分布式搜索引擎-ES
参考资料
- https://www.elastic.co/cn/
- Elasticsearch 权威指南(中文版)
- SpringBoot 操作 ElasticSearch 详解
一、ES安装部署
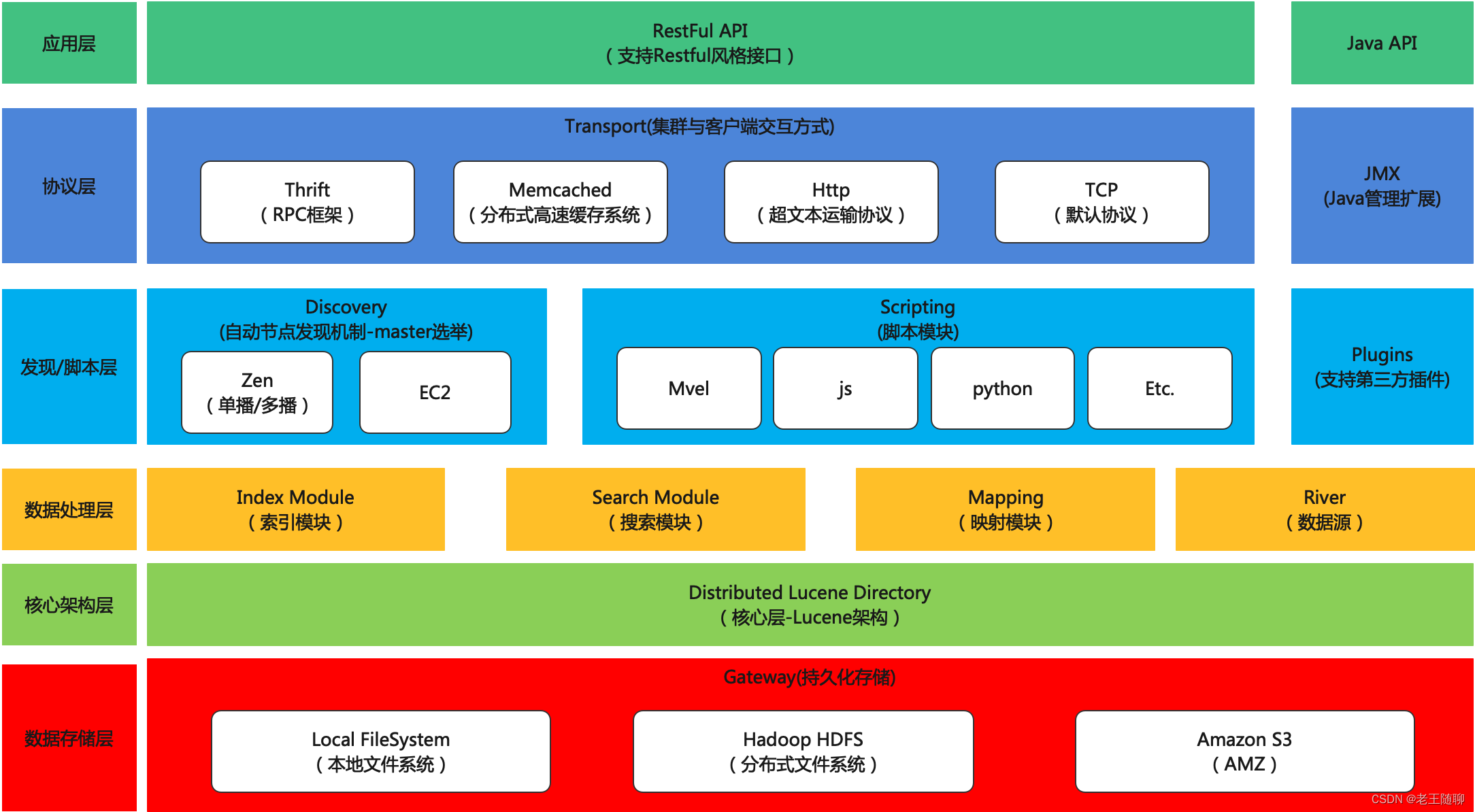
ElasticSearch是一个基于Lucene的搜索服务器。它提供了一 个分布式多用户能力的全文搜索引擎,基于RESTful web接口。
Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。
设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。
架构图:
1.1 win单机部署ES
1.2 linux单机部署ES
1.3 linux集群部署ES
二、Elasticsearch权威指南-学习
2.1 入门
1.Elasticsearch不仅仅是基于Lucene的全文搜索,我们还能这样去描述它:
- 分布式的实时文件存储,每个字段都被索引并可被搜索
- 分布式的实时分析搜索引擎
- 可以扩展到上百台服务器,处理PB级结构化或非结构化数据
2.与Elasticsearch交互
如何与Elasticsearch交互取决于你是否使用Java。 Elasticsearch为Java用户提供了两种内置客户端:
- 节点客户端(node client): 节点客户端以无数据节点(none data node)身份加入集群,换言之,它自己不存储任何数据,但是它知道数据在集群中的具体位置,并且能够直接转发请求到对应的节点上。
- 传输客户端(Transport client): 这个更轻量的传输客户端能够发送请求到远程集群。它自己不加入集群,只简单转发请求给集群中的节点。
两个Java客户端都通过9300端口与集群交互,使用Elasticsearch传输协议(Elasticsearch Transport Protocol) 。集群中的节点之间也通过9300端口进行通信。如果此端口未开放,你的节点将不能组成集群。
3.基于HTTP协议,以JSON为数据交互格式的RESTful API
其他所有程序语言都可以使用RESTful API,通过9200端口的与Elasticsearch进行通信
4.向Elasticsearch发出的请求的组成部分与其它普通的HTTP请求是一样的:
curl -X<VERB> '<PROTOCOL>://<HOST>:<PORT>/<PATH>?<QUERY_STRING>' -d '<BODY>'
VERB HTTP方法:GET, POST, PUT, HEAD, DELETE
PROTOCOL http或者https协议(只有在Elasticsearch前面有https代理的时候可用)
HOST Elasticsearch集群中的任何一个节点的主机名,如果是在本地的节点,那么就叫localhost
PORT Elasticsearch HTTP服务所在的端口,默认为9200
PATH API路径(例如_count将返回集群中文档的数量),PATH可以包含多个组件,例如_cluster/stats或者_nodes/stats/jvm
QUERY_STRING 一些可选的查询请求参数,例如?pretty参数将使请求返回更加美观易读的JSON数据
BODY 一个JSON格式的请求主体(如果请求需要的话)
示例:curl -XGET 'http://localhost:9200/_count?pretty' -d '
{ "query": { "match_all": {} } }
5.返回响应
Elasticsearch返回一个类似200 OK的HTTP状态码和JSON格式的响应主体(除了HEAD请求)。上面的请求会得到如下的JSON格式的响应主体:
6.Elasticsearch是面向文档(document oriented)的
Elasticsearch是面向文档(document oriented)的,这意味着它可以存储整个对象或文档(document)。然而它不仅仅是存储,还会索引(
index)每个文档的内容使之可以被搜索。在Elasticsearch中,你可以对文档(而非成行成列的数据)进行索引、搜索、排序、过滤。这种理解数据的方式与以往完全不同,这也是Elasticsearch能够执行复杂的全文搜索的原因之一。
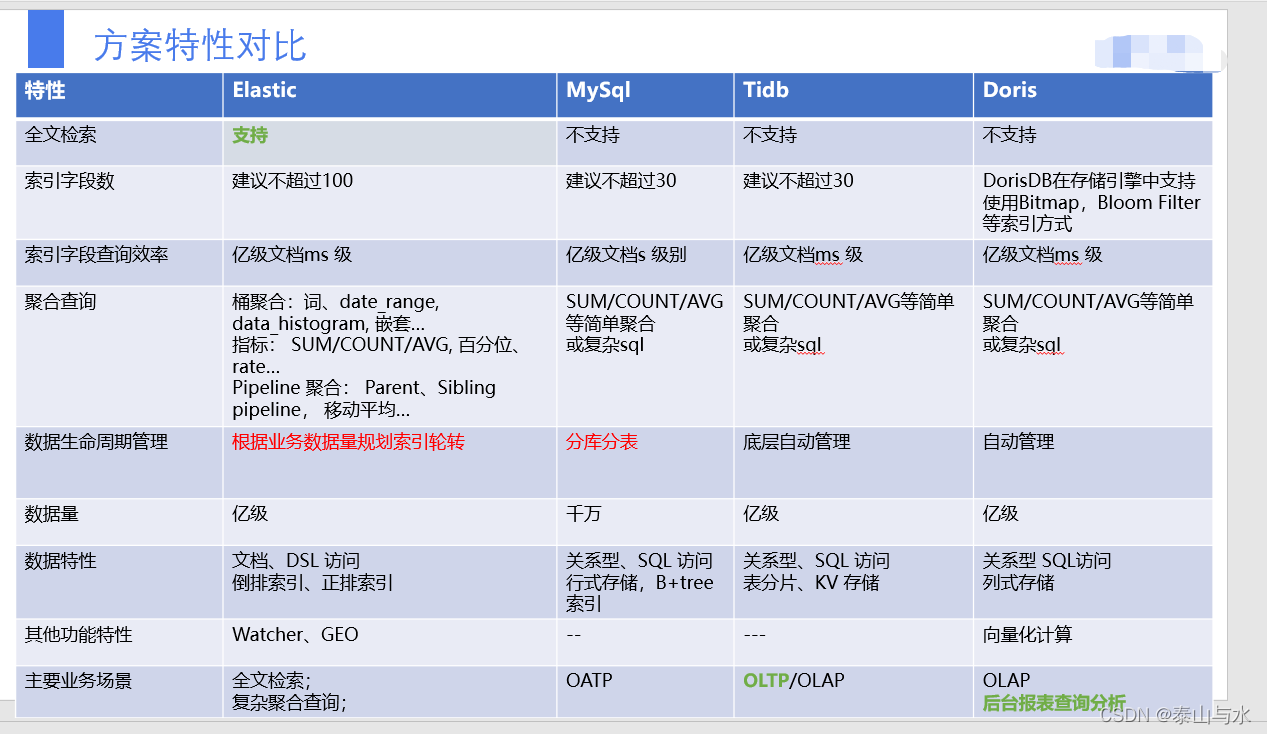
7.对比关系数据库
在Elasticsearch中,文档归属于一种类型(type),而这些类型存在于索引(index)中,我们可以画一些简单的对比图来类比传统关系型数据库:

8.curl方式新建索引,新建type,插入,查询(ID查,条件查,无条件查),删除,修改 记录
9.使用DSL语句查询
查询字符串搜索便于通过命令行完成特定(ad hoc)的搜索,但是它也有局限性(参阅简单搜索章节)。
Elasticsearch提供丰富且灵活的查询语言叫做DSL查询(Query DSL),它允许你构建更加复杂、强大的查询。
DSL(Domain Specific Language特定领域语言)以JSON请求体的形式出现。
10.ID搜索、简单搜索、查询字符串搜索、DSL查询(Query DSL)、过滤器(filter)、全文搜索、短语搜索
11.聚合(aggregations)
Elasticsearch有一个功能叫做聚合(aggregations),它允许你在数据上生成复杂的分析统计。它很像SQL中的GROUP BY但是功能更强大
2.2 分布式集群
1.节点node/集群cluster
一个节点就是一个Elasticsearch实例,而一个集群由一个或多个节点组成,它们具有相同的cluster.name
- 集群:由一个或者多个节点组成,共同持有整个数据,并一起提供索引以搜索功能
- 节点:一个节点是一个集群中的一个服务器
2.主节点(master)
集群中一个节点会被选举为主节点(master),它将临时管理集群级别的一些变更,例如新建或删除索引、增加或移除节点等。主节点不参与文档级别的变更或搜索,任何节点都可以成为主节点
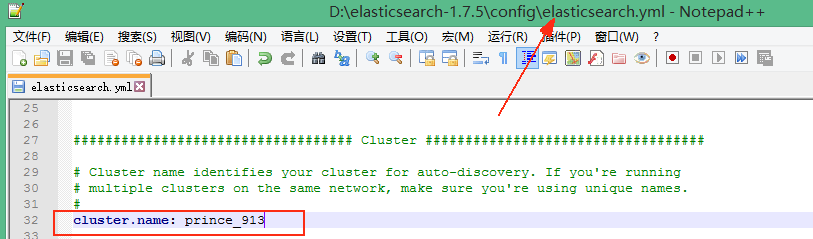
3.修改集群名(默认elasticsearch,集群名相同即在同一集群中,数据共享)
4.集群健康值
- green:一切正常
- yellow:所有的数据都是可用的,某些副本没有被分配
- red:某些数据不可用,集群是部分可用,会造成数据丢失
5.分片和复制
- 分片(shard):将索引划分成多分份的能力,这些份即分片。因为在一个索引可以存储超出单个节点硬件限制的数据。 1) 允许水平分割/扩展容量,2)在分片上进行分布式并发操作,提高性能/吞吐量
- 复制(副本)replicas:创建分片的一份或者多分copy,防止分片或者节点出故障, 1)复制分片和主分片不在同一个节点上.2) 搜索可以在所有的复制上运行,提高了搜索量和吞吐量
ps: 创建一个索引,默认生成5个分片,1个副本
2.3 数据
索引(类似库的概念)和文档类型(表的概念)和文档(记录):
- 文档: 文档是一个可被索引的基础信息单元,json格式{name:“jack”}, 一个索引中可以定义多种文档类型 。
- 文档类型: 是索引的一个上的分类,把具有一组共同字段的文档定义为一个类型
- 索引:是ElasticSearch中存储数据的一种逻辑结构,是拥有几分相似特征的文档的集合, 索引名全部小写
增删改查:
- 搜索数据:curl -XGET http://localhost:9200/wds/employee/1
- 简单搜索数据(默认10条):curl -XGET curl XGET http://localhost:9200/wds/employee/_search
- 条件查询:curl XGET http://localhost:9200/wds/employee/_search?q=last_name:Fir
- 增加数据:curl XPUT http://localhost:9200/wds/employee/1 {…}
- 删除数据:curl -XDELETE http://localhost:9200/wds/employee/1
- 更新数据:curl XPUT http://localhost:9200/wds/employee/1 {…}
- 查询所有
curl -XGET -u user:pwd 'ip:9200/index_name/_search' -H 'Content-Type: application/json' -d '
{
"query": {
"bool": {
"must": {
"match_all": {}
}
}
}
}'
- 条件检索:接口日志分析–查询/hello接口日志,存储在message字段中
curl -XGET -u user:pwd 'ip:9200/index_name/_search' -H 'Content-Type: application/json' -d '
{
"query": {
"multi_match": {
"query": "/hello",
"fields": [
"message"
]
}
}
}'
curl -XGET -u elastic:elastic 'ip:9200/index_name/_search' -H 'Content-Type: application/json' -d '
{
"query": {
"bool": {
"must": [
{
"match_phrase": {
"message": {
"query": "enterprise.demo.com",
"slop": 0,
"zero_terms_query": "NONE",
"boost": 1
}
}
},
{
"range": {
"@timestamp": {
"from": "2022-08-16 17:23:00.002",
"to": "2022-08-16 17:24:00.002",
"include_lower": true,
"include_upper": false,
"time_zone": "+08:00",
"format": "yyyy-MM-dd HH:mm:ss.SSS",
"boost": 1
}
}
}
],
"must_not": [
{
"match_phrase": {
"message": {
"query": "url:/hello1",
"slop": 0,
"zero_terms_query": "NONE",
"boost": 1
}
}
},
{
"match_phrase": {
"message": {
"query": "url:/hello2",
"slop": 0,
"zero_terms_query": "NONE",
"boost": 1
}
}
}
],
"adjust_pure_negative": true,
"boost": 1
}
}
}'
- 删除索引
curl -X DELETE -u user:pwd 'ip:9200/index_name'
- 局部更新
- Mget:(multi-get) 一次请求搜索多个文档
- 批量 :bulk API允许我们使用单一请求来实现多个文档的create、index、update或delete
- https请求查询
curl -k -XGET -u username:pwd 'https://192.168.0.1:9200/indexname/_search' -H 'Content-Type: application/json' -d '
{
"query": {
"bool": {
"must": {
"match_all": {}
}
}
}
}'
2.4 分布式增删改查
- 1.路由
- 2.分片交互
- 3.新建、 索引和删除
- 4.检索
- 5.局部更新
- 6.批量请求
- 7.批量格式
2.5 搜索
- 1.空搜索
- 2.多索引和多类型
- 3.分页
- 4.查询字符串
2.6 映射和分析
- 1.数据类型差异
- 2.确切值对决全文
- 3.倒排索引
- 4.分析
- 5.映射
- 6.复合类型
2.7 结构化查询
1.请求体查询:非简单是查询字符串查询,请求体即花括号形式:{“json”}
2.结构化查询:使用DSL语句查询
3.查询与过滤: 查询与过滤语句非常相似,但是它们由于使用目的不同,
查询是为了找到文档,计算相关性, 过滤的目的就是缩小匹配的文档结果集,所以需要仔细检查过滤条件。
使用查询语句做全文本搜索或其他需要进行相关性评分的时候,剩下的全部用过滤语句
4.重要的查询子句:做精确匹配搜索时,最好用过滤语句,因为过滤语句可以缓存数据。
1).term过滤用于精确匹配哪些值,如数字,日期,布尔值或 not_analyzed的字符串(未经分析的文本数据)
{ "term": { "age":26}} ,{ "term": { "date" : "2014-09-01" }} ,{ "term": { "public": true }} ,{ "term": { "tag": "full_text" }}
2).terms 过滤跟 term 有点类似,但 terms 允许指定多个匹配条件。 如果某个字段指定了多个值
{ "terms": { "tag": [ "search", "full_text", "nosql" ] } }
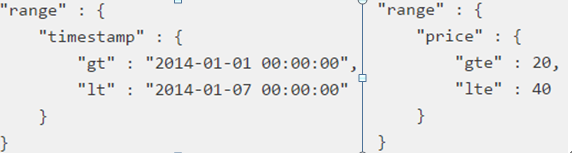
3).range过滤允许我们按照指定范围查找一批数据:
{ "range" : { "age" : { "gte" : 20, "lt" : 30 }}} /gt ::大于, gte: 大于等于, lt : 小于, lte: 小于等于
4).exists 和 missing 过滤可用于查找文档中是否包含指定字段或没有某字段,类似SQL语句中IS_NULL条件
{"exists" : { "field" : "title" }} //这两过滤只针对已经查出一批数据来,但想区分出某个字段是否存在的时使用。
5)bool 过滤可以用来合并多个过滤条件查询结果的布尔逻辑,包含must,must_not,should操作
6).match_all查询 ,可以查询到所有文档,是没有查询条件下的默认语句
{ "match": { "tweet": "About Search" } }
7).match 查询一个全文本字段,它会在真正查询之前用分析器先分析match一下查询字符
8).multi_match查询允许你做match查询的基础上同时搜索多个字段
{ "multi_match": { "query": "full text search", "fields": [ "title", "body" ] } }
9).bool 查询与 bool 过滤相似,用于合并多个查询子句。不同的是,bool 过滤可以直接给出是否匹配成功, 而bool 查询要计算每一个查询子句的 _score (相关性分值)。bool 查询中必须有must或should其一
5.过滤查询:“带过滤的查询”,“查询中的过滤”
2.8 排序
- 1.排序
- 2.字符串排序
- 3.相关性
- 4.字段数据
2.9 分布式搜索
- 1.查询阶段
- 2.取回阶段
- 3.搜索选项
- 4.扫描和滚屏
2.10 索引管理
- 1.创建删除
- 2.设置
- 3.配置分析器
- 4.自定义分析器
- 5.映射
- 6i.根对象
- 7.元数据中的source字段
- 8.元数据中的all字段
- 9.元数据中的ID字段
- 10.动态映射 11.自定义动态映射
- 12.默认映射
- 13.重建索引
- 14.别名
2.11 深入分片
1.使文本可以被搜索 2.动态索引 3.近实时搜索 4.持久化变更 5.合并段
2.12 结构化搜索
- 1.查询准确值
- 2.组合过滤
- 3.查询多个准确值
- 4.包含, 而不是相等
- 5.范围
- 6.处理 Null 值
- 7.缓存
- 8.过滤顺序
2.13 全文搜索
1.匹配查询:match是一个高级查询,主要用于全文搜索, Elasticsearch通过下面的步骤执行match查询
- 1).检查field类型:title字段是一个字符串(analyzed),所以该查询字符串也需要被分析(analyzed)
- 2).分析查询字符串 :查询词QUICK!经过标准分析器的分析后变成单词quick。因为我们只有一个查询词,因此match查询可以以一种低级别term查询的方式执行。
- 3).找到匹配的文档 :term查询在倒排索引中搜索quick,并且返回包含该词的文档。
- 4).为每个文档打分 :term查询综合考虑词频(每篇文档title字段包含quick的次数)、逆文档频率(在全部文档中title字段包含quick的次数)、包含quick的字段长度(长度越短越相关)来计算每篇文档的相关性得分_score。(更多请见相关性介绍)
2.多词查询:通过 “operator”: “and” //或”or” “minimum_should_match”: “75%” //控制精度
3.组合查询:过滤器会判断: 是否应该将文档添加到结果集? 查询还会计算文档的相关性(relevant).布尔查询接受多个用must, must_not, and should的查询子句
4.布尔匹配: 5.增加权重子句: 6.控制分析: 7.关联失效:
2.14 多字段搜索
1.多重查询字符串:bool->should内含多个:match,或者再嵌套bool->should形式,加boost权重
2.单一查询字符串:
3.最佳字段: “dis_max”: {…}
4.最佳字段查询调优:”tie_breaker”: 0.3,tie_breaker的取值范围是0到1之间的浮点数,取0时即为最佳匹配
5.多重匹配查询:multi_match对多个字段执行相同的查询
6.最佳字段、最多字段查询、跨字段查询
multi_match:{
"query" : "jack smith",
"type" : "best_filed", //best_fileds最佳字段查询, most_fields是最多字段查询,cross_fields跨字段匹配查询
"fields" : ["first_name", "last_name"]
}
8.以字段为中心查询
9.全字段查询 :“copy_to”
2.15 模糊匹配
2.16 关系
2.17 嵌套
三、ES实战
3.1 应用场景
ES的主要应用分为两大类:
- 搜索类(带上聚合):考虑事务性,频繁更新,与现有数据库进行同步,通过ES进行查询聚合。
- 日志类
- 日志收集ELK:通过beats等工具收集到kafka等Q中,通过logstash进行转换,输送到ES中,然后通过Kibana进行展示
- 指标性收集:通过fluent-bit收集nginx日志输出到ES,然后进行指标性数据查询分析
3.2 springboot使用ES示例
- SpringBoot使用Elasticsearch之RestHighLevelClient
- SpringBoot-RestHighLevelClient
- 使用https建立es连接-示例如下
// 1.config类
@Configuration
public class RestHighLevelClientConfig {
@Value("${es.user}")
private String user;
@Value("${es.password}")
private String password;
@Value("${es.host}")
private String host ;
@Value("${es.port}")
private int port;
@Bean
public RestHighLevelClient client() {
RestHighLevelClient restClient = null;
try {
final CredentialsProvider credentialsProvider = new BasicCredentialsProvider();
credentialsProvider.setCredentials(AuthScope.ANY,
new UsernamePasswordCredentials(user, password));
SSLContext sslContext = new SSLContextBuilder().loadTrustMaterial(null, new TrustStrategy() {
// 信任所有
@Override
public boolean isTrusted(X509Certificate[] chain, String authType) throws CertificateException {
return true;
}
}).build();
SSLIOSessionStrategy sessionStrategy = new SSLIOSessionStrategy(sslContext, NoopHostnameVerifier.INSTANCE);
restClient = new RestHighLevelClient(
RestClient.builder(
new HttpHost(host, port, "https"))
.setHttpClientConfigCallback(new RestClientBuilder.HttpClientConfigCallback() {
@Override
public HttpAsyncClientBuilder customizeHttpClient(HttpAsyncClientBuilder httpClientBuilder) {
httpClientBuilder.disableAuthCaching();
httpClientBuilder.setSSLStrategy(sessionStrategy);
httpClientBuilder.setDefaultCredentialsProvider(credentialsProvider);
return httpClientBuilder;
}
}));
} catch (Exception e) {
System.out.println(e.getMessage());
}
return restClient;
}
}
//2.查询使用
@Component
@Slf4j
public class ElasticSearchService {
private final String indices = "indexName";
@Autowired
private RestHighLevelClient client;
@Value("${es.rest.page.size:20}")
private Integer pageSize;
public SearchResponse searchApiCallRecords(Scroll scroll) {
// 创建search请求,索引 indexName
SearchRequest searchRequest = new SearchRequest(indices);
// scroll 分页
searchRequest.scroll(scroll);
// 用SearchSourceBuilder来构造查询请求体 ,请仔细查看它的方法,构造各种查询的方法都在这。
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
sourceBuilder.size(pageSize);
//构造QueryBuilder--5分钟内,通过web登录,并且非phone登录127.0.0.1的记录,检索字段 "@timestamp"、"message"的值
LocalDateTime end = LocalDateTime.now();
LocalDateTime start = end.plusMinutes(- 5);
DateTimeFormatter formatter = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss.SSS");
QueryBuilder time = QueryBuilders.rangeQuery("@timestamp").gte(formatter.format(start)).lt(formatter.format(end)).format("yyyy-MM-dd HH:mm:ss.SSS").timeZone("+08:00");
MatchPhraseQueryBuilder host = QueryBuilders.matchPhraseQuery("message", "127.0.0.1");
MatchPhraseQueryBuilder loginWeb = QueryBuilders.matchPhraseQuery("message", "url:/loginWeb");
MatchPhraseQueryBuilder loginPhone = QueryBuilders.matchPhraseQuery("message", "url:/loginPhone");
QueryBuilder queryCriteria = QueryBuilders.boolQuery().must(host).must(loginWeb).must(time).mustNot(loginPhone);
sourceBuilder.query(queryCriteria);
searchRequest.source(sourceBuilder);
SearchResponse response = null;
try {
log.info("开始es查询,查询参数: {}", searchRequest.source());
response = client.search(searchRequest, RequestOptions.DEFAULT);
} catch (IOException e) {
log.error("elasticsearch 请求失败", e);
throw new RuntimeException(e);
}
// 解析结果
return this.checkResponse(response);
}
public SearchResponse scrollApiCallRecords(String scrollId, Scroll scroll) {
SearchScrollRequest searchScrollRequest = new SearchScrollRequest(scrollId);
searchScrollRequest.scroll(scroll);
SearchResponse response = null;
try {
response = client.scroll(searchScrollRequest, RequestOptions.DEFAULT);
} catch (IOException e) {
log.error("elasticsearch 请求失败", e);
throw new RuntimeException(e);
}
return this.checkResponse(response);
}
private SearchResponse checkResponse(SearchResponse response) {
if (RestStatus.OK.equals(response.status())) {
return response;
} else {
log.error("elasticsearch response 解析异常 -- {}", JSON.toJSONString(response));
throw new RuntimeException("elasticsearch response 解析异常");
}
}
}
四、常用DSL
0.搜索所有(.select * )
{
"query": {
"match_all ": {}
}
}
1.匹配查询(分析器分词),select * from t where t.tweet = “elasticsearch”
{
"query": {
"match": {
"tweet": "elasticsearch"
}
}
}
2.精确匹配、多个精确值匹配(select * from t where name=’zhangsan’ and age=20)
term 查询会查找我们指定的精确值,
{
"term": {
"price": 20
}
}
{
"must": [
{
"term": {
"tags": "search"
}
},
{
"term": {
"tag_count": 1
}
}
]
}
3.指定多个可能的匹配条件(一个字段多个值select * from t where fieldA in(1,2,3)):
如搜索tag字段值为 A或B或C的记录
{
"terms": {
"tag": [
"A",
"B",
"C"
]
}
}
4.搜索多个字段(多个字段一个值):
如在title和body字段中搜索 “jack “
{
"multi_match": {
"query": "jack",
"fields": [
"title",
"body"
]
}
}
5.多字符串匹配 :(where fieldA = “A” and fieldB = “B”) (效果同多个term,或者terms)
{
"query": {
"bool": {
"should": [
{
"match": {
"title": "War and Peace"
}
},
{
"match": {
"author": "Leo Tolstoy"
}
},
{
"bool": {
"should": [
{
"match": {
"translator": "Constance Garnett"
}
},
{
"match": {
"translator": "Louise Maude"
}
}
]
}
}
]
}
}
}
6.多词查询 (一个字段包含多个词)

7.短语匹配,(分词,但要求结果包含每个词),效果同6
{
"query": {
"match_phrase": {
"title": "quick brown fox"
}
}
}
8.基于词项的查询、基于全文的查询
- 基于词项的查询 : 如 term 或 fuzzy 这样的底层查询不需要分析阶段,它们对单个词项进行操作。用 term 查询词项
- 基于全文的查询:像 match 或 query_string 这样的查询是高层查询,它们了解字段映射的信息:
9.分页,排序,聚合,取字段
GET _search //查询操作
{
"query" : { //查询
"filtered" : { //过滤
"filter" : {
"bool" : { //合并子查询语句
"must" : [
{ "query" : { "match_phrase" : { "user" : "kimchy" } } } //短语匹配
],
"must_not" : [
{ "term" : { "FIELD" : "VALUE" }},
{ "terms" : { "FIELD" : [ "VALUE1", "VALUE2" ] } }
],
"should": [
{ "term" : { "FIELD" : "VALUE" } },
{ "terms" : { "FIELD" : [ "VALUE1", "VALUE2" ] } }
]
}
}
}
},
"from": 0, //分页起点数
"size": 200, //每页条数
"sort": [ ], //排序
"aggs": { }, //聚合
"_source": {
"include": [ //取哪些字段
"user",
"message"
],
"exclude": [ // 不取的字段
"post_date"
]
}
}
10.控制精度
以下实例查询的是邮件正文中含有“business opportunity”字样的星标邮件或收件箱中正文中含有“business opportunity”字样的非垃圾邮件:
{
"query": {
"filtered": {
"filter": {
"bool": {
"must": {
"match": {
"email": "business opportunity"
}
},
"should": [
{
"match": {
"starred": true
}
},
{
"bool": {
"must": {
"folder": "inbox"
},
"must_not": {
"spam": true
}
}
}
],
"minimum_should_match": 1 //控制精度,指定符合条件数,也可以是百分比
}
}
}
}
}
11.权重boost
{
"should": [
{
"match": {
"content": {
"query": "Elasticsearch", "boost": 3 (2)
}
}
},
{
"match": {
"content": {
"query": "Lucene", "boost": 2 (3) //增加权重
}
}
}
]
}
12.范围 (WHERE price BETWEEN 20 AND 40)、处理null