运维
参考资料
- 运维技能图谱
- 运维知识体系: https://www.unixhot.com/page/ops
- [鸟哥私房菜-基础学习篇]
- [鸟哥私房菜-服务器架设篇]
- [linux就该这么学]
- [kubernetes权威指南]
- [Kubernetes 中文指南/云原生应用架构实战手册]
- prometheus-book
- [SRE Google运维解密]
- Site Reliability Engineering: How Google Runs Production Systems(网站可靠性工程:谷歌如何运行生产系统)
- 一个运维老将的自我修养
- 运维分类:
- 业务/平台/技术运维:主要是面向业务平台SaaS、平台部署维护、业务支撑的、中间件、云原生、大数据;
- 系统/网络/IT运维:负责企业机房、设备、主机资源、网络,操作系统的、底层IaaS的等等;
- 安全运维:负责信息安全(系统安全、网络安全、业务安全、数据安全、认证体系);
- 数据库DBA:是专门负责数据库,如果没有专岗人力,一般由业务运维兼任;
- 运维开发:负责开发DevOps自动化运维工具和平台,如果没有需求规划和能力建设可以没有;
- 名词解释:
- IDC: internet data center 互联网数据中心,简称IDC机房
- 云、CDN、IDC 三个概念 https://www.zhihu.com/question/40534161
- ITIL(Information Technology Infrastructure Library)是一套用于IT服务管理的最佳实践框架
- https://baijiahao.baidu.com/s?id=1761321132249059879&wfr=spider&for=pc
- https://baijiahao.baidu.com/s?id=1744319201231101550&wfr=spider&for=pc
- 蓝绿发布、滚动发布、灰度发布/金丝雀发布、AB Test 对比
教程
- Devops学院
- 云原生/微服务架构/运维 系列课程
- DBA数据库工程师
- Python全能工程师
- 云计算650集:千锋云计算Linux教程650集,linux系统运维从入门到精通教程(Linux安装极速入门,零基础必备)
- Zabbix:【千锋】Zabbix教程(Zabbix监控系统精讲)
- 运维工具:【千锋教育】企业级生产环境CI/CD & K8S & 微服务综合项目实战
- Nginx:千锋linux云计算Nginx教程,一周搞定Nginx(通俗易懂,急速入门)
- Ceph:【千锋云计算】Ceph分布式存储实战(Ceph快速上手)
- Ansible:【千锋云计算】Ansible教程(ansible自动化编程精讲)
- ELK:【千锋云计算】ELK分布式日志处理解决方案(ELK快速上手)
- KVM:【千锋云计算】深入讲解虚拟机化技术原理_ KVM极速入门
- MYSQL:【千锋Linux】MySQL DBA从入门到精通,超详细
- 负载均衡:【千锋云计算】大型网站集群教程(负载均衡由浅入深)
一、规范运维工作流程
1.1 运维工作内容:
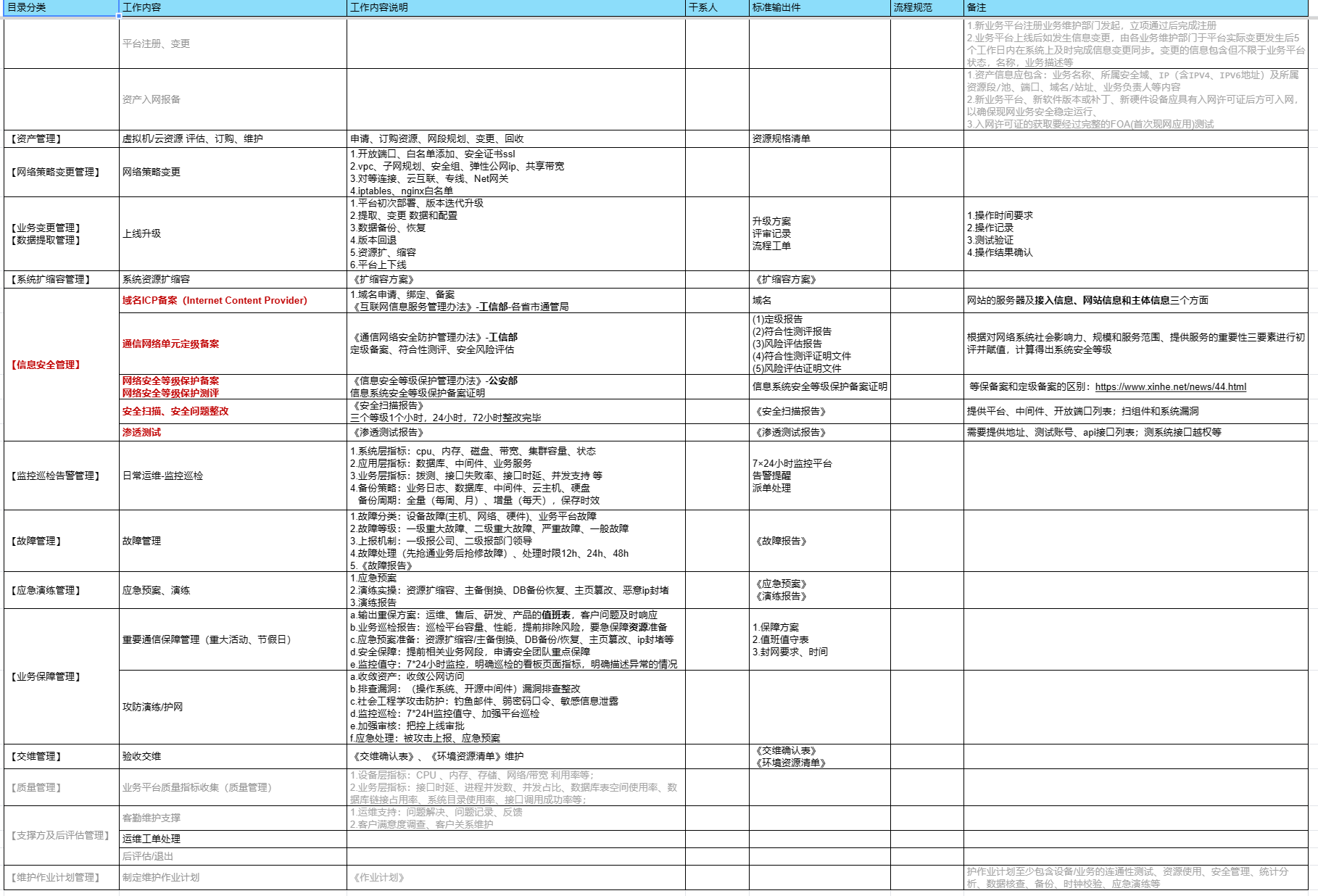
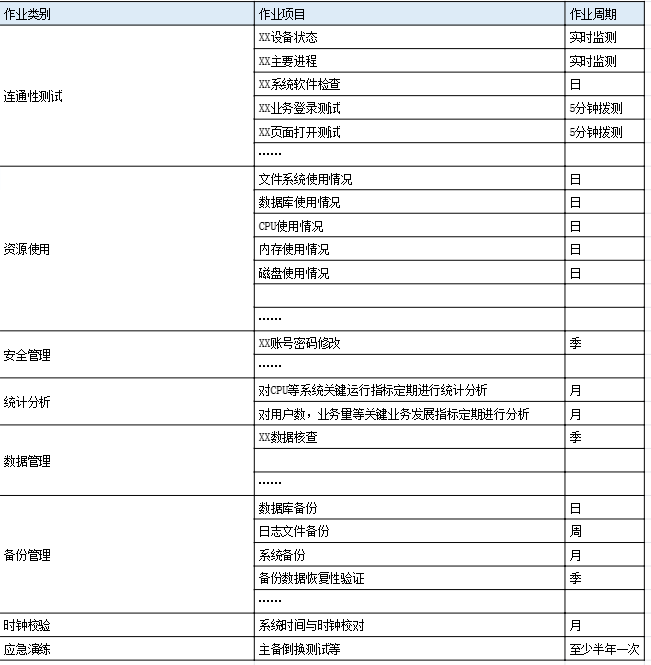
1.2 制定维护作业计划:
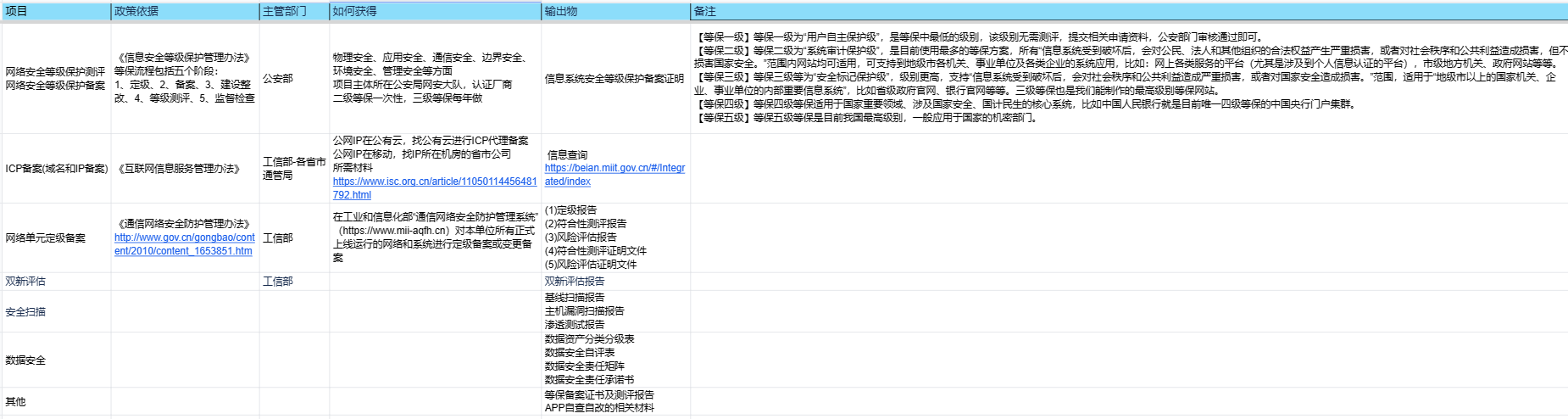
1.3 信息安全梳理:
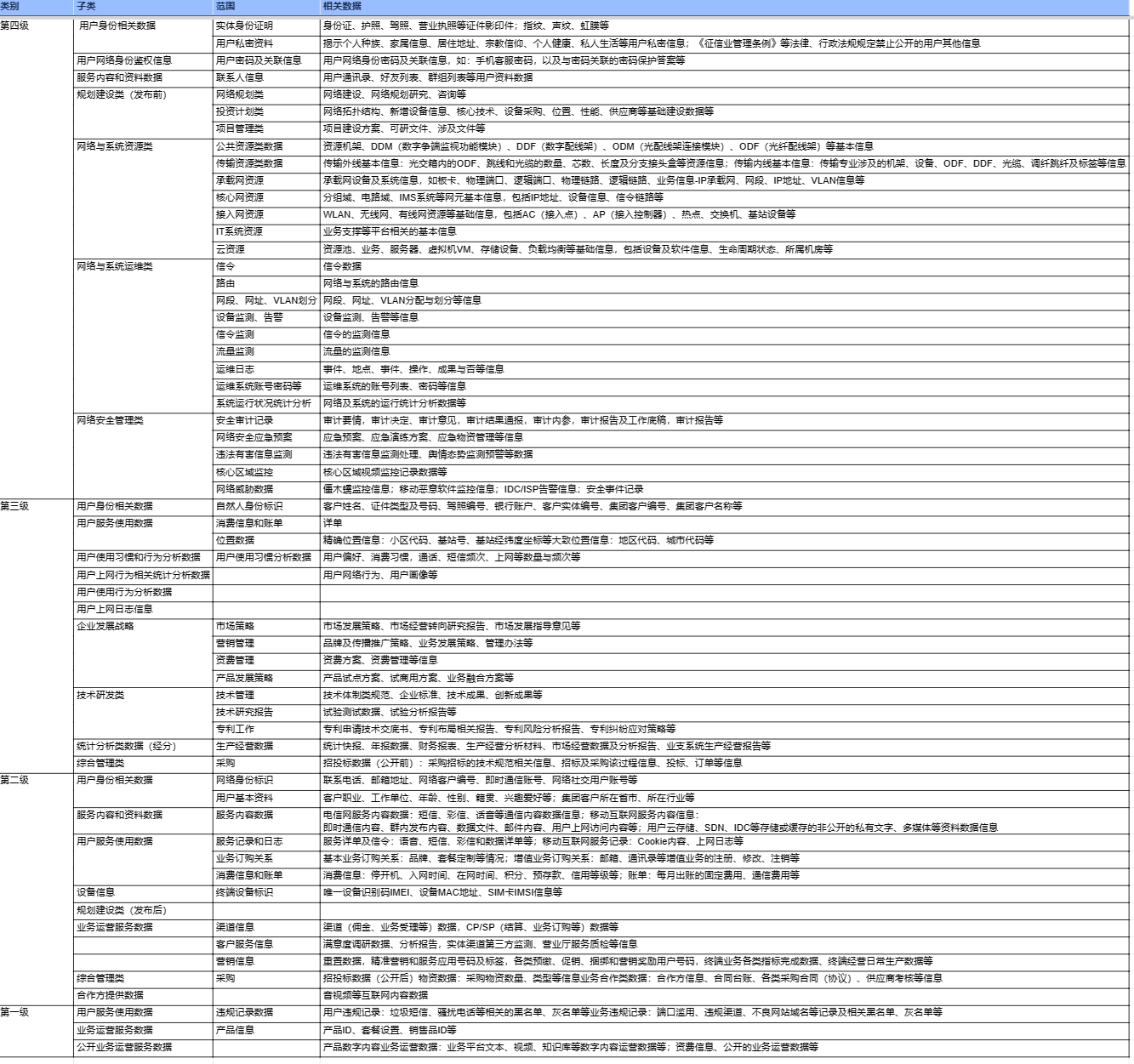
1.4 信息安全-敏感数据分级分类表:
二、运维技术栈
2.0 虚拟化
- Xen:半虚拟化技术,它并不是个真正的虚拟机,而是相当于自己运行了个内核的实例
-
kvm、vmware、workstation、VirtualBox:完全虚拟的、虚拟出网卡、cpu、内存等虚拟硬件,再在其上建立虚拟机,每个虚拟机是个独立的操作系统,拥有自己的系统内核;
OpenStack:是云管理平台,其本身并不提供虚拟化功能,真正的虚拟化能力是由底层的Hypervisor(虚拟机管理系统如KVM、workstation、VirtualBox、Qemu、Xen等)提供。而OpenStack则可以管理KVM虚拟化环境
- docker/containerd、k8s/k3s:容器是利用namespace将文件系统、进程、网络、设备等资源进行隔离,利用cgroup对权限、cpu资源进行限制,最终让容器之间互不影响,容器无法影响宿主机。
2.1 Linux服务器基础
- 用户、权限:sudo、chown、chmod、useradd、ssh、passwd、vi /etc/security/opassd/ …
- 文件管理:ls ll -lh、mkdir、cp、scp、mv、vi、cat、more、grep、awk、sed
- CPU:lscpu、top、
- 内存:扩缩容、free -m、
- 磁盘:分区、格式化、挂载解挂 fdisk、mkfs、mount/unmount、lsblk -f、df -h、du -hd1
- 网络:端口、协议、ipv4、ipv6、ifconfig、ping、netstat、telnet、traceroute、ip addr、network service、ip route
-
ipv4/ipv6同时存在时,浏览器会同时请求,哪个更快响应走哪个协议https://www.zhihu.com/question/631382940/answer/3298945500?utm_id=0
- Linux系统IPv4/IPv6双栈接入优先使用IPv4设置 https://ecloud.10086.cn/op-help-center/doc/article/54326
- 日志:tail、head
- 防火墙iptables:白名单配置
- https://www.cnblogs.com/sunlong88/p/15045321.html
- https://www.vvso.cn/xlbk/5906.html
- https://blog.csdn.net/weixin_40575457/article/details/123315023
- 防火墙firewalld:封堵ip
- 开启firewalld:systemctl start firewalld
- ip封堵:firewall-cmd –permanent –add-rich-rule=’rule family=”ipv4” source address=”192.168.0.1” port protocol=” tcp” port=”8080” reject’
- ip解封:firewall-cmd –permanent –add-source=192.168.0.1
- 请求抓包:tcpdump、wireshark:https://luanpeng.blog.csdn.net/article/details/82991778
- 安装yum install tcpdump -y
- tcpdump -i ifcfg-ens192
- tcpdump -n -i any port 8080
- tcpdump -n -i any port 8080 -w /tmp/tcp.cap 指定输出外部文件,拷到本地用wireshark打开分析
- 安全证书ssl/TLS/https:
- SSL中,公钥、私钥、证书(pem、crt、cer、key、csr)
- HTTPS、SSL、TLS三者之间的联系和区别
- SSL(Secure Socket Layer 安全套接层)是基于HTTPS下的一个协议加密层, SSL是基于HTTP之下TCP之上的一个协议层,是基于HTTP标准并对TCP传输数据时进行加密,HPPTS = HTTP + SSL/TCP的简称
- SSL更新到3.0时进行了标准化, 更名为TLS1.0(Transport Layer Security 安全传输层协议), TLS有1.0 1.1 1.2三个版本默认使用1.0
- TLS该协议由两层组成: TLS 记录协议(TLS Record)和 TLS 握手协议(TLS Handshake)。
- 【OpenSSL】制作自签证书和 HTTPS 配置 https://www.jianshu.com/p/5b3dfe4bb12e
- https://www.cnblogs.com/dirigent/p/15246731.html
- frpc: 内网穿透,基于 fatedier/frp 原版 frp 内网穿透客户端 frpc 的一键安装卸载脚本和 docker 镜像.支持群晖NAS,Linux 服务器和 docker 等多种环境安装部署
- jumpServer…
2.2 shell编程
- 变量:$
- 传递参数:$n
- 数组
- 运算符
- echo命令
- printf命令
- test 命令
- 流程控制【if for while】
- 函数
- 输入/输出重定向【<、>】
- 文件包含
2.3 DBA
- sql脚本:
- sql优化:
- 数据库优化:
- 数据库原理:
- 分库分表:mycat
- 读写分离:mycat + 主从复制实现读写分离
- 主备/主从复制:从库只读,可以实现读高可用
- 双主互备:互为主从,vip+双主互备 实现读写高可用
- 灾备、恢复:
- 【容灾备份】【数据库】PostGresql数据库备份恢复方案 - 【容灾备份】【数据库】mysql数据库备份恢复方案 - 【容灾备份】【数据库】mysql备份工具percona-xtrabackup
- 【同城多AZ(Availability Zone)部署架构】AZ是一个物理资源(计算、存储、网络)的分区(物理机房),同城多中心机房;满足用户跨AZ构建高可用性系统的需求
- 【异地双活架构】
- 数据库监控:
2.4 数据库/存储中间件
- MySql
- 【数据库部署】MySql单机部署
- 【数据库部署】MySql主从&一主多从集群部署
- 【数据库部署】MySql双主架构部署 - 【数据库部署】MHA(MasterHigh Availability)是一套优秀的MySQL高可用环境下故障切换和主从复制的软件
- Mycat
- 【中间件部署】Mycat部署
- Postgresql
- 【数据库部署】PostgreSQL单机部署
- PGPool
- 【数据库部署】PostgreSQL集群 + PGPool部署
- Redis
- 【数据库部署】Redis单机部署
- 【数据库部署】Redis主从部署
- 【数据库部署】Redis哨兵模式
- 【数据库部署】Redis-cluster 5.x集群部署
- Mongodb
- 【数据库部署】MongoDB单机部署
- 【数据库部署】MongoDB 3.4 分片副本集集群部署
- Elasticsearch
- Clickhouse - 【数据库部署】clickhouse分析处理(OLAP)的开源列式数据库部署
- Influxdb
- 【数据库部署】influxdb时序数据库部署
- TDengine
- 【数据库部署】TDengine时序数据库部署
- TiDB - 【数据库部署】一款同时支持在线事务处理与在线分析处理 (Hybrid Transactional and Analytical Processing, HTAP)的融合型分布式数据库产品
- FastDFS
- 【存储部署】FastDFS + Nginx及鉴权部署
- Minio
- 【存储部署】Minio集群部署
- SeaweedFS
- 【存储部署】SeaweedFS部署
- Ftp/Sftp
- 【存储部署】Ftp部署
- 【存储部署】Sftp部署
- Zeekeeper
- 【组件部署】Zeekeeper部署
- Etcd
- MessageQueue
- 【组件部署】Kafka单机部署
- 【组件部署】Kafka + zookeeper集群部署
- 【组件部署】RabbitMQ单机部署
- 【组件部署】RabbitMQ集群部署
- 【组件部署】RocketMQ单机部署
- 【组件部署】RocketMQ双主双从集群部署
- 监控面板 RocketMQ Dashboard
- Apollo
- 【组件部署】Apollo部署
- Telegraf
- 【组件部署】Telegraf基于插件的开源指标采集工具
- Maxwell
- 【组件部署】maxwell部署
2.5 服务器中间件
- JDK
- 【组件部署】jdk安装
- Nginx
- 【组件部署】nginx安装
- Tomcat
- 【组件部署】tomcat安装
- Keepalived
- 【中间件部署】Keepalived安装
- HAProxy
- 【中间件部署】HAProxy
2.6 高可用部署架构
VIP、SLB、LVS:
- 【VIP】虚拟IP:浮动ip, 配合Keepalived实现高可用主从节点切换、不支持负载均衡,vip只绑定在一个节点,故障了才会转移到另一个节点
- 【SLB】服务端负载均衡:后端主机组配置多个ip:port,实现高可用、负载均衡请求分发
- 【LVS】是 Linux Virtual Server 的简称,是一个基于四层网络协议,实现负载均衡的开源软件项目
高可用部署架构:
- 【LVS + HAProxy】 提供高可用性、负载均衡以及基于TCP(第四层)和HTTP(第七层)应用的代理
- 【Keepalived + HAProxy】部署
- 【1VIP + Keepalived + LVS + 2Nginx】 实现负载均衡、高可用部署架构
- 【1VIP + Keepalived + 2Nginx】 实现双机主备-高可用部署架构
- 【2VIP + Keepalived + 2Nginx】 实现双主热备-高可用部署架构
2.6.1 高可用相关理论
SLA(Service Level Agreement)服务等级协议
SLA = MTBF / (MTBF + MTTReco)
| 可用性 | 年故障时间 | 季故障时间 | 月故障时间 |
|---|---|---|---|
| 99.999% | 5.26 min | ||
| 99.995% | 26.28 min | ||
| 99.99% | 52.6 min | ||
| 99.95% | 4.38 hour | ||
| 99.9% | 8.76 hour | ||
| 99.5% | 43.8 hour | ||
| 99% | 87.6 hour |
-
MTTReco(Mean time to recovery)平均恢复时间 该指标是从系统故障中恢复所需的平均时间,这包括从系统出现故障到再次完全正常运行。该指标可用于衡量运维团队的稳定性。 MTTReco = 需要计算时间段的总停机时间 / 故障次数
假设我们的系统在 24 小时内发生了两起单独的故障,停机了 30 分钟。30 除以 2 等于 15,因此我们的 MTTReco 为 15 分钟。 -
MTBF(Mean time between failures)平均故障间隔时间
该指标用于跟踪产品的可用性和可靠性,指标时间数值越大,系统越可靠。MTBF 是衡量可修复系统中故障的指标。 MTBF = 需要计算时间段的总运行时间 / 故障次数
假设评估 24 小时时间段,并且在此时间段中有两个小时的停机时间。我们的总正常运行时间为22小时,除以2,得出 MTBF 为 11 小时。 -
MTTA(Mean time to acknowledge)平均确认时间 该指标是从触发警报到开始处理问题所需的平均时间。此指标可用于跟踪团队的响应能力和警报系统的有效性。 MTTA = 警报和确认之间的总时间 / 故障次数
假设一个月内有 10 次故障,从告警发出到运维确认并开始处理之间总共花费了 40 分钟,那么将 40 除以 10 得出月度的 MTTA 为 4 分钟。 - MTTRepa(Mean time to repair)平均修复时间
-
MTTResp(Mean time to respond)平均响应时间 该指标是从第一次收到故障警报时起,到系统恢复所需的平均时间。
MTTResp = 警报开始到系统再次完全正常运行的完整响应总时间 / 故障次数 - MTTReso(Mean time to resolve)平均解决时间 该指标是完全解决故障所需的平均时间。这不仅包括检测故障、诊断问题和修复问题所花费的时间,还包括出具故障报告,以及确保故障不再发生所花费的时间。 MTTReso = (故障发生到确保故障不再发生花费时间之和 - 系统可用之后非工作时间之和) / 故障次数 假设系统在一次故障中总共宕机了 2 个小时,而团队又在第二天上班后花费 2 个小时来修复以确保系统不会再次发生故障,那么 MTTR 为 4 小时。
2.7 云原生devops
- 容器 dcoker
- 【云原生】Docker安装及使用
- 【云原生】containerd安装及使用
- 镜像 image
- 仓库 registry
- 【云原生】docker-registry搭建私有仓库
- 【云原生】harbor部署和使用
- 容器编排k8s/k3s
- 【云原生】docker-compose安装使用
- 【云原生】Docker Swarm安装使用
- 【云原生】使用 kubeadm 创建 K8S 集群
- 【云原生】使用 kind 创建 K8S 集群
- 【云原生】使用 Kubespray 创建 K8S 集群
- 【云原生】部署Cilium作为CNI插件
- 【云原生】部署flannel作为CNI插件
- 【云原生】k8s集群接入私有镜像仓库
- 【云原生】k3s单点部署
- 【云原生】使用etcd/mysql外置存储部署K3S集群
- 【云原生】k3s集群接入私有镜像仓库
- 【云原生】helm安装使用
- 【云原生】Kubernetes项目TLS证书创建、配置、更新
- 集群服务访问控制Ingress
- 【云原生】Ingress部署和使用
- 集群管理Rancher
- 【云原生】Rancher部署和使用
- CI构建:Gitlab-ci
- 【云原生】GitlabCI基础使用
- CD部署:Argocd
- 【云原生】Argocd部署和使用
- 服务网格:
- service mesh、Istio
- 公有云/私有云:
- 云主机、云硬盘、VPC、子网、VIP、安全组、ACL、安全组规则-白名单、弹性公网IP、弹性负载均衡SLB、Net网关、对等连接、云互联、云端口云专线…
- !!!数量限制!!!(vpc、子网、安全组、acl、对等连接、net网关 规则数量)https://ecloud.10086.cn/op-help-center/doc/article/24852
- 移动云连接打通方式整理:https://docs.qq.com/sheet/DYU9QY2xscG5oYWdF?tab=BB08J2&u=e597bc64d2a64373a0fe689cda0a1278
2.8 CICD
- JDK
- Maven
- Nexus
- Sonar
- Gitlab
- gitlab-ci
- Jenkins
- 云原生CICD:
- 【CICD】00-registry私有镜像仓库
- 【CICD】01-Gitlab-CI持续构建镜像
- 【CICD】02-ArgoCD持续部署到集群
2.9 监控告警
告警系统建设的重要原则:规则随生产故障补充迭代
1.指标收集/监控告警: 【Prometheus + Grafana + exporter + alertManager】 搭建监控平台
- 01 基础设施指标:物理环境下为服务器、存储、网络设备等 基础硬件设施健康状态指标 云环境下为各类云服务的状态指标
- 02 操作系统指标:CPU、内存、磁盘 文件系统及其他标识操作系 统运行状态的指标
- 03 应用程序指标:业务服务JVM堆内存、 Kafka堆积数、Mysql连接数、 Elasticsearch集群状态等应用级指标
- 04 业务进程指标:进程存活、进程CPU占用、进程内存占用、 进程文件打开数等标识进程运行状态的指 标
- 05 对外服务指标:网站响应时间、接口调用状态码、接口调并发支撑 用成功率等直接影响用户体验的指标
- 业务服务日志:用于用户行为分析、程序 bug定位、故障分析
2.Prometheus-Operator:为 Kubernetes 提供了对 Prometheus 机器相关监控组件的本地部署和管理方案,该项目的目的是为了简化和自动化基于 Prometheus 的监控栈配置,
- cadvisor:cadvisor监控Pod ,prmetheus服务发现
3.Thanos是一个开源、高可用、具有长期存储能力的 分布式Prometheus监控方案
4.zabbix:是一个基于WEB界面的提供分布式系统监视以及网络监视功能的企业级的开源解决方案
2.10 日志收集
- 操作系统日志(os):用于安全审计、数据恢复等
- 业务系统运行日志(app):用于问题、异常行为排查
- 中间件日志:负载均衡、数据库、消息队列等中间件日志, 用于性能瓶颈分析、故障定位
日志收集/监控方案:
- 【ELK(ElasticSearch、Logstash、Kibana)】、
- 【EFK(Fluent-bit/Fluentd、kafka、Logstash、ElasticSearch、Kibana)】、
- 【LPG(Loki + Promtail + Grafana)】
2.11 网络
- 网络设备:路由器、交换机、防火墙、负载均衡F5等设备操作
- 网络分类:
- 抓包工具:tcpdump、wireshark:
- 网络协议:ipv4、ipv6、Http、TCP/IP、UDP、ICMP(Internet Control Message Protocol 因特网报文控制协议)SIP…
- 网络排查:traceroute 跟踪数据包到达网络主机所经过的路由工具
- TCP连接及状态分析
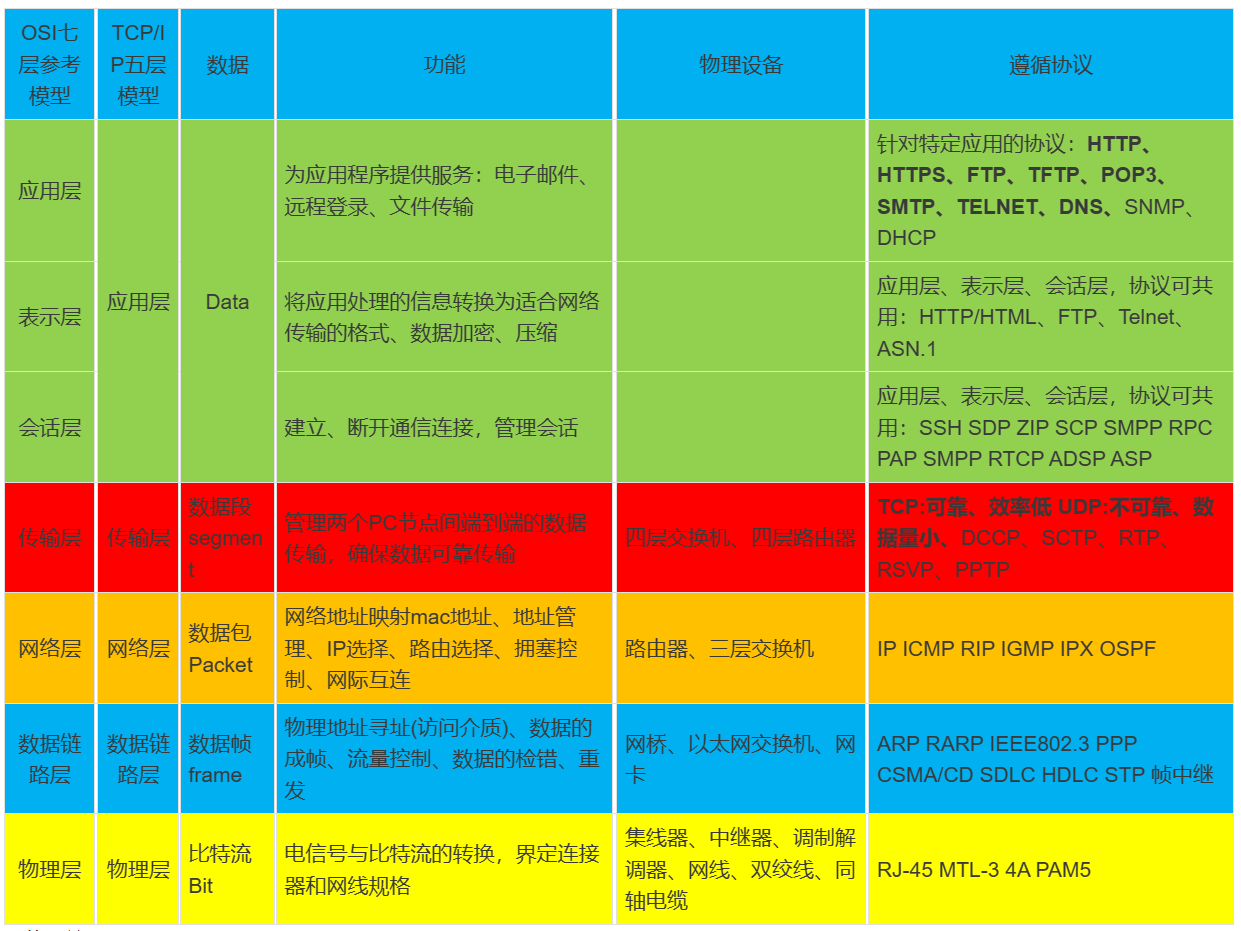
- TCP/IP五层网络:
- OSI七层网络:
- 三次握手:
- 四次挥手:
- 网段(子网)、子网网关、子网掩码
- 寻址、路由
- DNS (Domain Name System) 域名系统,将域名和IP地址相互映射
- 域名申请、购买、配置管理
- NAT(Network Address Translation)网络地址转换,在专用网内部的一些主机本来已经分配到了本地IP地址(即仅在本专用网内使用的专用地址),但又想和因特网上的主机通信(并不需要加密)时,可使用NAT,在专用网(私网IP)连接到因特网(公网IP)的路由器上安装NAT软件。装有NAT软件的路由器叫做NAT路由器
- CDN(Content Delivery Network)即内容分发网络 https://baike.baidu.com/item/%E5%86%85%E5%AE%B9%E5%88%86%E5%8F%91%E7%BD%91%E7%BB%9C/4034265?fr=ge_ala
- SDN(Software Defined Network):https://baijiahao.baidu.com/s?id=1718387409967193011&wfr=spider&for=pc
2.12 信息安全
安全流程要求
- 【主机基线/系统漏洞扫描】
- 【业务端口扫描】
- 端口扫描工具:nmap,
- 漏洞扫描工具:openvas,nessus
- 压力测试工具:LOIC低轨道离子炮,Siege
- DNS伪造:DNSCheF,
- 抓包工具:wireshark
- SQL 注入工具:SQLMap,sql-injection,Pangolin,Bsql hacker,Havij,The Mole
- web目录探测:DirBuster,wwwscan,御剑后台扫描,skipfish,
- 自动化web应用程序安全从测试工具:AWVS即wvs,AppScan,webshag,websecurify,vega
- CSS跨站脚本:Burp Suite,xss shell,XSS Platform,
- CSRF跨站点请求伪造; CSRFTEST
- 暴力破解:Hydra,DirBuster、SNETCracker超级弱口令检查工具
- ARP欺骗攻击:Ettercap,NetFuke
- 拒绝服务攻击:hulk,Scapy
- 漏洞利用工具:号称可以黑出屎的工具Metasploit,w3af
- 密码破解工具:Johnny,hashcat,oclHashcat,chntpw
- 中间人攻击:Driftnet
- web应用代理:ProxyStrike
- 【业务渗透测试】
- 公网映射
- 域名、SSL证书申请
- ip/域名备案
- 定级备案
- 等保测评
- 数据分类分级表
- 系统安全问题检查点
其他工具
- rootkit:Rootkits是linux/unix获取root权限之后使得攻击者可以隐藏自己的踪迹和保留root访问权限的神器,通常攻击者使用 rootkit的检查系统查看是否有其他的用户登录
- fail2ban: 一款安全保护工具,触发限制后会创建防火墙规则封锁IP,诸如对ssh暴力破解、ftp/http密码穷举等场景提供强有力的保护
- ddos-defalte:是一款免费的用来防御和减轻DDoS攻击。它通过netstat监测跟踪创建大量网络连接的IP地址,在检测到某个结点超过预设的限制时,该程序会通过APF或iptables禁止或阻挡这些IP
2.13 大数据
2.14 自动化运维DevOps
- saltstack(c/s架构自动化运维工具)——介绍、安装、部署+远程执行
- 【保姆级教程】自动化运维工具saltstack介绍、安装、使用 https://zhuanlan.zhihu.com/p/433968130
- http://docs.saltstack.cn/
- puppet:是一个c/s架构IT基础设施自动化管理工具
- ansible: 自动化运维工具,基于Python开发,集合了众多运维工具(puppet、cfengine、chef、func、fabric)的优点,实现了批量系统配置、批量程序部署、批量运行命令等功能。Ansible架构相对比较简单,仅需通过SSH连接客户机执行任务即可
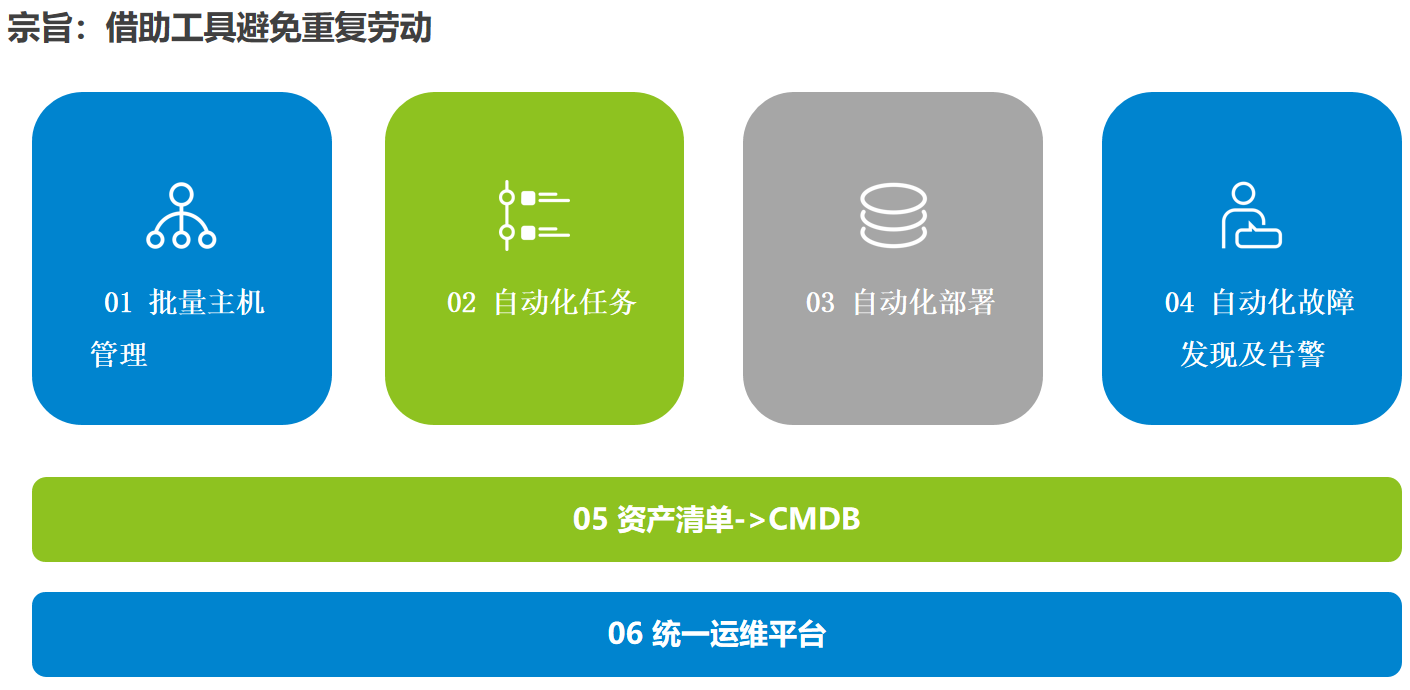
2.13.1 批量主机管理
自动化工具选型:Ansible, 通过ansible批量下发执行操作命令
示例:
- 某系统与4A平台对接,需为系统内200台主机添加一条路由,打通与4A平台之间的网络
- 对某云资源池内的所有500台主机安装云安全中心agent
2.13.2 自动化任务
自动化工具选型:Crontab + Python
示例:
- 每天、每月上传数据文件至ftp服务
- 使用移动云提供的SDK及API调用示例,稍作修改,形成自动化添加安全组任务脚本
2.13.3 自动化部署
自动化工具选型:
- ansible批量下发执行命令脚本k3s-install.sh、
- ansible playbook编排
- CICD工具
2.13.4 自动化故障发现及告警
工具链推荐:Prometheus + Grafana
- 可观测性体系
- 链路追踪
- 日志指标
- 可观测性体系
- 解决方案:Grafana全家桶
- Tempo
- Loki
- Mimir
- 其他推荐
- 可观测新标准:https://opentelemetry.io/
- 新型可观测平台:https://signoz.io/
- 可观测套件:https://github.com/observatorium/observatorium
2.13.5 资产清单【CMDB( Configuration Management Database)】-一切运维体系工作的基石
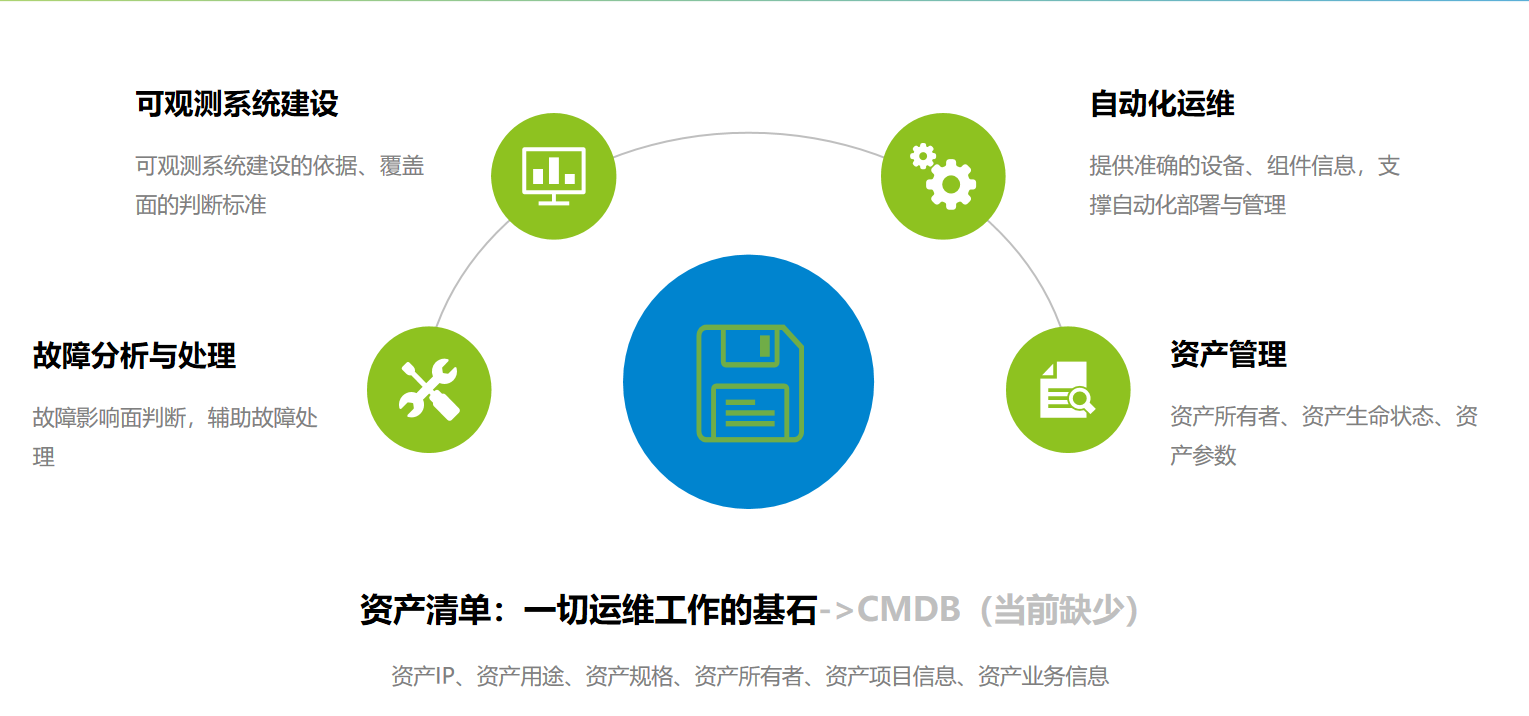
“CMDB 即配置管理数据库,通过获取、维护,检查企业的IT基础设施资源,从而高效控制与管理不断变化的 IT 基础架构与 IT 服务,并为其它系统,例如任务调度、运维工单、发布管理等系统提供准确的配置信息。”
2.13.6 统一运维平台
运维平台:自动化运维能力集成
推荐体验:腾讯蓝鲸智云 https://bk.tencent.com/
2.15 智能化运维AIOps
智能运维(AIOps,Artificial Intelligence for IT Operations)是高德纳咨询公司于2016年提出的一个概念, 指通过机器学习,自动地从海量运维数据(包括日志、业务数据、系统数据等)中进行实时或离线分析,加强IT运营分析能力。AIOps主要涉及两个方面:机器学习和大数据。
智能运维是基于人工智能 + 大数据 + 自动化三大核心技术,为企业提供智能、高效、可 靠的运维支持
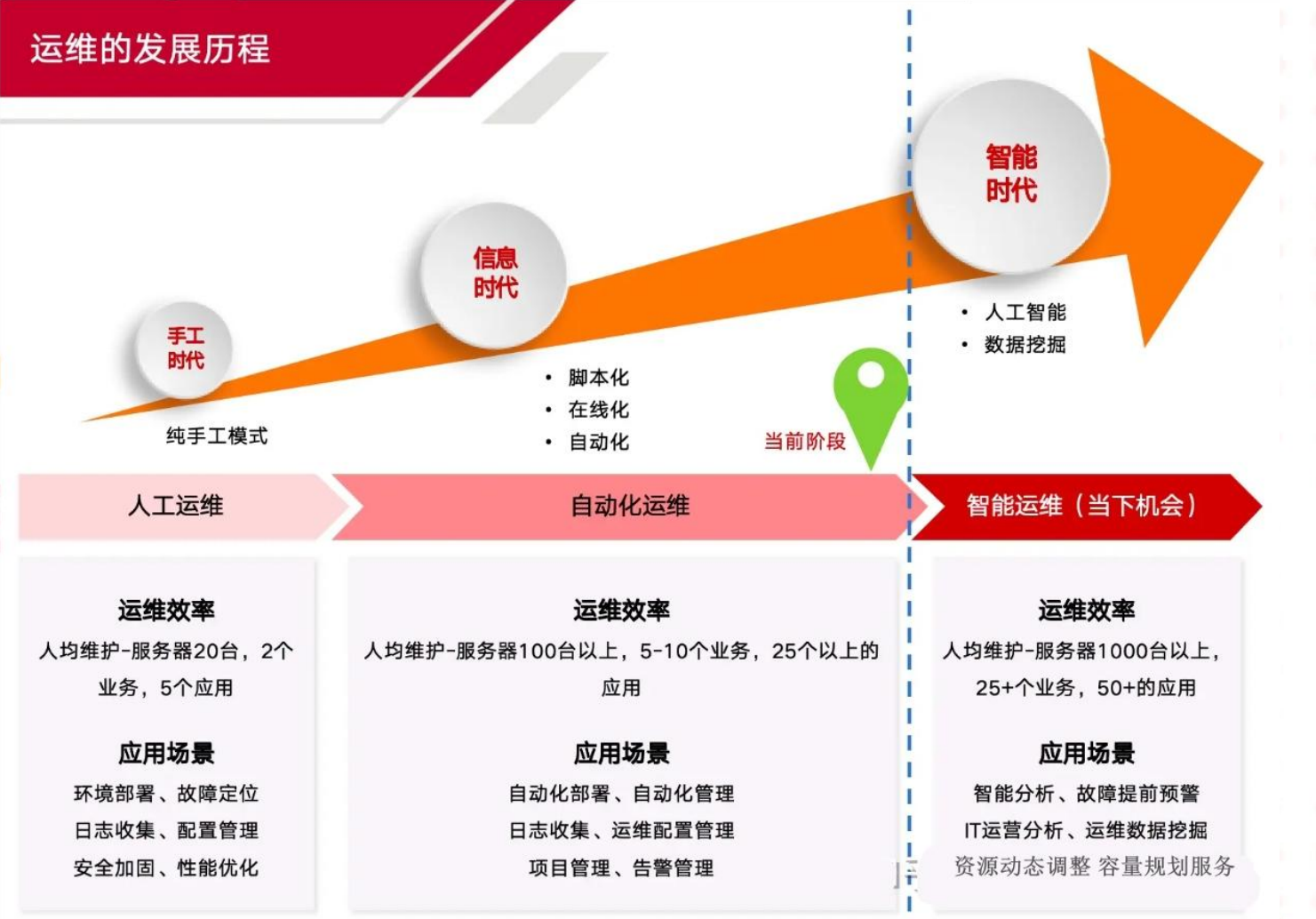
智能运维核心能力
- 数据采集与处理能力
- 监控预警能力
- 自动化运维能力
- 分析与预测能力
- 人工智能和机器学习能力
- 标准化和规范化能力
- 安全性与可靠性能力
解决核心问题
- 智能监控与告警
- 自动化部署与升级
- 智能分析与优化
- 智能故障排除与恢复
- 智能容量规划与扩展
- 智能安全与合规管理
- 智能日志分析与诊断
- 智能云资源管理
智能运维建设路径
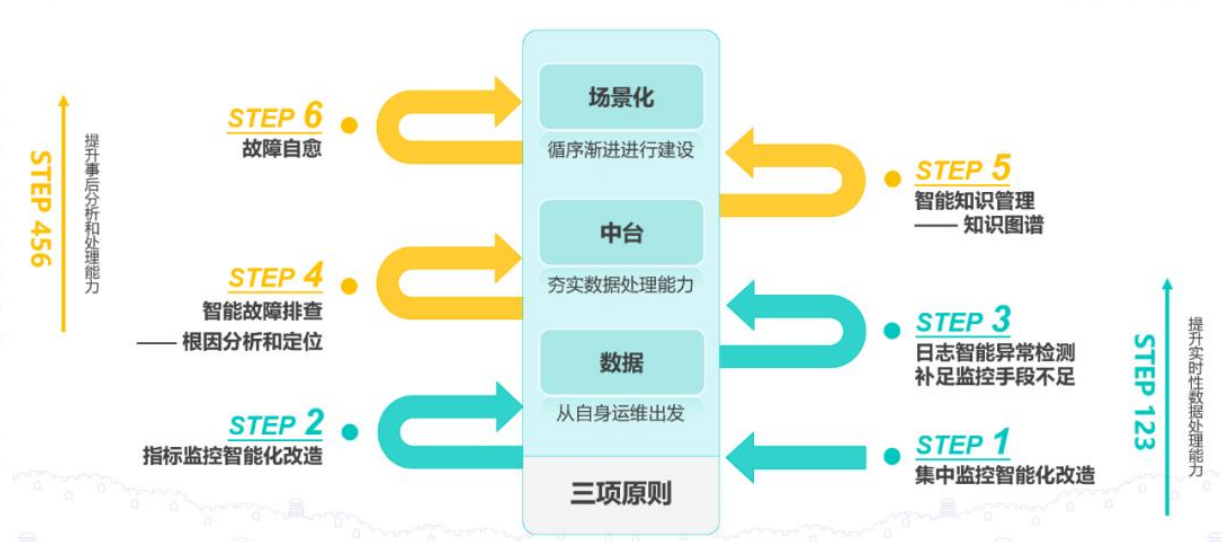
智能运维架构
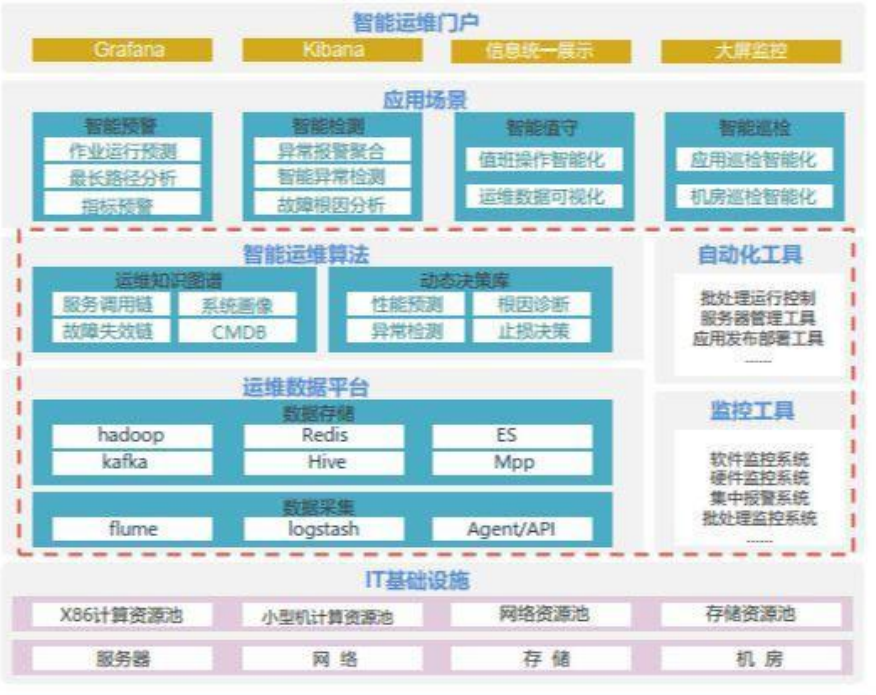
2.16 python脚本语言
- Django:是一个开源的Web应用框架,由Python写成。采用了MTV的框架模式,即模型M,模版T、视图V
- DRF: Django REST Framework框架是是建立在Django框架基础之上,用于构建Web API的工具
JD
岗位描述1:运维工程师
1、负责业务系统的日常运维、割接升级、突发异常的应急响应和处理工作;
2、负责业务系统的运行状况和性能监控,及时发现隐患和容量瓶颈,并推动优化,提供业务系统的健壮性和服务时效;
3、参与运维规范的制定和落地实施;
4、参与自动化运维、智能化运维的开发,实现运维全流程自动化,缩短运维响应时间,减低运维成本;
5、参与中间件技术、数据库技术调优,制定优化规范。
任职条件
学历:全日制大学本科及以上学历,计算机、通信等相关专业。
知识:
1、熟悉ITIL相关理论,对运维流程的管理有自己的理解和实践经验;
2、熟悉常用开源组件如Nginx/Redis/MinIO等组件的运维;
3、熟练使用TiDB数据库;
4、熟练使用开源监控工具,如Prometheus、Zabbix等;
5、掌握Shell/Python/Golang/Java中一到两种语言。
技能:具有较强的逻辑分析能力和文字表达能力,沟通协调能力佳,具有较强的综合分析问题及推动解决问题的能力。
经验:
1、具有3年及以上业务系统运维经验,有大型互联网业务系统运维经验;
2、对开源组件源码有研究者优先;
3、对TiDB数据库有一定调优经验者优先;
4、搭建过完整的监控体系者优先。
其他: 工作严谨细致,学习能力强。
岗位描述2:运维工程师
1、负责云资源池割接变更、故障处置、重大保障、日常作业等运维工作;
2、负责云资源池运维管理工作,统筹构建云资源池运维管理体系,明确部门相关运维质量管理流程、指标体系、规范制度;
3、负责运维创新工作,牵头梳理各类运维工具需求,开展容量预测、故障自愈、智能排障等运维新技术落地试点工作,推动云资源池运维工作向自动化、智能化方向演进。
任职条件
学历:全日制大学本科及以上学历,通信工程、网络工程、计算机等相关理工科专业。
知识:
熟悉网络基本概念及计算机网络系统工作知识,
熟悉TCP/IP协议、OSI模型,
熟悉路由器、交换机、防火墙、负载均衡等设备操作,
熟悉网络安全、网络虚拟化、SDN、openstack等技术知识。
技能:具备一定文字功底,英语四级及以上,可熟练使用办公软件。
经验:
1、3年及以上相关工作经验;
2、具有大型数据中心网络的规划、设计、建设、维护管理经验优先;
3、具备网络自动化开发经验优先,有运维相关专利、软著、论文、QC等创新经验优先。
其他: 诚实可信,有高度的工作热情、自信心、责任心、进取心,具备良好的服务意识、团队合作精神,具备良好的沟通、协调和应变能力,有一定抗压能力
岗位描述3: 运维(开发)专家/工程师/专员
参与平台产品7*24小时运维,负责业务发布、割接及在线故障处理;
参与产品业务架构设计及优化,辅助研发、测试实施运维工作;
参与公司devops相关项目研发、测试及维护;
岗位要求
# 计算机或相关专业本科及以上学历(985,211工程类院校优先)
# 具备数据结构及算法基础知识,对软件设计、架构、开发、测试、运维全栈流程有一定认识,具备一定实战经验;
# 了解HTML、HTML DOM、CSS等前端基本知识,能够使用Javascript,Jquery,Vue等完成前端开发工作者优先;
# 了解微服务常用组件及架构(dubbo,spring cloud,brpc,grpc等),了解service mesh基本原理,具备一定实操经验者优先;
熟悉linux系统及常用命令,具备配置、优化及故障排查能力;
熟悉TCP/IP、Http协议,了解TCP/IP四层网络或OSI七层网络,具备常用网络故障排查能力;
熟悉互联网常用中间件的配置、优化及使用,具备故障排查能力(nginx、zookeeper、redis、kafka、tomcat、mongodb、mysql、es等);
熟悉运维常用配置管理、监控工具,具备工具配置、编写及故障排查能力(prometheus,grafana,zabbix,nagios,elk,jenkins,ansible,saltstack、Puppet等);
熟悉一项或多项脚本语言编程,如python,shell,ruby等,能够熟练使用python者优先,具备Django,DRF等框架或socket编程实战经验者优先;
了解docker基本原理、docker file的编写及容器使用,了解k8s框架及容器编排,具备一定实操经验者优先;
了解mysql数据库基本配置及使用,具备一定sql编写能力;
了解互联网常用负载均衡方案(F5,lvs,nginx,haproxy等),具备实操经验者优先;