,加上给E推送数据的逻辑,去掉给B推送数据的逻辑。显然A系统和其他系统严重耦合.
在这个场景中,如果使用 MQ,通过发布订阅模型,就可以实现A和其他系统的解耦。A 产生一条数据,发送到 MQ ,哪个系统需要就去订阅消费,如果某个系统不再需要,取消对消息的订阅即可。 - 异步通信
将一些无需即时返回且耗时的操作提取出来,进行了异步处理,而这种异步处理的方式大大的节省了服务器的请求响应时间,从而提高了系统的吞吐量。 - 削峰限流
商城秒杀活动,对于商城系统,可能在0点左右会有个短暂的高峰期,其余时间的并发量也没那么高,假如我们的后台系统直接操作数据库,平时可能没什么问题,但如果突然有很高的的并发量进来,就会因为MySQL并发量过大导致系统瘫痪。
如果使用MQ,请求会短期积压在MQ中,后台系统从MQ中分批拉取消息,从而保证数据库不会被压垮。等高峰期一过,系统就会将MQ中积压的消息慢慢解决掉。这就是MQ的” 削峰限流”作用。
1.4 消息传递模式
-
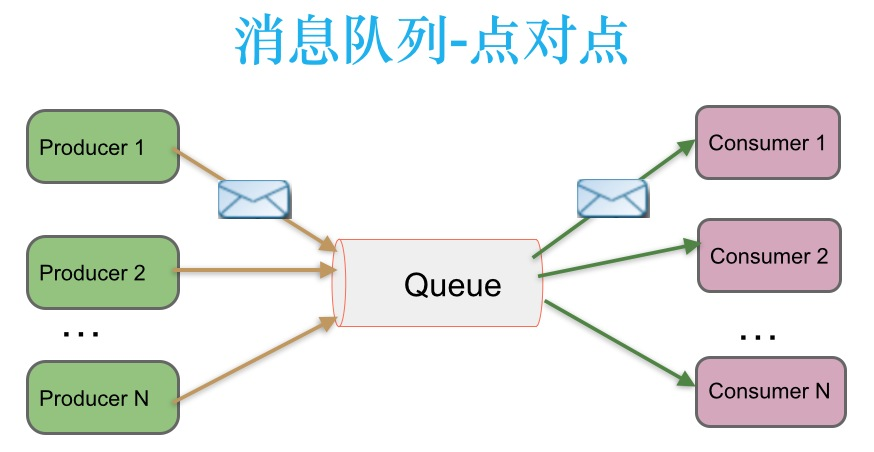
点对点 消息传递模式: 生产者发送一条消息到queue,只有一个消费者能收到。
在点对点消息系统中,消息持久化到一个队列中。一条消息只能被消费一次。当一个消费者消费了队列中的某条数据之后,该条数据则从消息队列中删除。该模式即使有多个消费者同时消费数据,也能保证数据处理的顺序
-
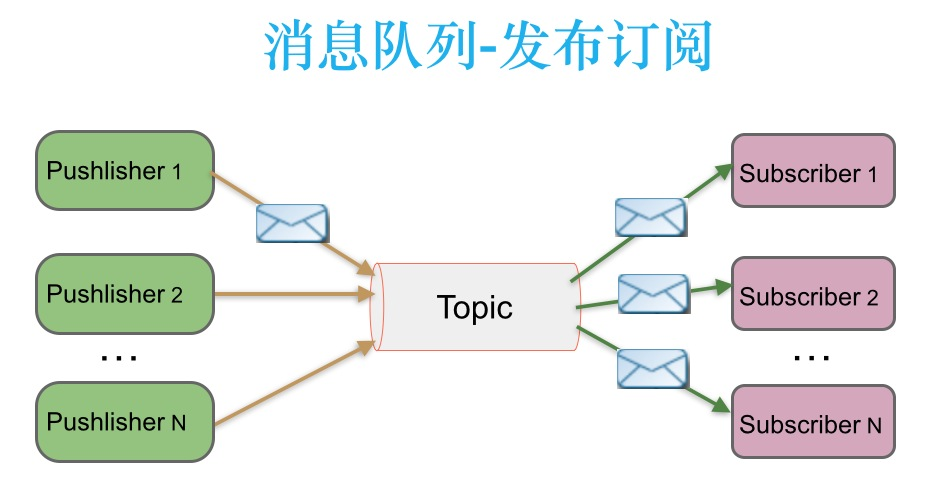
发布-订阅 消息传递模式
在发布-订阅消息系统中,消息被持久化到一个topic中。与点对点消息系统不同的是,消费者可以订阅一个或多个topic,消费者可以消费该topic中所有的数据,同一条数据可以被多个消费者消费,数据被消费后不会立马删除。在发布-订阅消息系统中,消息的生产者称为发布者,消费者称为订阅者
二、Kafka
2.0 Kafka介绍
Kafka是Apache下的一个子项目,是一个高性能、跨语言、分布式发布、发布-订阅 消息队列系统
Kafka相对于ActiveMQ是一个非常轻量级的消息系统.
主要应用场景是:日志收集系统 和 消息系统。
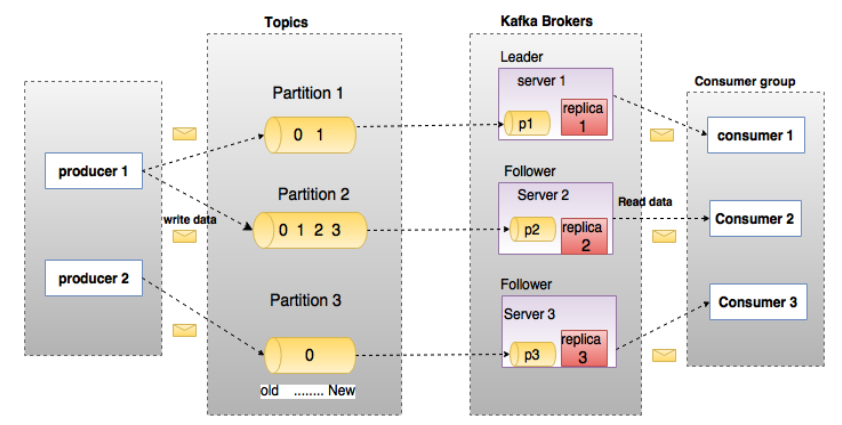
上图中一个topic配置了3个partition。Partition1有两个offset:0和1。Partition2有4个offset。Partition3有1个offset。副本的id和副本所在的机器的id恰好相同。
如果一个topic的副本数为3,那么Kafka将在集群中为每个partition创建3个相同的副本。集群中的每个broker存储一个或多个partition。多个producer和consumer可同时生产和消费数据。
2.1.Kafka的优点
- 应用解耦
- 异步处理
- 消息通信:
- 流量削峰: 秒杀场景
- 冗余(副本):消息队列把数据进行持久化直到它们已经被完全处理
- 可恢复性:加入队列中的消息仍然可以在系统恢复后被处理
- 顺序保证:Kafka保证一个Partition内的消息的有序性,主题topic会有多个分区Partition,所以在整个主题的范围内,是无法保证消息的顺序的,单个分区则可以保证
2.2.Kafka中的术语解释
broker
- Kafka 集群包含一个或多个服务器,服务器节点称为broker
- broker存储topic的数据。
- 如果某topic有N个partition,集群有N个broker,那么每个broker存储该topic的一个partition。
- 如果某topic有N个partition,集群有(N+M)个broker,那么其中有N个broker存储该topic的一个partition,剩下的M个broker不存储该topic的partition数据
- 如果某topic有N个partition,集群中broker数目少于N个,那么一个broker存储该topic的一个或多个partition。在实际生产环境中,尽量避免这种情况的发生,这种情况容易导致Kafka集群数据不均衡。
Topic
- 每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic
- 物理上不同Topic的消息分开存储,逻辑上一个Topic的消息虽然保存于一个或多个broker上但用户只需指定消息的Topic即可生产或消费数据而不必关心数据存于何处
- topic会有多个分区Partition,所以在整个主题的范围内,是无法保证消息的顺序的
Partition
- topic中的数据分割为一个或多个partition。每个topic至少有一个partition
- 每个partition中的数据使用多个segment文件存储
- partition中的数据是有序的,同一topic不同partition间的数据丢失了数据的顺序
- 在需要严格保证消息的消费顺序的场景下,需要将partition数目设为1
Producer
- 生产者即数据的发布者,该角色将消息发布到Kafka的topic中
- broker接收到生产者发送的消息后,broker将该消息追加到当前用于追加数据的segment文件中。
- 生产者发送的消息,存储到一个partition中,生产者也可以指定数据存储的partition。
Consumer
- 消费者可以从broker中读取数据。
- 消费者可以消费多个topic中的数据
Consumer Group
- 每个Consumer属于一个特定的Consumer Group
- 可为每个Consumer指定group name,若不指定group name则属于默认的group
Leader
- 每个partition有多个副本,其中有且仅有一个作为Leader,Leader是当前负责数据的读写的partition
Follower
- Follower跟随Leader,所有写请求都通过Leader路由,数据变更会广播给所有Follower,Follower与Leader保持数据同步。
- 当Follower与Leader挂掉、卡住或者同步太慢,leader会把这个follower从“同步中副本”“in sync replicas”(ISR)列表中删除,重新创建一个Follower。
2.3.kafka安装
2.3.1 windows环境单点安装
2.3.2 Linux环境单点安装
2.3.3 Linux环境集群安装
2.4.Springboot集成使用kafka
//1.添加依赖
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
//2.添加配置
spring:
kafka:
bootstrap-servers: 127.0.0.1:9092 #指定kafka server的地址,集群配多个,中间,逗号隔开
producer:
# Kafka提供的序列化和反序列化类
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
consumer:
group-id: default_consumer_group #群组ID
enable-auto-commit: true
# 提交offset延时(接收到消息后多久提交offset)
auto-commit-interval: 1000
# Kafka提供的序列化和反序列化类
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
listener:
# 消费端监听的topic不存在时,项目启动会报错(关掉)
missing-topics-fatal: false
//3.简单生产者Producer
@RestController
public class ProducerController {
@Resource
private KafkaTemplate<String, Object> kafkaTemplate;
@Autowired
private KafkaTemplate<String, String> kafkaTemplate1;
@RequestMapping("message/send")
public String send(){
//使用kafka模板发送信息,newTopic:topic不存在时会自行创建
kafkaTemplate.send("newTopic", "This is msg");
kafkaTemplate1.send("testDemo","This is msg too");
return "success";
}
}
//4.简单消费者Consumer
@Component
public class Consumer {
/**
* 定义此消费者接收topics = "testDemo"的消息,与producerController中的topic对应上即可
* @param record 变量代表消息本身,可以通过ConsumerRecord<?,?>类型的record变量来打印接收的消息的各种信息
*/
@KafkaListener(topics = "newTopic")
public void listen (ConsumerRecord<?, ?> record){
System.out.printf("topic is %s, offset is %d, value is %s \n", record.topic(), record.offset(), record.value());
}
@KafkaListener(topics = "testDemo")
public void listen2 (ConsumerRecord<?, ?> record){
System.out.printf("topic is %s, offset is %d, value is %s \n", record.topic(), record.offset(), record.value());
}
}
2.5 spring-cloud-stream使用kafka
官方定义 Spring Cloud Stream 是一个构建消息驱动微服务的框架
三、RocketMQ
3.0 RocketMQ介绍
3.1 RocketMQ集群安装部署
四、RabbitMQ
4.0 RabbitMQ介绍
4.1 RabbitMQ集群安装部署
五、问题整理
5.1 消息可靠性
- 消息不丢失
- 消息不会重复消费
- 消息有序消费
5.2 消息防丢失
由于网络问题,我们难保证生产者发送的消息能100%到达消息队列服务器,也就是说有消息丢失的可能性
因此,生产者就必项具有【消息丢失检测】和【重发】机制,也就是我们说的消息队列的亊物机制
同步的事务——停止等待
同步的事务——连续ARQ
异步的事务——回调机制
5.3 消息防重复消费
5.4 消息按序消费
附:常用命令
## 创建topic
bin/kafka-topics.sh --bootstrap-server 127.0.0.1:9092,127.0.0.2:9092,127.0.0.3:9092 --create --topic newTopic --partitions 4 --replication-factor 3
## 查看topic-list
bin/kafka-topics.sh --bootstrap-server 127.0.0.1:9092 --list
## 查看消费group详情
bin/kafka-consumer-groups.sh --bootstrap-server 127.0.0.1:9092 --group new-consumer-group --describe
# 查询消费组
kafka-consumer-groups.sh --bootstrap-server {kafka连接地址} --list
# 删除消费组
kafka-consumer-groups.sh --bootstrap-server {kafka连接地址} --delete --group {消费组}